数据导入与预处理实验一—KETTLE数据处理
一、实验概述:
【实验目的】
- 了解和掌握数据库恢复,变换,数据统计与可视化的方法;
- 掌握Json数据集的API下载方法,数据提取及导入其他数据结构的方法
- 掌握不同数据格式之间的转换方法;
【实施环境】(使用的材料、设备、软件) Linux或Windows操作系统环境,MySql数据库,Mysql workbench
或Navicat。
二、实验内容 第1题 安然(Enron)电子邮件数据集的恢复与查询
【实验要求】
- 安装MySql数据库以及客户端(mysql workbench或Navicat);
- 下载安然电子邮件数据集;
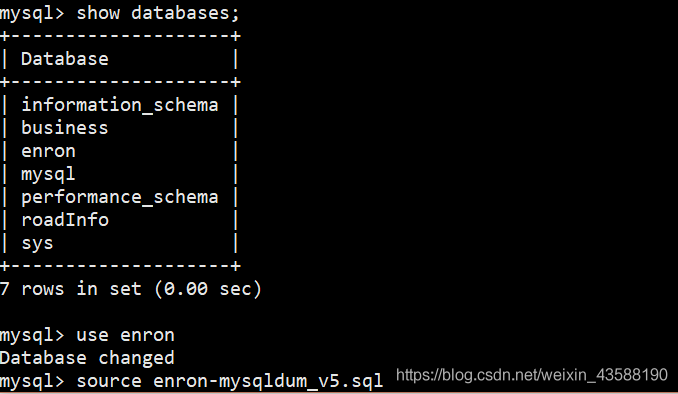
- 在Mysql中恢复Enron数据库并对其查询。
- 采用编程方式导出数据。
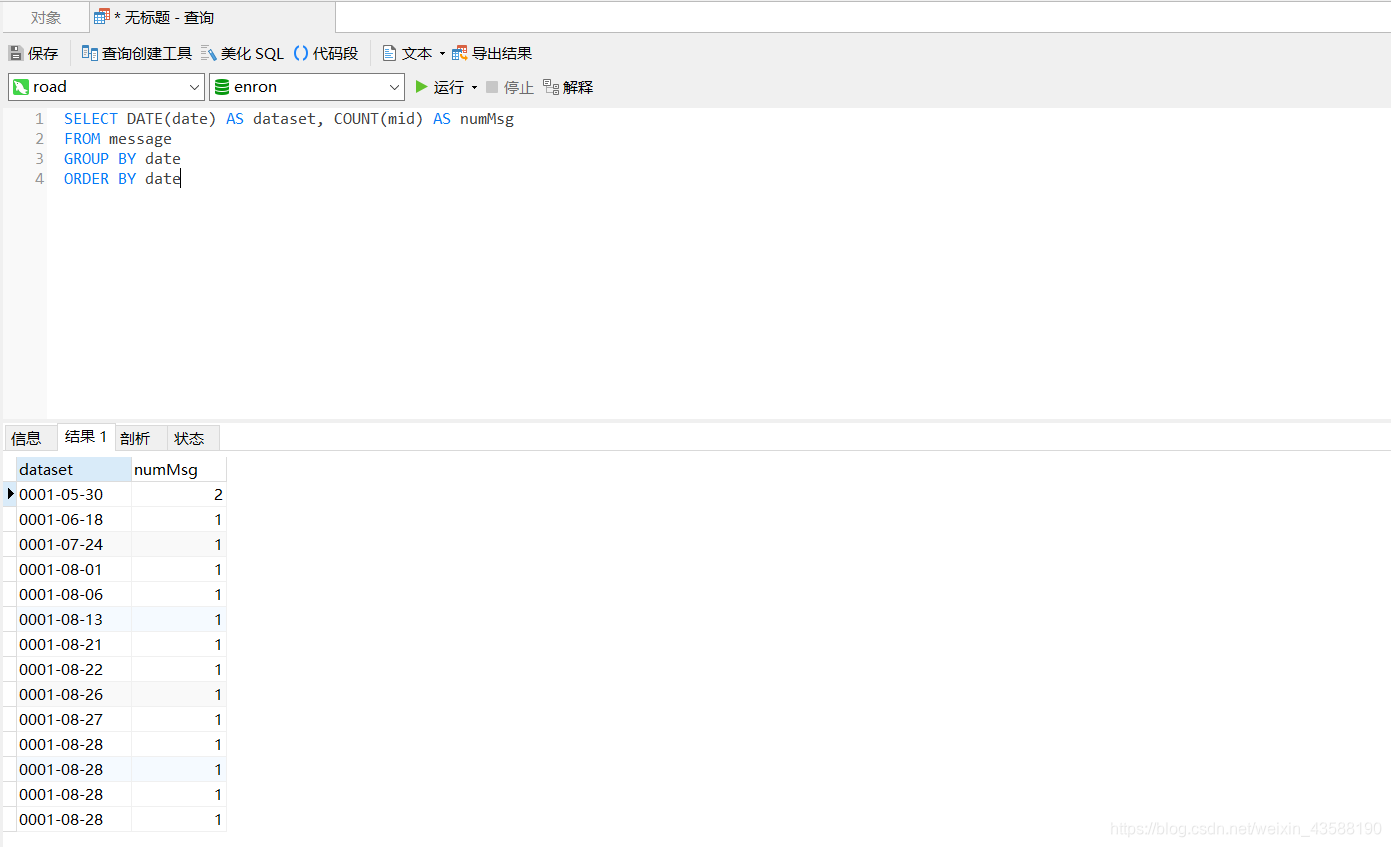
- 统计每一天的邮件发送量,选用任一可视化工具进行可视化。
