tensorflow打印模型结构_深度学习入门 | 第三章:神经网络的TensorFlow实现(2)

点击关注了解更多精彩内容!!
3.3线性回归模型的Tensorflow实现
深度学习是一种特殊的非线性回归分析方法,之所以“特殊”,是因为它常常涉及非结构化数据,如图像、声音、语言。本节首先复习线性回归的基础知识,然后以图像作为非结构化的 变量,以连续型因变量作为
变量,以连续型因变量作为 ,在TensorFlow的框架下建立到的线性回归模型。最后通过一个美食评分案例介绍代码实现的步骤。
,在TensorFlow的框架下建立到的线性回归模型。最后通过一个美食评分案例介绍代码实现的步骤。
3.3.1 线性回归模型
线性回归(Linear Regression)是指利用回归分析来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
进行回归分析之前,首先要确定因变量和自变量。
(1)因变量(Dependent Variable):是被预测或被解释的变量,用 表示。
表示。
(2)自变量(Independent Variable):是用来预测或解释因变量的一个或多个变量,用 表示。
表示。
因此,如果回归分析只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,则这种回归分析称为一元线性回归分析。如果在回归分析包括两个或两个以上自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
假设 是一个连续型因变量,表示人们对一张彩色图像的喜爱程度,
是一个连续型因变量,表示人们对一张彩色图像的喜爱程度, 是相应的解释性变量(一张三通道彩色图像的立体像素矩阵),由于个性化的因素,无法通过一张图像
是相应的解释性变量(一张三通道彩色图像的立体像素矩阵),由于个性化的因素,无法通过一张图像 来解释
来解释 ,所以除了
,所以除了 之外,还要考虑噪音项?,?代表所有与
之外,还要考虑噪音项?,?代表所有与 相关却与图像
相关却与图像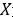 无关的因素。那么,一个标准的线性回归模型设定如下:
无关的因素。那么,一个标准的线性回归模型设定如下:

各参数的含义如下。
 :截距项。
:截距项。
 :第
:第 个通道的第
个通道的第 个像素点的取值。
个像素点的取值。
 :回归系数矩阵,
:回归系数矩阵, 是
是 相应的权重。
相应的权重。
? :随机误差项。
:随机误差项。
这样,通过线性回归模型在非结构化图像数据和连续型因变量之间建立了简单的相关关系。以此为基础,接下来通过一个案例介绍如何在TensorFlow的框架下实现线性回归模型。
3.3.2 案例:美食图像评分
在本案例中, 变量是各种美食图像,如图3.2所示,因变量
变量是各种美食图像,如图3.2所示,因变量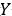 是每张图像的打分。下面简要介绍本案例数据的情况。
是每张图像的打分。下面简要介绍本案例数据的情况。

图3.2 美食图像展示
1.数据介绍
本案例数据集来源于网上的开源项目,我们从Flickr上收集用户上传的各种食物图像,由于上传用户不同的偏好,图像的主体大小、颜色和构图都不尽相同。经过人工筛选,最终收集到了196张图像用于案例分析。为了得到每张图像的打分数据:我们组织了一个由5人构成的研究小组,每个人对每张美食图像进行1~5评分,其中1分代表图像非常不吸引人,5分代表图像非常吸引人,最后取平均分作为每张图像的最终得分,从而得出本案例的因变量 。需要强调一点的是,由于每个人的主观偏好不同,所以每张图像的最终打分并不能代表客观真实的评分,数据仅用于本次案例教学分析。
。需要强调一点的是,由于每个人的主观偏好不同,所以每张图像的最终打分并不能代表客观真实的评分,数据仅用于本次案例教学分析。
2.准备X+Y数据
首先,把数据整理好,放在特定目录结构下,读入 数据如代码示例3-7所示。
数据如代码示例3-7所示。
代码示例3-7
import pandas as pd
MasterFile=pd.read_csv('./FoodScore.csv') print(MasterFile.shape)
MasterFile[0:5]
(1)加载pandas包并将其命名为pd。
(2)read_csv函数读入文件。
(3)打印数据形状。
(4)展示数据的前五行。
从输出结果可以看到数据集一共含有196张图像,其中第一列是图像编号,第二列为得分情况,具体输出结果如下:
(196, 2)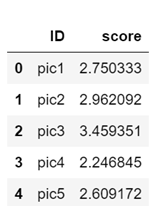
接下来,对美食图像打分数据绘制直方图,以观察数据分布的形态以及是否有异常值存在。总体来看近似于正态分布,大多数美食图像得分集中在3.5~4.0,少部分得分较高,接近5.0,少部分得分较低,仅为1分左右。具体如代码示例3-8所示。
代码示例3-8
MasterFile.hist()
输出:

