数据同步之采用时间戳的方法进行增量数据同步(三)
文主要讨论,采用时间戳的方法进行增量数据同步时,造成源表和目标表数据不一致的情况的原因进行讨论。在浏览此文时,请大家先浏览数据同步之采用时间戳的方法进行增量数据同步(一)、数据同步之采用时间戳的方法进行增量数据同步(二)这两篇文章。在探讨这个问题时,本文还是继续引用前面的文章的例子。
一、数据同步情况说明
将源数据库S中的A表(将此表称为源表),通过ETL工具同步至目标数据库T的A表(将此表称为目标表)。假设源表A的表结构与目标表A的表结构完全一致。表结构如下图所示:

采用时间戳的方式进行增量数据同步,需要目标数据库T中建立一张数据同步日志表LOG,来记录每次数据同步的情况。
表结构如下图所示:
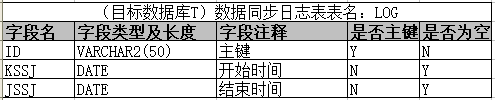
其中,KSSJ、JSSJ字段为保存的值为源表A中每次数据同步时,根据ZHXGSJ字段进行数据过滤的字段值。
二、数据同步存在的问题
1、数据遗漏,即数据量不一致。即源表和目标表的数据量不一致。
2、数据记录内容不一致。即源表和目标表的数据量一致。但是存在部分数据,它们分别对应的源表和目标表的数据记录,内容不一致。
三、数据同步问题的原因分析。
1、源系统(即源表对应系统)开发人员的原因。
这种原因经常使得数据同步时,造成数据记录内容不一致。它是源系统的开发人员在修改源表的某记录的时候,并未同步更新对应记录的时间戳字段造成的。
在本例中,源系统的开发人员,在对源表A中插入一条记录时,使用的SQL为:
insert into A(ID,MC,ZHXGSJ) values ('111111','测试',to_date('2019-01-01 12:05:00','yyyy-mm-dd hh24:mi:ss'))
此SQL语句中,ZHXGSJ为该记录的插入时间。
数据同步服务,将源表A的这条记录(ID为111111)同步到目标表A中,此时,源表A的这条记录(ID为111111)任何字段(ID,MC,ZHXGSJ)及其字段值,都与目标表A对应的记录,一致。此时源表A与目标表A,数据量及数据记录内容,都一致。
源表A对应系统的开发人员,对源表A的记录(ID为111111),进行修改时,使用的SQL为:
update A set MC = '新测试' where ID='111111'
如果源系统的开发人员,使用此SQL语句,进行修改时,数据同步服务,在根据ZHGXSJ这个时间戳,对源表A进行增量数据同步的时候,增量数据中并不一定会获取到此记录(ID为111111),也就会造成源表A的这条记录(ID为111111)与目标表A对应的记录内容不一致。
正确的做法是,源系统的开发人员,在对源表A的记录(ID为111111),进行修改时,应该使用的正确的SQL,即:
update A set MC = '新测试', ZHXGSJ = to_date('2019-02-01 09:05:00' where ID='111111'
此SQL语句中,ZHXGSJ为该记录的修改时间。这样可以保证,数据同步服务,在根据ZHGXSJ这个时间戳,对源表A进行增量数据同步的时候,(理论上)增量数据中能够会获取到此记录(ID为111111)。
由于时间戳字段,对于系统来说,它是没有任何业务意义的,时间戳字段(ZHXGSJ)其字段值不更新,并不会影响系统的业务,所以,开发人员对此字段不够重视。加之开发人员对于数据同步的原理认识不够,另外多人分组开发,多人多次更新源表,都是造成源表与目标表,数据记录内容不一致的情况。
2、数据同步人员(通常由专业的数据同步公司,即非源系统开发公司来做)的原因。
这种原因是数据同步人员,并没有使用源表的时间戳字段值,作为增量数据的获取。该人员可能使用的是sysdate-1过滤增量数据,也可能没有使用所有的时间戳字段过滤增量数据。
在数据同步之采用时间戳的方法进行增量数据同步(一)、数据同步之采用时间戳的方法进行增量数据同步(二)中都曾举例说明过此问题。该原因会造成数据遗漏、数据记录内容不一致的问题。
3、源系统架构设计的原因。
对于大中型的信息系统,为了提高系统的响应速度,增加网络的可用性等,常使用集群模式来实现负载均衡。既可对应用服务器进行负载均衡,又可对数据库服务器进行负载均衡。既可使用软负载,又可使用硬负载来实现负载均衡。假设源系统A的应用服务器集群的IP为:192.168.1.190、192.168.1.191,其数据库服务器的集群的IP为:192.168.1.180、192.168.1.181
源系统开发人员在对源表A的数据记录进行新增、修改等操作时,对于ZHXGSJ的字段,其字段值所获取的时间,来源于应用服务器的时间或是数据库服务器的时间。根据ZHXGSJ的字段所获取的时间来源,可以分以下几种情况,进行讨论:
1)、若ZHXGSJ的字段值的所获取的时间,来源于应用服务器的时间。(对于Java语言来说,可使用new Date()获取当前时间。)。由于应用服务器,采用了集群模式,实现负载均衡,则ZHXGSJ的字段值每次获取的时间值来源于服务器192.168.1.190、192.168.1.191中的某台机器。
下面举例说明,该原因如何会造成数据遗漏、数据记录内容不一致的问题。假设已知192.168.1.190服务器的时间比192.168.1.191服务器的时间慢5分钟。数据同步服务,每个1分钟执行一次。