1.下载数据集并安装kettle
数据集sql地址:https://pan.baidu.com/s/1oBIBzc6EGpi0p5hcZJHfTg
提取码:gbvv
kettle地址:https://pan.baidu.com/s/1c5VOfOOpa1B8S-y7tmkfRQ
提取码:96ok
2.在MySQL中恢复数据集并查询
3.编程导出数据到excel
import pymysql
import xlsxwriter
import datetime
import time
#链接database
connection = pymysql.connect(host="39.103.152.***",user="root",password="***",database="enron",charset="utf8")
#创建可执行sql语句的游标
cursor = connection.cursor()
#查询
sql = 'select * from employeelist'
#执行
count = cursor.execute(sql)
#获取全部结果
result = cursor.fetchall()
#print(result[0])
#获取MySQL中的数据字段名称
fields = cursor.description
#创建一个excel
workBook1 = xlsxwriter.Workbook('./enron_employeelist.xlsx')
#创建一个sheet
workSheet = workBook1.add_worksheet('sheet1')
# 写上字段信息
for field in range(0,len(fields)):
workSheet.write(0,field,fields[field][0])
# 获取并写入数据段信息
row = 1
col = 0
for row in range(1,len(result)+1):
for col in range(0,len(fields)):
workSheet.write(row,col,u'%s'%result[row-1][col])
