pytorch代码笔记
优兔卜/watch?v=c36lUUr864M&t=936s
https://github.com/python-engineer/pytorchTutorial.git
后面有几段是直接粘的源码,是实际情况(有的重复不想打了)和个人需求(作者提供的源码和我理解的知识分段轻微不搭),正好想有个笔记,综合产生了这些东西。
基本操作
import torch
import numpy as np
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
x = torch.ones(2,2,dtype=torch.double)
x.size()
x = torch.rand(2,2,requires_grad=True,device=device)
y = torch.rand(2,2,device=device)
z = x+y #+-*/
z = torch.add(x,y)#add sub mul
y.add_(x)# sub_ div_ 原地操作
x=torch.rand(4,4)
x[1][1].item()
y=x.view(-1,2) #插眼
a = torch.ones(5)
a.to("cuda")
a.add_(13)
b = a.numpy()
a = np.ones(6)
b = torch.from_numpy(a)
b.to(device)
print(a)
print(b)
Gradients
import torch
import numpy as np
x = torch.rand(3,requires_grad=True)#***
print(x)
y = x+2
z = y*y*2
#z = z.mean()
print(z)
v = torch.tensor([0.1,1.0,0.001],dtype=torch.float32)
z.backward(v)# 插眼:如果不是标量则必须给vecor ***
print(x.grad)
x = torch.rand(3,requires_grad=True)
#dont calculate 插眼
#x.requires_grad_(False)
#y = x.detach()
#with torch.no_grad():
# y = x + 2
# print(y)
weights = torch.ones(4,requires_grad=True)
for epoch in range(3):
model_output = (weights*3).sum()
model_output.backward()
print(weights.grad)
weights.grad.zero_() #将积累的计算清零 插眼,需要深入理解 ***
#optimizer
#optimizer = torch.optim.SGD([weights], lr=0.01)
#optimizer.step()
#optimizer.zero_grad()
Backpropagation
import torch
import numpy as np
x = torch.tensor(1.0)
y = torch.tensor(2.0)
w = torch.tensor(1.0,requires_grad=True)
y_hat = w * x
loss = (y_hat-y)**2
print(loss)
loss.backward()
print(w.grad)
Gradient Descent

import torch
import numpy as np
# f = w * x
# f = 2 * x
x = np.array([1,2,3,4],dtype=np.float32)
y = np.array([2,4,6,8],dtype=np.float32)
w = 0.0
# model prediction
def forward(x):
return w*x
# loss MSE
def loss(y,y_predicted):
return ((y_predicted-y)**2).mean()
# gradient
# MSE = 1/N * (w*x -y)**2
def gradient(x,y,y_predicted):
return np.dot(2*x,y_predicted-y).mean()
print(f'prediction before training: f(5) = {forward(5):.3f}')
# Training
learning_rate = 0.01
n_iters = 10
for epoch in range(n_iters):
# prediction = forward pass
y_pred = forward(x)
#loss
l = loss(y,y_pred)
# gradients
dw = gradient(x,y,y_pred)
#update weights
w-=learning_rate * dw
if epoch%1==0:
print(f'epoch {epoch+1}:w = {w:.3f},loss = {l:.8f}')
print(f'Prediction after training: f(5) = {forward(5):.3f}')

import torch
# f = w * x
# f = 2 * x
x = torch.tensor([1,2,3,4],dtype=torch.float32)
y = torch.tensor([2,4,6,8],dtype=torch.float32)
w = torch.tensor(0.0,dtype=torch.float32,requires_grad=True)
# model prediction
def forward(x):
return w*x
# loss MSE
def loss(y,y_predicted):
return ((y_predicted-y)**2).mean()
# gradient
# MSE = 1/N * (w*x -y)**2
def gradient(x,y,y_predicted):
return np.dot(2*x,y_predicted-y).mean()
print(f'prediction before training: f(5) = {forward(5):.3f}')
# Training
learning_rate = 0.01
n_iters = 10
for epoch in range(n_iters):
# prediction = forward pass
y_pred = forward(x)
#loss
l = loss(y,y_pred)
# gradients
#dw = gradient(x,y,y_pred)
l.backward()
#update weights
#w-=learning_rate * dw
with torch.no_grad():
w -= learning_rate * w.grad
#zero gradients
w.grad.zero_()
if epoch%1==0:
print(f'epoch {epoch+1}:w = {w:.3f},loss = {l:.8f}')
