NEO4J-相似度算法02-余弦相似度使用说明应用场景简介
二、余弦相似度算法(Cosine Similarity )
余弦相似度是n维空间中两个n维向量之间夹角的余弦。它是两个向量的点积除以两个向量的长度(或幅度)的乘积
1.解释,余弦相似度公式如下:
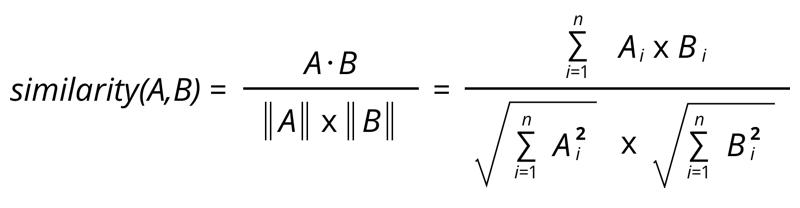
2.何时使用余弦相似度算法
我们可以使用余弦相似度算法来计算两件事之间的相似度。然后,我们可能会将计算出的相似度用作推荐查询的一部分。例如,根据对您看过的其他电影给予相似评分的用户的偏好来获得电影推荐
3.余弦相似度算法函数示例
余弦相似度函数计算两个数字列表的相似度
示例1:以下将返回两个数字列表的余弦相似度
RETURN algo.similarity.cosine([3,8,7,5,2,9], [10,8,6,6,4,5]) AS similarity
执行结果:
这两个数字列表的余弦相似度为 0.863。我们可以通过分解公式来看看这个结果是如何得出的:
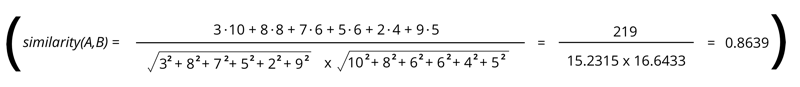
我们还可以使用它来计算基于 Cypher 查询计算的列表的节点的相似性
下面创建一段示例数据:
MERGE (french:Cuisine {name:'French'}) MERGE (italian:Cuisine {name:'Italian'}) MERGE (indian:Cuisine {name:'Indian'}) MERGE (lebanese:Cuisine {name:'Lebanese'}) MERGE (portuguese:Cuisine {name:'Portuguese'}) MERGE (british:Cuisine {name:'British'}) MERGE (mauritian:Cuisine {name:'Mauritian'}) MERGE (zhen:Person {name: "Zhen"}) MERGE (praveena:Person {name: "Praveena"}) MERGE (michael:Person {name: "Michael"}) MERGE (arya:Person {name: "Arya"}) MERGE (karin:Person {name: "Karin"}) MERGE (praveena)-[:LIKES {score: 9}]->(indian) MERGE (praveena)-[:LIKES {score: 7}]->(portuguese) MERGE (praveena)-[:LIKES {score: 8}]->(british) MERGE (praveena)-[:LIKES {score: 1}]->(mauritian) MERGE (zhen)-[:LIKES {score: 10}]->(french) MERGE (zhen)-[:LIKES {score: 6}]->(indian) MERGE (zhen)-[:LIKES {score: 2}]->(british) MERGE (michael)-[:LIKES {score: 8}]->(french) MERGE (michael)-[:LIKES {score: 7}]->(italian) MERGE (michael)-[:LIKES {score: 9}]->(indian) MERGE (michael)-[:LIKES {score: 3}]->(portuguese) MERGE (arya)-[:LIKES {score: 10}]->(lebanese) MERGE (arya)-[:LIKES {score: 10}]->(italian) MERGE (arya)-[:LIKES {score: 7}]->(portuguese) MERGE (arya)-[:LIKES {score: 9}]->(mauritian) MERGE (karin)-[:LIKES {score: 9}]->(lebanese) MERGE (karin)-[:LIKES {score: 7}]->(italian) MERGE (karin)-[:LIKES {score: 10}]->(portuguese)
以下将返回 Michael 和 Arya 的余弦相似度:
MATCH (p1:Person {name: 'Michael'})-[likes1:LIKES]->(cuisine) MATCH (p2:Person {name: "Arya"})-[likes2:LIKES]->(cuisine) RETURN p1.name AS from, p2.name AS to, algo.similarity.cosine(collect(likes1.score), collect(likes2.score)) AS similarity
执行结果:
以下结果将返回Michael和其它有共同美食德人的余弦相似度:
MATCH (p1:Person {name: 'Michael'})-[likes1:LIKES]->(cuisine) MATCH (p2:Person)-[likes2:LIKES]->(cuisine) WHERE p2 <> p1 RETURN p1.name AS from, p2.name AS to, algo.similarity.cosine(collect(likes1.score), collect(likes2.score)) AS similarity ORDER BY similarity DESC
执行结果:
4.余弦相似度算法程序示例
余弦相似度过程计算所有项目对之间的相似度。它是一种对称算法,即计算 Item A 与 Item B 的相似度的结果与计算 Item B 与 Item A 的相似度的结果相同。因此我们可以为每对节点计算一次分数。我们不计算物品与其自身的相似度
计算次数是((# items)^2 / 2) - # items,如果我们有很多节点,这在计算上可能非常昂贵。余弦相似度仅在非 NULL 维度上计算。这些过程期望为所有项目接收相同长度的列表,因此我们需要algo.NaN()在必要时填充这些列表
示例1:以下将返回节点流向以及她们的余弦相似度
MATCH (p:Person), (c:Cuisine) OPTIONAL MATCH (p)-[likes:LIKES]->(c) WITH {item:id(p), weights: collect(coalesce(likes.score, algo.NaN()))} as userData WITH collect(userData) as data CALL algo.similarity.cosine.stream(data) YIELD item1, item2, count1, count2, similarity RETURN algo.asNode(item1).name AS from, algo.asNode(item2).name AS to, similarity ORDER BY similarity DESC
执行结果:
场景二:Praveena 和 Karin 的食物口味最相似,得分为 1.0,另外还有几对口味相似的用户。这里的分数异常高,因为我们的用户不喜欢许多相同的美食。我们也有 2 对完全不相似的用户。我们可能想过滤掉那些,我们可以通过传入similarityCutoff参数来完成
示例2:以下将返回相似度至少为 0.1 的节点对流,以及它们的余弦相似度