print('正在保存第'+str(row)+'行第'+str(col)+'列信息')
workBook1.close()

4.下载kettle驱动并放到kettle\data-integration\lib文件夹下
下载地址:https://dev.mysql.com/downloads/file/?id=468318%20
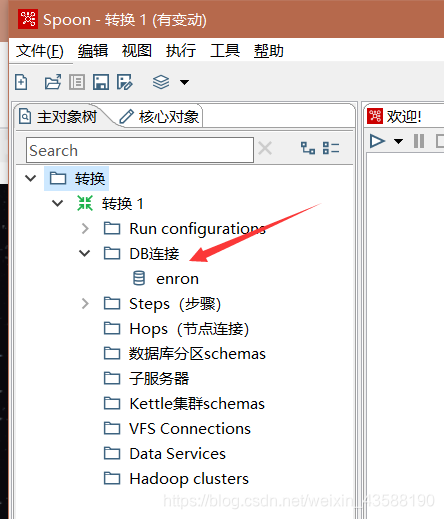
新建DB链接

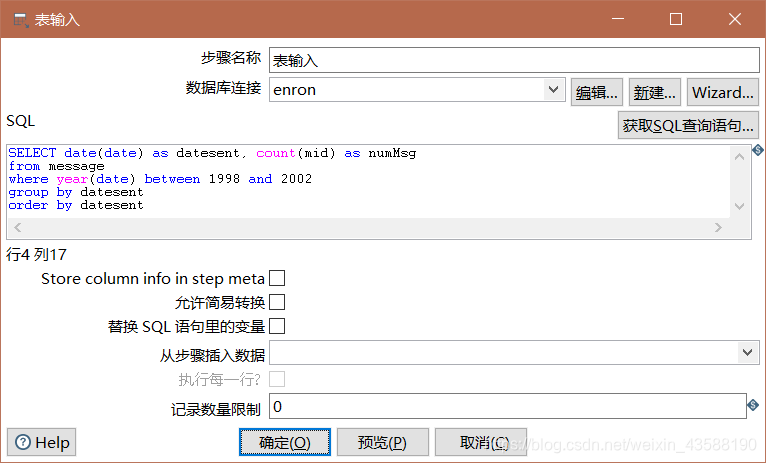
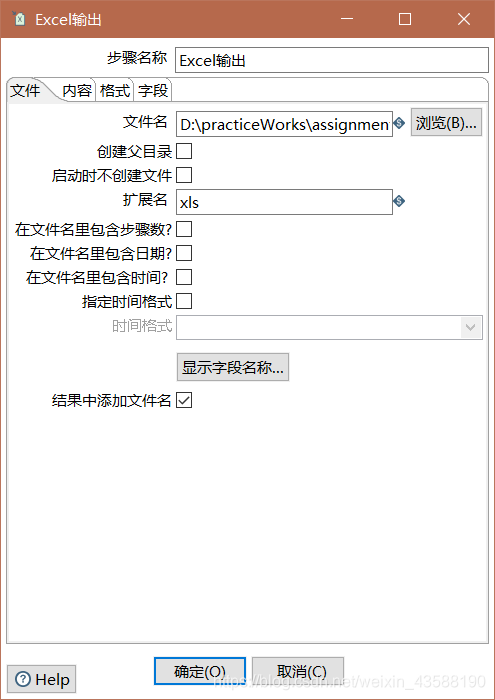
按住shift拖动箭头从表输入到Excel输出,然后点击执行
成功输出到excel
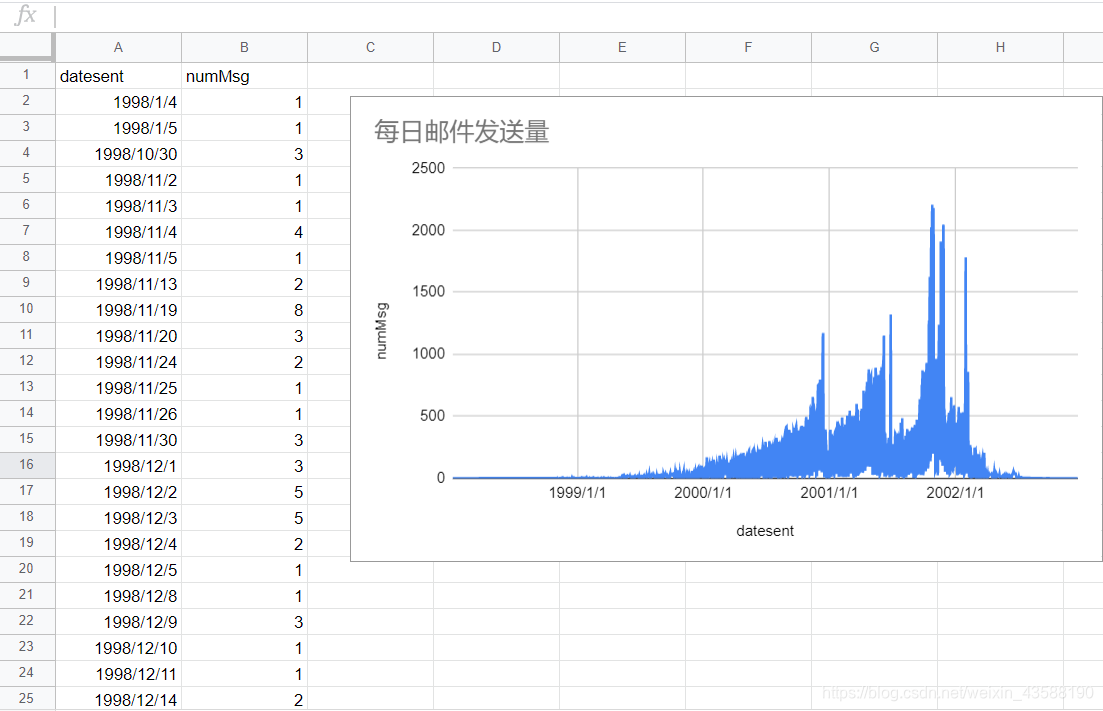
5.使用google的spreadsheets工具可视化上述数据