print(f'Prediction after training: f(5) = {forward(5):.3f}')
Training pipeline
- Design model (input,output size,forward pass)
- Construct loss and optimizer
- Training loop
- forward pass: compute and prediction
- backward pass: gradients
- update weights

import torch
import torch.nn as nn
# f = w * x
# f = 2 * x
x = torch.tensor([[1],[2],[3],[4]],dtype=torch.float32)
y = torch.tensor([[2],[4],[6],[8]],dtype=torch.float32)
w = torch.tensor(0.0,dtype=torch.float32,requires_grad=True)
x_test = torch.tensor([5],dtype=torch.float32)
n_samples,n_features = x.shape
print(n_samples,n_features)
input_size = n_features
output_size = n_features
class LinearRegression(nn.Module):
def __init__(self,input_dim,output_dim):
super(LinearRegression,self).__init__()
self.lin = nn.Linear(input_dim,output_dim)
def forward(self,x):
return self.lin(x)
#model = nn.Linear(input_size,output_size)
model = LinearRegression(input_size,output_size)
# model prediction
def forward(x):
return w*x
# loss MSE
def loss(y,y_predicted):
return ((y_predicted-y)**2).mean()
# gradient
# MSE = 1/N * (w*x -y)**2
def gradient(x,y,y_predicted):
return np.dot(2*x,y_predicted-y).mean()
print(f'Prediction before training: f(5) = {model(x_test).item():.3f}')
# Training
learning_rate = 0.1
n_iters = 300
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
for epoch in range(n_iters):
# prediction = forward pass
y_pred = forward(x)
#y_pred = model(x)
#loss
l = loss(y,y_pred)
# gradients
#dw = gradient(x,y,y_pred)
l.backward()
#update weights
#w-=learning_rate * dw
#with torch.no_grad():
# w -= learning_rate * w.grad
optimizer.step()
#zero gradients
#w.grad.zero_()
optimizer.zero_grad()
if epoch%1==0:
[w,b] = model.parameters()
print(f'epoch {epoch+1}:w = {w[0][0].item():.3f},loss = {l:.8f}')
print(f'Prediction after training: f(5) = {model(x_test).item():.3f}')

import torch
import torch.nn as nn
# f = w * x
# f = 2 * x
x = torch.tensor([[1],[2],[3],[4]],dtype=torch.float32)
y = torch.tensor([[2],[4],[6],[8]],dtype=torch.float32)
#w = torch.tensor(0.0,dtype=torch.float32,requires_grad=True)
x_test = torch.tensor([5],dtype=torch.float32)
n_samples,n_features = x.shape
print(n_samples,n_features)
input_size = n_features
output_size = n_features
class LinearRegression(nn.Module):
def __init__(self,input_dim,output_dim):
super(LinearRegression,self).__init__()
self.lin = nn.Linear(input_dim,output_dim)
def forward(self,x):
return self.lin(x)
#model = nn.Linear(input_size,output_size)
model = LinearRegression(input_size,output_size)
# model prediction
def forward(x):
return w*x
# loss MSE
def loss(y,y_predicted):
return ((y_predicted-y)**2).mean()
# gradient
# MSE = 1/N * (w*x -y)**2
def gradient(x,y,y_predicted):
return np.dot(2*x,y_predicted-y).mean()
print(f'Prediction before training: f(5) = {model(x_test).item():.3f}')
# Training
learning_rate = 0.1
n_iters = 300
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
for epoch in range(n_iters):
# prediction = forward pass
#y_pred = forward(x)
y_pred = model(x)
#loss
l = loss(y,y_pred)
# gradients
#dw = gradient(x,y,y_pred)
l.backward()
#update weights
#w-=learning_rate * dw
#with torch.no_grad():