MATCH (p:Person), (c:Cuisine) OPTIONAL MATCH (p)-[likes:LIKES]->(c) WITH {item:id(p), weights: collect(coalesce(likes.score, algo.NaN()))} as userData WITH collect(userData) as data CALL algo.similarity.cosine.stream(data, {similarityCutoff: 0.0}) YIELD item1, item2, count1, count2, similarity RETURN algo.asNode(item1).name AS from, algo.asNode(item2).name AS to, similarity ORDER BY similarity DESC
执行结果:
我们可以看到那些没有相似性的用户已经被过滤掉了。如果我们正在实现 k-Nearest Neighbors 类型的查询,我们可能希望k为给定用户找到最相似的用户。我们可以通过传入topK参数来做到这一点
示例3:以下将返回用户流以及他们最相似的用户(即k=1)
MATCH (p:Person), (c:Cuisine) OPTIONAL MATCH (p)-[likes:LIKES]->(c) WITH {item:id(p), weights: collect(coalesce(likes.score, algo.NaN()))} as userData WITH collect(userData) as data CALL algo.similarity.cosine.stream(data, {topK:1, similarityCutoff: 0.0}) YIELD item1, item2, count1, count2, similarity RETURN algo.asNode(item1).name AS from, algo.asNode(item2).name AS to, similarity ORDER BY from
执行结果:
这些结果不会是对称的。例如,与Zhen最相似的人是Michael,而与Michael最相似的人是Arya
示例4:下面将为每个用户找到最相似的用户,并存储这些用户之间的关系:
MATCH (p:Person), (c:Cuisine) OPTIONAL MATCH (p)-[likes:LIKES]->(c) WITH {item:id(p), weights: collect(coalesce(likes.score, algo.NaN()))} as userData WITH collect(userData) as data CALL algo.similarity.cosine(data, {topK: 1, similarityCutoff: 0.1, write:true}) YIELD nodes, similarityPairs, write, writeRelationshipType, writeProperty, min, max, mean, stdDev, p25, p50, p75, p90, p95, p99, p999, p100 RETURN nodes, similarityPairs, write, writeRelationshipType, writeProperty, min, max, mean, p95
执行结果:
然后我们可以编写一个查询来找出与我们相似的其他人可能喜欢什么类型的美食
示例5:以下将找到与 Praveena 最相似的用户,并返回他们最喜欢的但 Praveena 不(还!)喜欢的美食
MATCH (p:Person {name: "Praveena"})-[:SIMILAR]->(other),
(other)-[:LIKES]->(cuisine)
WHERE not((p)-[:LIKES]->(cuisine))
RETURN cuisine.name AS cuisine
执行结果:
有时,我们不想计算所有对的相似性,而是希望指定项目的子集来相互比较。我们使用配置中的sourceIds和targetIds键来做到这一点。我们可以使用这种技术来计算项目子集与所有其他项目的相似度
示例6:以下将找到与k=1Arya 和 Praveena最相似的人(即):
MATCH (p:Person), (c:Cuisine) OPTIONAL MATCH (p)-[likes:LIKES]->(c) WITH {item:id(p), name: p.name, weights: collect(coalesce(likes.score, algo.NaN()))} as userData WITH collect(userData) as personCuisines
// create sourceIds list containing ids for Praveena and Arya
WITH personCuisines, [value in personCuisines WHERE value.name IN ["Praveena", "Arya"] | value.item ] AS sourceIds CALL algo.similarity.cosine.stream(personCuisines, {sourceIds: sourceIds, topK: 1}) YIELD item1, item2, similarity WITH algo.getNodeById(item1) AS from, algo.getNodeById(item2) AS to, similarity RETURN from.name AS from, to.name AS to, similarity ORDER BY similarity DESC
执行结果:
5.相似度算法源码解析:
@UserFunction("algo.similarity.cosine")
@Description("algo.similarity.cosine([vector1], [vector2]) " +
"given two collection vectors, calculate cosine similarity")
public double cosineSimilarity(@Name("vector1") List<Number> vector1, @Name("vector2") List<Number> vector2) {
if (vector1.size() != vector2.size() || vector1.size() == 0) {
throw new RuntimeException("Vectors must be non-empty and of the same size");
}
int len = Math.min(vector1.size(), vector2.size());
double[] weights1 = new double[len];
double[] weights2 = new double[len];
for (int i = 0; i < len; i++) {
weights1[i] = vector1.get(i).doubleValue();
weights2[i] = vector2.get(i).doubleValue();
}
return Math.sqrt(Intersections.cosineSquare(weights1, weights2, len));
}
根据源码得出以下结论:
1.余弦相似度入参为vector1和vector2,入参必须为集合形式
2.两个数字类型的集合,且两者长度必须一致,且入参不能为空,长度必须大于0