spreadsheets地址: http://www.google.cn/intl/zh_cn/sheets/about/
第2题 解析安然(Enron)数据库中message表日期并转换成字符串
【实验要求】
- 解析message的日期。输入:2000-01-21 04:51:00,输出:4:51 am.Friday,January 21,2000

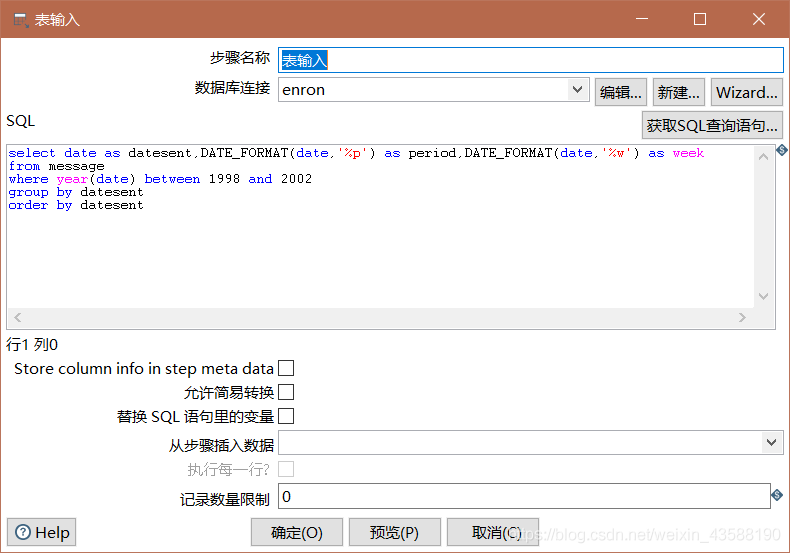
1.首先进行sql表输入
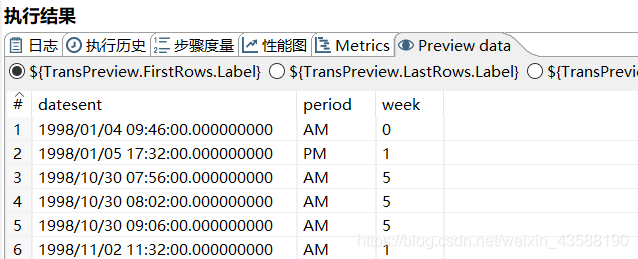
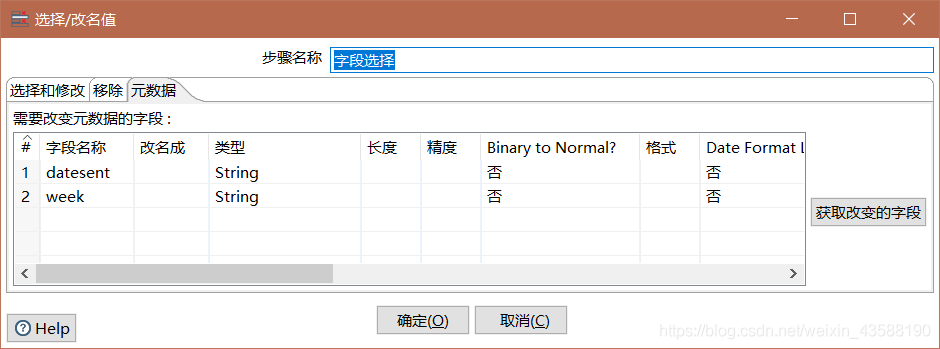
2.进行字段选择,将日期和星期数转换为string类型
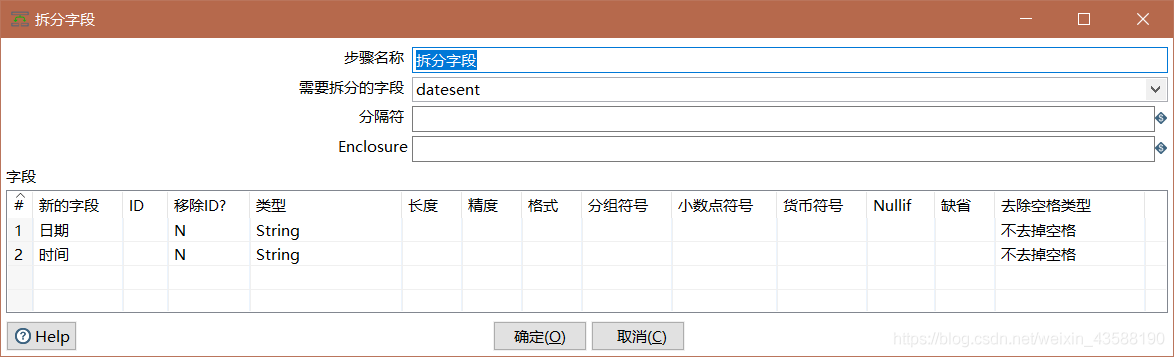
3.将datesent字段进行切分为日期和时间两个部分
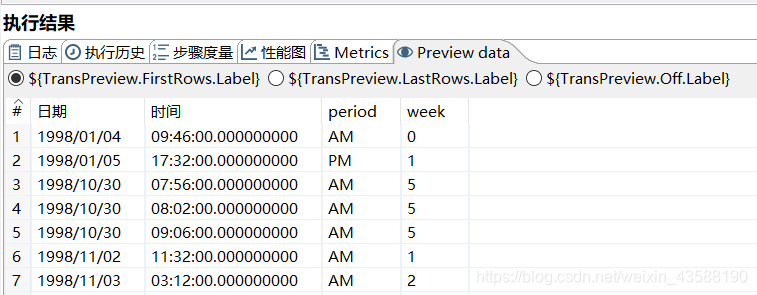
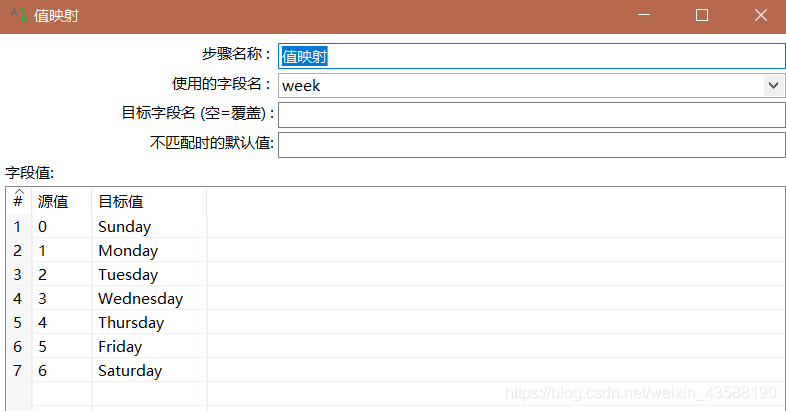