# w -= learning_rate * w.grad
optimizer.step()
#zero gradients
#w.grad.zero_()
optimizer.zero_grad()
if epoch%1==0:
[w,b] = model.parameters()
print(f'epoch {epoch+1}:w = {w[0][0].item():.3f},loss = {l:.8f}')
print(f'Prediction after training: f(5) = {model(x_test).item():.3f}')
Linear Regression
- Design model (input,output size,forward pass)
- Construct loss and optimizer
- Training loop
- forward pass: compute and prediction
- backward pass: gradients
- update weights
import torch
import torch.nn as nn
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
# 0)prepare data
x_numpy,y_numpy = datasets.make_regression(n_samples=100,n_features=1,noise=20,random_state=1)
x = torch.from_numpy(x_numpy.astype(np.float32))
y = torch.from_numpy(y_numpy.astype(np.float32))
y = y.view(y.shape[0],1)# 插眼
n_samples,n_features = x.shape
# 1)model
input_size = n_features
output_size = 1
model = nn.Linear(input_size,output_size)
pr = model(x).detach().numpy()
# 2)loss and optimizer
learning_rate = 0.01
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 3)training loop
num_epochs = 200
for epoch in range(num_epochs):
# forward pss and loss
y_predicted = model(x)
loss = criterion(y_predicted,y)
# backward pass
loss.backward()
#update
optimizer.step()
optimizer.zero_grad()
if(epoch+1)%10 ==0:
print(f'epoch: {epoch+1},loss = {loss.item():.4f}')
#plot
predicted = model(x).detach().numpy()
plt.plot(x_numpy,y_numpy,'ro')
plt.plot(x_numpy,predicted,'b')
plt.show()
Logistic Regression
import torch
import torch.nn as nn
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 0)prepare data
bc = datasets.load_breast_cancer()
x,y = bc.data,bc.target
n_samples,n_features = x.shape
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=1234)
#sclae
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
x_train = torch.from_numpy(x_train.astype(np.float32))
x_test = torch.from_numpy(x_test.astype(np.float32))
y_train = torch.from_numpy(y_train.astype(np.float32))
y_test = torch.from_numpy(y_test.astype(np.float32))
y_train = y_train.view(y_train.shape[0],1)
y_test = y_test.view(y_test.shape[0],1)
# 1)model
# f = wx+b, sigmod at the end
class LogisticRegression(nn.Module):
def __init__(self,n_input_features):
super(LogisticRegression,self).__init__()
self.linear = nn.Linear(n_input_features,1)
def forward(self,x):
y_predicted = torch.sigmoid(self.linear(x))
return y_predicted
model = LogisticRegression(n_features)
# 2)loss and optimizer
learning_rate = 0.03
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 3)training loop
num_epoch = 10000
for epoch in range(num_epoch):
#forward pass and loss
y_predicted = model(x_train)
loss = criterion(y_predicted,y_train)
#backward pass
loss.backward()
#update
optimizer.step()
#zero gradients
optimizer.zero_grad()
if (epoch+1)%10==0:
print(f'epoch:{epoch+1},loss = {loss.item():.4f}')
with torch.no_grad():
y_predicted = model(x_test)
y_predicted_cls = y_predicted.round()
acc = y_predicted_cls.eq(y_test).sum()/float(y_test.shape[0])
print(f'accuracy = {acc:.4f}')
Dataset and Dataloader
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
class WineDataSet(Dataset):
def __init__(self):