FoodScore.csv文件有两列,第一列是图像的编号,同时也是图像的文件名,第二列为图像得分,为了后续建模方便,需要把因变量 分离出来。具体如代码示例3-9所示。
分离出来。具体如代码示例3-9所示。
代码示例3-9
import numpy as np
FileNames=MasterFile['ID']
N=len(FileNames)
Y=np.array(MasterFile['score']).reshape([N,1])#Y=(Y-np.mean(Y))/np.std(Y)
 的分离需要使用numpy中的array()函数将MasterFile 中的score取出并转化为普通数组,通过.reshape函数转换为
的分离需要使用numpy中的array()函数将MasterFile 中的score取出并转化为普通数组,通过.reshape函数转换为 行1列的向量。接下来采用Image包读取和处理图像数据。具体如代码示例3-10所示。
行1列的向量。接下来采用Image包读取和处理图像数据。具体如代码示例3-10所示。
代码示例3-10
from PIL import Image
IMSIZE=128
X=np.zeros([N,IMSIZE,IMSIZE,3])for i in range(N):
MyFile=FileNames[i]
Im=Image.open('../case3-food/data/'+MyFile+'.jpg')
Im=Im.resize([IMSIZE,IMSIZE])
Im=np.array(Im)/255
X[i,]=Im
由于不同图像的分辨率不同,无法将图像统一输入给TensorFlow进行处理,所以首先要统一所有图像的像素,这里主观地设定IMSIZE=128。通过numpy中的zeros()函数初始化一个四维立体矩阵,其中N代表图像的数量,IMSIZE是像素水平,由于是彩色图像,所以有3个通道,最后一个参数是3。
接下来,需要把每一张彩色图像变成立体矩阵存储在计算机中。函数Image.open()用来打开图像文件,利用resize函数将图像转换成128像素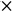 128像素水平,然后通过np.array()将其变成数组形式,此时数组大小为128像素128像素3,取值范围为0~255。因为TensorFlow要求输入的每个像素点的取值范围为0~1,所以需要将原始数据再除以255,最后得到128像素128像素3的立体矩阵,并且每个元素取值范围为0~1。至此,X和Y数据均已准备好。
128像素水平,然后通过np.array()将其变成数组形式,此时数组大小为128像素128像素3,取值范围为0~255。因为TensorFlow要求输入的每个像素点的取值范围为0~1,所以需要将原始数据再除以255,最后得到128像素128像素3的立体矩阵,并且每个元素取值范围为0~1。至此,X和Y数据均已准备好。
3.数据展示
由于数据处理过程可能出现异常现象和错误,因此最好在 和
和 数据准备好后,展示数据,确定无误后再做模型分析。这里展示前10张图像。具体如代码示例3-11所示。
数据准备好后,展示数据,确定无误后再做模型分析。这里展示前10张图像。具体如代码示例3-11所示。
代码示例3-11
from matplotlib import pyplot as plt
plt.figure()
fig,ax=plt.subplots(2,5)
fig.set_figheight(7.5)
fig.set_figwidth(15)
ax=ax.flatten()for i in range(10):
ax[i].imshow(X[i,:,:,:])
ax[i].set_title(np.round(Y[i],2))
需要加载pyplot包实现画图功能,首先通过plt.figure()初始化一个画板,plt.subplots(2,5)将画板切分为2行5列,设置高度为7.5个单位,宽度为15个单位。用ax变量记录图像位置,为了能用一层循环遍历所有元素,用flatten()函数将ax变量拉直,拉直后的ax是长度为10的数组。接下来通过imshow()函数展示 中的第
中的第 个图像,同时通过set_title()函数将每张图像的因变量作为标题展示在图像上方,np.round()函数用于将因变量保留两位小数。美食图像如图3.3所示。
个图像,同时通过set_title()函数将每张图像的因变量作为标题展示在图像上方,np.round()函数用于将因变量保留两位小数。美食图像如图3.3所示。