4.进行值映射,将0-6的数字映射为具体的中文星期
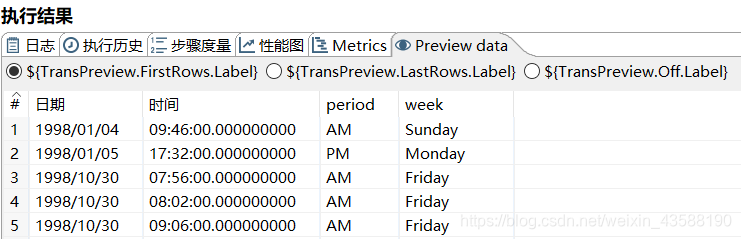
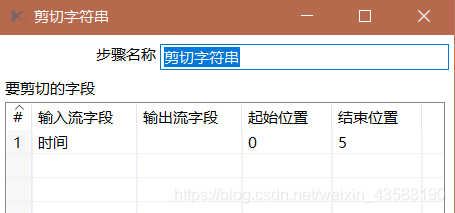
5.剪切时间字符段,保留小时和分钟数

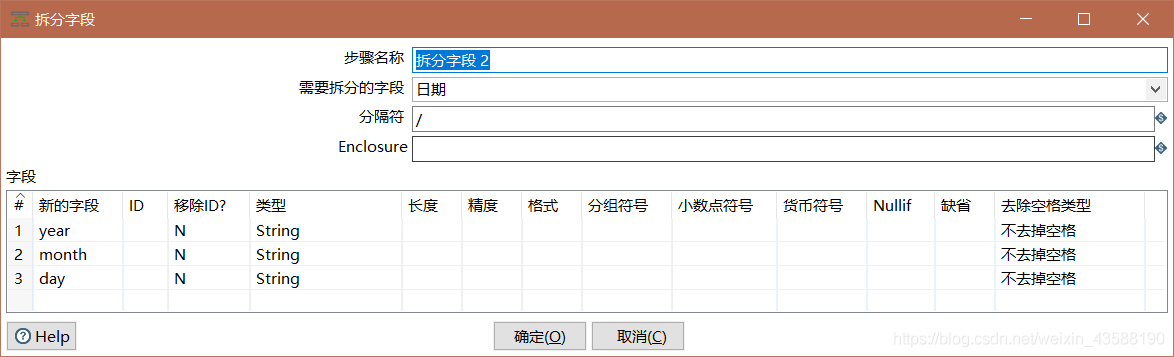
6.将日期字符段分为具体的年月日
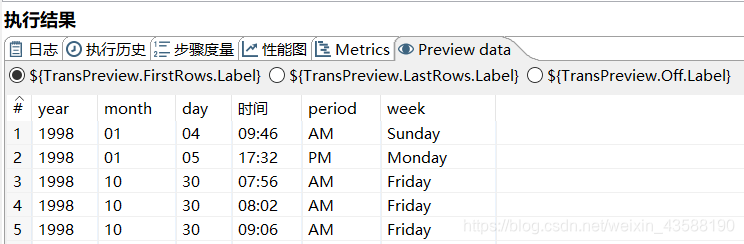
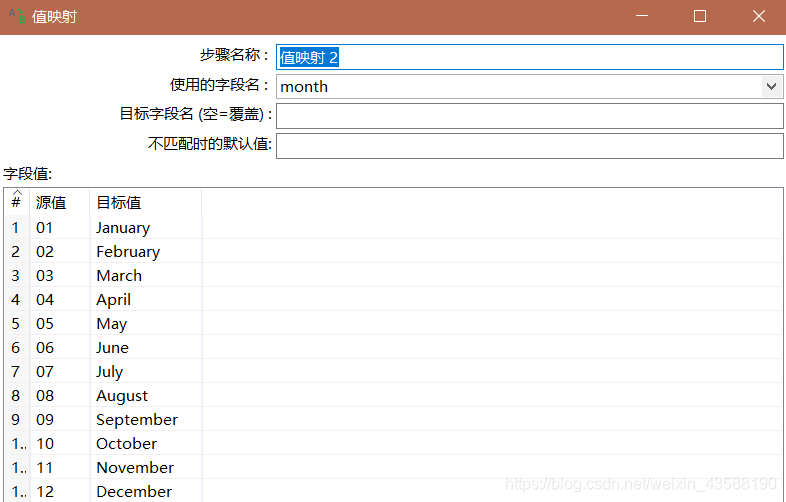
7.将month字符段映射为英文月份
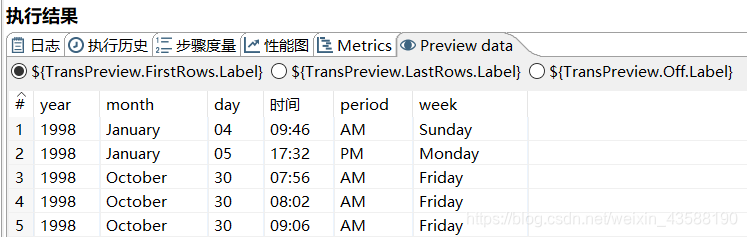
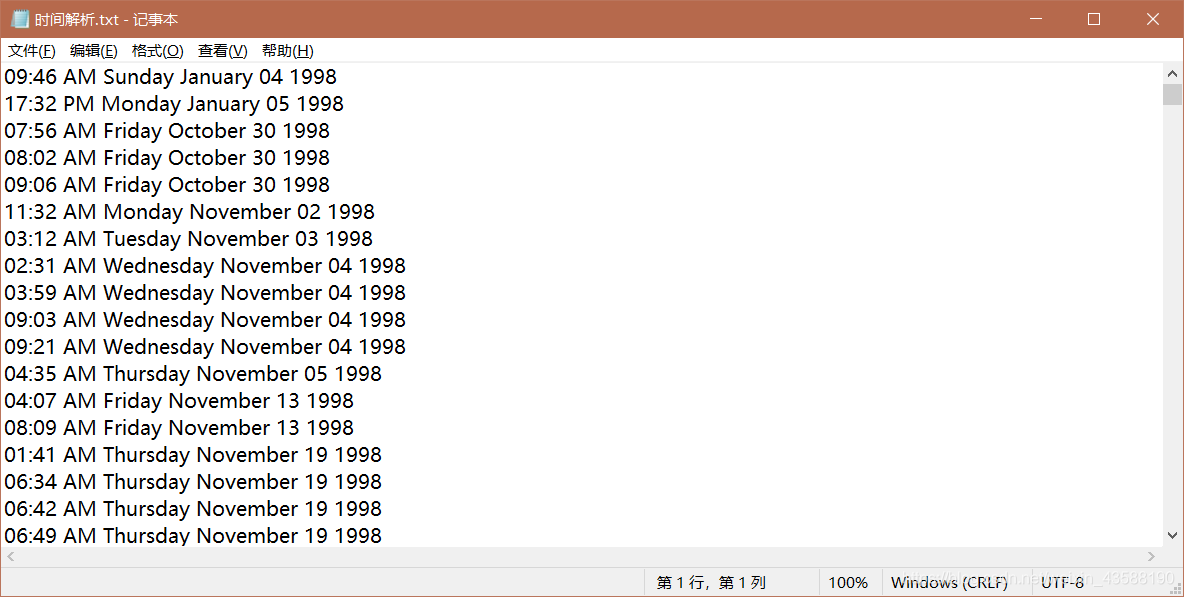
8.写入文本文件,得到结果如下所示
第3题. 提取iTune歌曲
【实验内容集要求】