源系统的开发人员,在对源表A中插入一条记录时,使用的时间为:192.168.1.191机器的时间,即SQL为:
insert into A(ID,MC,ZHXGSJ) values ('111111','测试',to_date('2019-01-01 12:05:00','yyyy-mm-dd hh24:mi:ss'))
假设数据同步服务,在本次增量数据同步时,能够将源表A的这条记录(ID为111111)同步到目标表A中,此时,源表A的这条记录(ID为111111)任何字段(ID,MC,ZHXGSJ)及其字段值,都与目标表A对应的记录,一致。此时源表A与目标表A,数据量及数据记录内容,都一致。根据增量数据同步原理可知,下次数据同步的时间戳的时间应该大于’2019-01-01 12:05:00’。
但若此时,源系统的开发人员,在对源表A中又插入一条记录时,使用的时间为:192.168.1.190机器的时间,即SQL为:
insert into A(ID,MC,ZHXGSJ) values ('222222','测试',to_date('2019-01-01 12:02:00','yyyy-mm-dd hh24:mi:ss'))
同时,当源表A对应系统的开发人员,对源表A的记录(ID为111111),进行修改时,使用的SQL为:
update A set MC = '新测试', ZHXGSJ = to_date('2019-01-01 12:02:00' where ID='111111'
根据增量数据同步原理可知,下次数据同步的时间戳的时间应该大于’2019-01-01 12:05:00’。很显然,这两条记录不再这个时间范围内。也就是下次数据同步服务运行时,它的增量数据是不会获取到源表A的这条记录(ID为222222)。所以,会出现数据遗漏的情况。同样的,它的增量数据是不会获取到源表A的这条记录(ID为111111)。所以,会出现数据记录内容不一致的情况。
2)、若ZHXGSJ的字段值的所获取的时间,来源于数据库服务器的时间。(对于oracle数据库来说,可使用sysdate获取当前时间。)由于数据库服务器,采用了集群模式,实现负载均衡,则ZHXGSJ的字段值每次获取的时间值来源于服务器192.168.1.180、192.168.1.181中的某台机器。
3)、若ZHXGSJ的字段值的所获取的时间,来源于应用服务器或者数据库服务器的时间。由于,系统通常是以多人分组合作开发的。若组内开发人员,并没有对于ZHXGSJ的字段值的所获取的时间的来源进行沟通,就会造成此情况。这种情况,也确实是存在的。由于应用服务器和数据库服务,都采用了集群模式,实现负载均衡,则ZHXGSJ的字段值每次获取的时间值来源于服务器192.168.1.190、192.168.1.191、192.168.1.180、192.168.1.181中的某台机器。
对于上述的三种情况,由于源系统,使用了负载均衡,故源表A的ZHXGSJ的字段值每次获取的时间值,都有可能来源于不同的服务器。若这些服务器之间存在时间不一致的情况,就会很容易造成,在采用时间戳的方法进行增量数据同步,数据同步会出现上述的数据遗漏、数据记录内容不一致的情况(可参照上述第一种情况中的例子)。对于这种问题,会在服务器上安装时钟同步程序,来解决此问题。
四、结论
采用时间戳的方法进行增量数据同步时,实现源表跟目标表数据一致,取决于源系统的架构设计、源系统开发人员的技术水平(在数据同步上)、数据同步人员的技术水平。所以,许多项目或产品,尤其是整合各平台各种数据资源的项目或产品,比如数据中心,数据服务资源体系平台等等,因为其需要整合多家公司的数据,而数据同步能否达到实时性、一致性并不是承建方单方面就能决定的,所以,其系统承建方是很难保证,其整合的所有同步的数据实时性,一致性。其系统承建方要实现其整合的所有同步的数据,在采用增量数据同步(这种类似大数据中心的系统都不会选择全量数据同步的方式)的时候,都能保证实时性、一致性,这几乎是不可能的事情。
五、其他
曾经有个项目中,该项目的开发人员,跟我在数据同步上跟他有了分歧。记得当时,他就跟我说:不就是差1分钟的数据吗?能有多少数据?我回答:1分钟,可以差几万条数据,甚至于几十万。他说:这么多,怎么可能?我答:卡口数据,就是交通路口,摄像头拍照的那个,一个卡口设备,1分钟可以拍多少张照片?一个路口,有多少个摄像头?全市,共有多少卡口?共有多少个摄像头?全市,1分钟的卡口数据又有多少?上万条,应该有了吧。很显然,他被我问住了。最后,他还是修改了他的代码。
不同的系统,它们对数据要求不一样。同一个系统,不同的业务场景,它对数据的要求也不一样。拿公安业务来说,情报系统,情报预警业务对数据的实时性有着较高的要求,数据只有实时性达到了,数据几乎没有延迟,才能保证预警;情报分析研判业务因其业务主要是分析研判,故对数据实时性的要求不高,允许有较小的延迟。
本人曾经参与过XX省公安厅大数据平台的项目建设,该项目是使用的大数据平台,是华为某大数据产品(为了配合此项目的需求,华为对其产品还进行了修改,该产品应该算是定制产品了。)。该产品在数据同步的功能上,其设置定时任务的间隔时间最小值为5分钟,即其产品每隔5分钟进行一次数据同步。因此,会造成该平台的数据有5分钟的延迟。这对于公安某些业务(比如:预警)是不符合业务需求的。