图3.3 美食图像
4.切分训练集与测试集
数据准备好之后,要将其切分为训练集和测试集,其中训练集用于模型训练,测试集用来验证模型的精度。在TensorFlow中可以直接调用train_test_split切分训练集和测试集,其中test_size()规定测试集大小,random_state()固定随机种子,以保证结果可重复。经过数据切分,得到训练数据集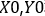 和验证数据集
和验证数据集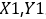 。具体如代码示例3-12所示。
。具体如代码示例3-12所示。
代码示例3-12
from sklearn.cross_validation import train_test_split
X0,X1,Y0,Y1=train_test_split(X,Y,test_size=0.5,random_state=0)
5.线性回归模型构建
首先需要从keras中载入Dense、Flatten、Input和Model模块。定义输入层input_layer= Input([IMSIZE,IMSIZE,3]),之后用Flatten()函数将其拉直,x从立体向量变为一个长向量,这是为后面的全连接层做准备。
Flatten()函数有两个输入,其中第一个括号是空的,因为普通线性回归不需要其他额外的定义,第二个输入的x是128像素*128像素*3的立体矩阵,经过Flatten之后输出一个长向量x。Dense()是全连接层,其中第一个()中的1表示不管输入多长的向量,最后只输出一个标量,对于线性回归模型,Y就是一个节点输出,所以Dense()函数用于将向量x进行线性组合变成标量x然后输出。
定义最后输出的x为output_layer,最后用Model()函数将input_layer和output_layer结合起来,完成整个模型的设计结构。具体如代码示例3-13所示。
代码示例3-13
from keras.layers import Dense, Flatten, Input
from keras import Model
input_layer=Input([IMSIZE,IMSIZE,3])
x=input_layer
x=Flatten()(x)
x=Dense(1)(x)
output_layer=x
model=Model(input_layer,output_layer)
model.summary()
model储存了所有模型的设计信息,通过model.summary()可以总结并打印输出模型信息。如图3.4所示,观察输出结果可知,整个模型需要49,153个参数,这是因为 个元素,每个元素需要一个权重,此外还有一个截距项,所以模型消耗的总参数就是49,153个。
个元素,每个元素需要一个权重,此外还有一个截距项,所以模型消耗的总参数就是49,153个。

图3.4 模型概要
6.模型编译
网络构建好之后,就是模型训练,在Keras中通过编译(compile)实现,具体如代码示例3-14所示。该步骤涉及3个参数,分别是:
(1)损失函数(loss function):即模型如何衡量在训练数据上的性能。
(2)优化器(optimizer):基于训练数据和损失函数更新网络的机制。
(3)在训练和测试过程中需要监控的指标(metric):本案例使用残差平方和MSE。
代码示例3-14
from keras.optimizers import Adam
model.compile(loss='mse',optimizer=Adam(lr=0.001),metrics=['mse'])
调用model.compile函数优化模型,其中定义loss=‘mse’表示要优化的损失函数是最小二乘估计中的残差平方和。优化算法选择Adam,学习率是0.001,metrics=[‘mse’]表示监控指标是MSE。
7.模型拟合
最后用model.fit验证模型的外样本精度。具体如代码示例3-15所示。
代码示例3-15
model.fit(X0,Y0,
validation_data=[X1,Y1],
batch_size=100,
epochs=100)
其中训练数据集为 验证数据集。
验证数据集。 。
。 表示把所有样本随机排序后切成100个batch。100个batch做完后,所有样本已经被遍历,称为一个epoch循环。为了使收敛结果好,可以适当增加epoch循环的次数。受篇幅所限,仅展示前6次和最后6次循环的结果,前6次循环的结果如图3.5所示。
表示把所有样本随机排序后切成100个batch。100个batch做完后,所有样本已经被遍历,称为一个epoch循环。为了使收敛结果好,可以适当增加epoch循环的次数。受篇幅所限,仅展示前6次和最后6次循环的结果,前6次循环的结果如图3.5所示。

图3.5 前6次循环结果
后6次循环的结果如图3.6所示。

图3.6 后6次循环结果
我们的监测目标是MSE,TensorFlow会输出每次循环的结果,其中val_mean_squared_error表示测试集上的MSE。在300次迭代中,刚开始,外样本的MSE高达200多。但接近200次时,外样本的MSE已经降到1.25,且最后几次都在1.25附近徘徊,表明已收敛到这个速度,这就是该线性回归模型的外样本精度。
8.模型预测
最后,用这个模型预测,输入任意一张美食图像,会输出什么结果呢?大家不妨自己尝试一下,具体如代码示例3-16所示。
代码示例3-16
MyPic=Image.open('mypic.jpg')
MyPic
MyPic=MyPic.resize((IMSIZE,IMSIZE))
MyPic=np.array(MyPic)/255
MyPic=MyPic.reshape((1,IMSIZE,IMSIZE,3))
model.predict(MyPic)
好了,第三章的第二部分内容今天就更新完毕了,下周继续更新第三章剩余的内容,欢迎大家点击同步收看狗熊会慕课平台的深度学习课程,里面有熊大的精彩讲解!
 往期精彩第1章:深度学习简介第2章:神经网络基础(1)第2章:神经网络基础(2)第3章:神经网络的TensorFlow实现(1)点击这里阅读原文
往期精彩第1章:深度学习简介第2章:神经网络基础(1)第2章:神经网络基础(2)第3章:神经网络的TensorFlow实现(1)点击这里阅读原文