采用iTunes API做个小实验,利用关键词来生成JSON数据结果集。iTunes是由Apple公司提供的一个音乐服务,任何人都可以利用iTunes服务来查找歌曲、艺术家和专辑。
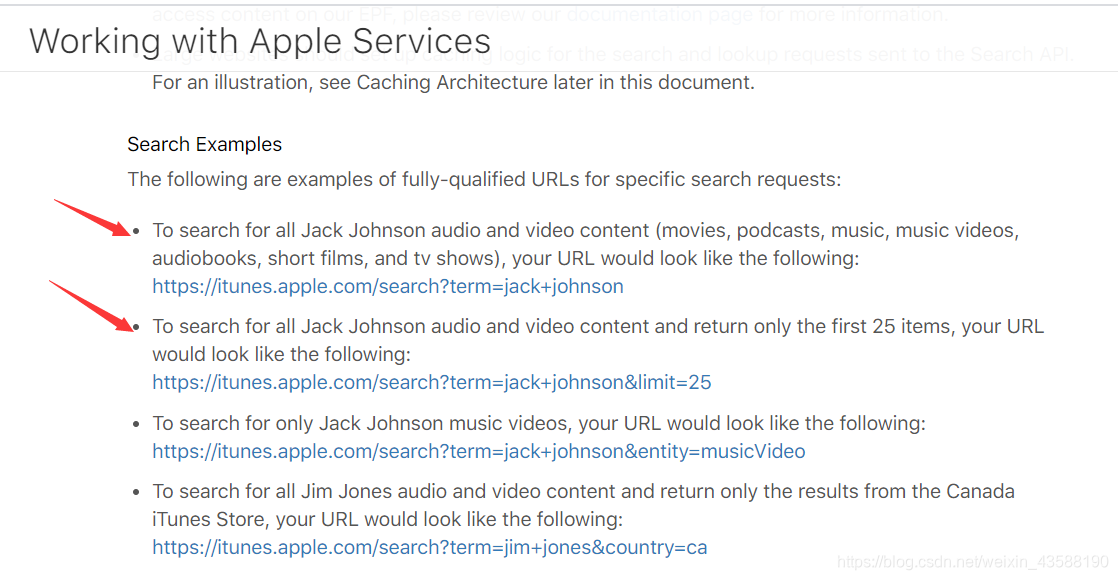
(1) 利用iTune API 下载Jack Johnson的所有音频和视频数据;
(2) 利用iTune API 下载Jack Johnson的前25个音频和视频数据
Apple iTunes的开发文档:
https://affiliate.itunes.apple.com/resources/documentation/itunes-store-web-service-search-api/
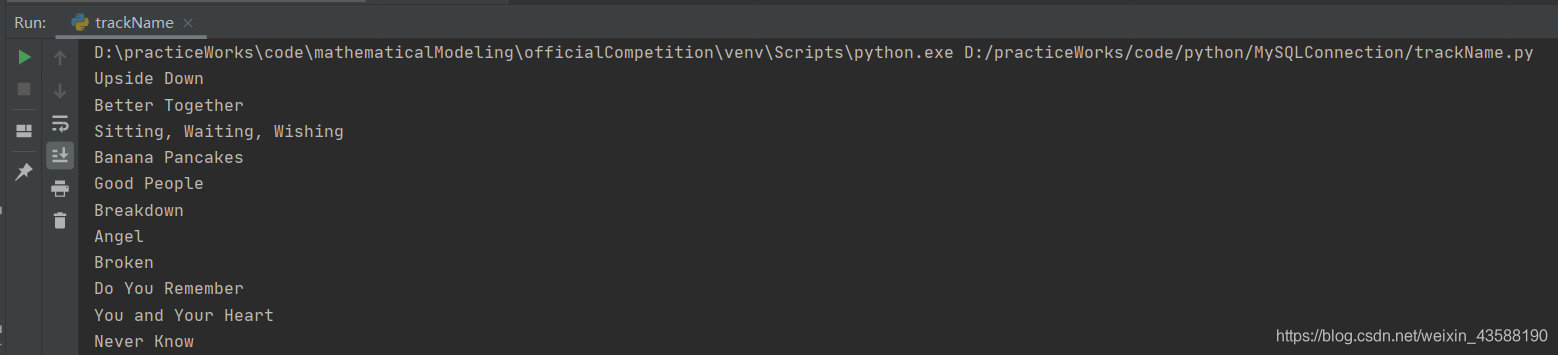
(3)使用一种熟悉的语言,编写程序,将下载下来的Jack Johnson的所有音频和视频的名称提取出来,并以控制台和Excel两种格式输出。
下载数据文件如下所示:

import json
import xlsxwriter
with open("Jack Johnson.json","r") as f:
json_str = f.read()
#print(type(json_str))
#转换为json字符串
json_str=json.loads(json_str)
#print(type(json_str))
s = json.dumps(json_str)
#print(s)
#把json转换为字典
s1 = json.loads(s)
#print(s1)
#print(type(s1))
#创建一个excel
workBook1 = xlsxwriter.Workbook('./jack.xlsx')
#创建一个sheet
workSheet = workBook1.add_worksheet('sheet1')
for num in range(0,50):
x=s1['results'][num]["trackName"]
print(x)
workSheet.write(num,0,x)
workBook1.close()