# data loading
xy = np.loadtxt("K:\\Cloud\\data\\nlp\\pytorchTutorial\\data\\wine\\wine.csv", delimiter=",", dtype=np.float32,
skiprows=1)
self.x = torch.from_numpy(xy[:, 1:])
self.y = torch.from_numpy(xy[:, [0]])
self.n_samplses = xy.shape[0]
def __getitem__(self, index):
# dataset[0]
return self.x[index], self.y[index]
def __len__(self):
# len(dataset)
return self.n_samplses
dataset = WineDataSet()
dataloader = DataLoader(dataset=dataset, batch_size=4, shuffle=True, num_workers=0)
# datatiter = iter(dataloader)
# data = datatiter.next()
# features, labels = data
# print(features,labels)
# training loop
num_epochs = 2
total_samples = len(dataset)
n_iterations = math.ceil(total_samples / 4)
print(total_samples, n_iterations)
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(dataloader):
# forward backward, update
if (i + 1) % 5 == 0:
print(f'epoch{epoch + 1}/{num_epochs},step {i + 1}/{n_iterations},inputs {inputs.shape}')
Dataset transformers
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
class WineDataSet(Dataset):
def __init__(self,transform=None):
# data loading
xy = np.loadtxt("K:\\Cloud\\data\\nlp\\pytorchTutorial\\data\\wine\\wine.csv", delimiter=",", dtype=np.float32,skiprows=1)
self.x = xy[:, 1:]
self.y = xy[:, [0]]
self.n_samplses = xy.shape[0]
self.transform = transform
def __getitem__(self, index):
# dataset[0]
sample = self.x[index],self.y[index]
if self.transform:
sample = self.transform(sample)
return sample
def __len__(self):
# len(dataset)
return self.n_samplses
class ToTensor:
def __call__(self,sample):
inputs,targets = sample
return torch.from_numpy(inputs),torch.from_numpy(targets)
class MulTransform:
def __init__(self,factor):
self.factor = factor
def __call__(self,sample):
inputs,target = sample
inputs *= self.factor
return inputs,target
dataset = WineDataSet(transform=None)
first_data = dataset[0]
features,labels = first_data
print(features)
print(type(features),type(labels))
composed = torchvision.transforms.Compose([ToTensor(),MulTransform(2)])
dataset = WineDataSet(transform=composed)
first_data = dataset[0]
features,labels = first_data
print(features)
print(type(features),type(labels))
SoftMax and Crossentropy

import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
import torch.nn as nn
def softmax(x):
return np.exp(x)/np.sum(np.exp(x),axis=0)
x = np.array([2.0,1.0,0.1])
outputs = softmax(x)
print('softmax numpy:',outputs)
x = torch.tensor([2.0,1.0,0.1])
outputs = torch.softmax(x,dim=0)
print(outputs)
def cross_entropy(actual,predicted):
loss = -np.sum(actual * np.log(predicted))
return loss
Y = np.array([1,0,0])
Y_pred_good = np.array([0.7,0.2,0.1])
Y_pred_bad = np.array([0.1,0.3,0.6])
l1 = cross_entropy(Y,Y_pred_good)
l2 = cross_entropy(Y,Y_pred_bad)
print(f'Loss1 numpy:{l1:.4f}')
print(f'Loss2 numpy:{l2:.4f}')
loss = nn.CrossEntropyLoss()
#3 samples
Y = torch.tensor([2,0,1])
y_pred_good = torch.tensor([[0.1,1.0,2.1],[2.0,1.0,0.1],[0.1,3.0,0.1]],dtype=torch.float32)
y_pred_bad = torch.tensor([[2.1,1.0,0.1],[0.1,1.0,2.1],[0.1,3.0,0.1]],dtype=torch.float32)
l1 = loss(y_pred_good,Y)
l2 = loss(y_pred_bad,Y)
print(l1.item())
print(l2.item())
_,pred1 = torch.max(y_pred_good,1)
_,pred2 = torch.max(y_pred_bad,1)
print(pred1)
print(pred2)
Neural network
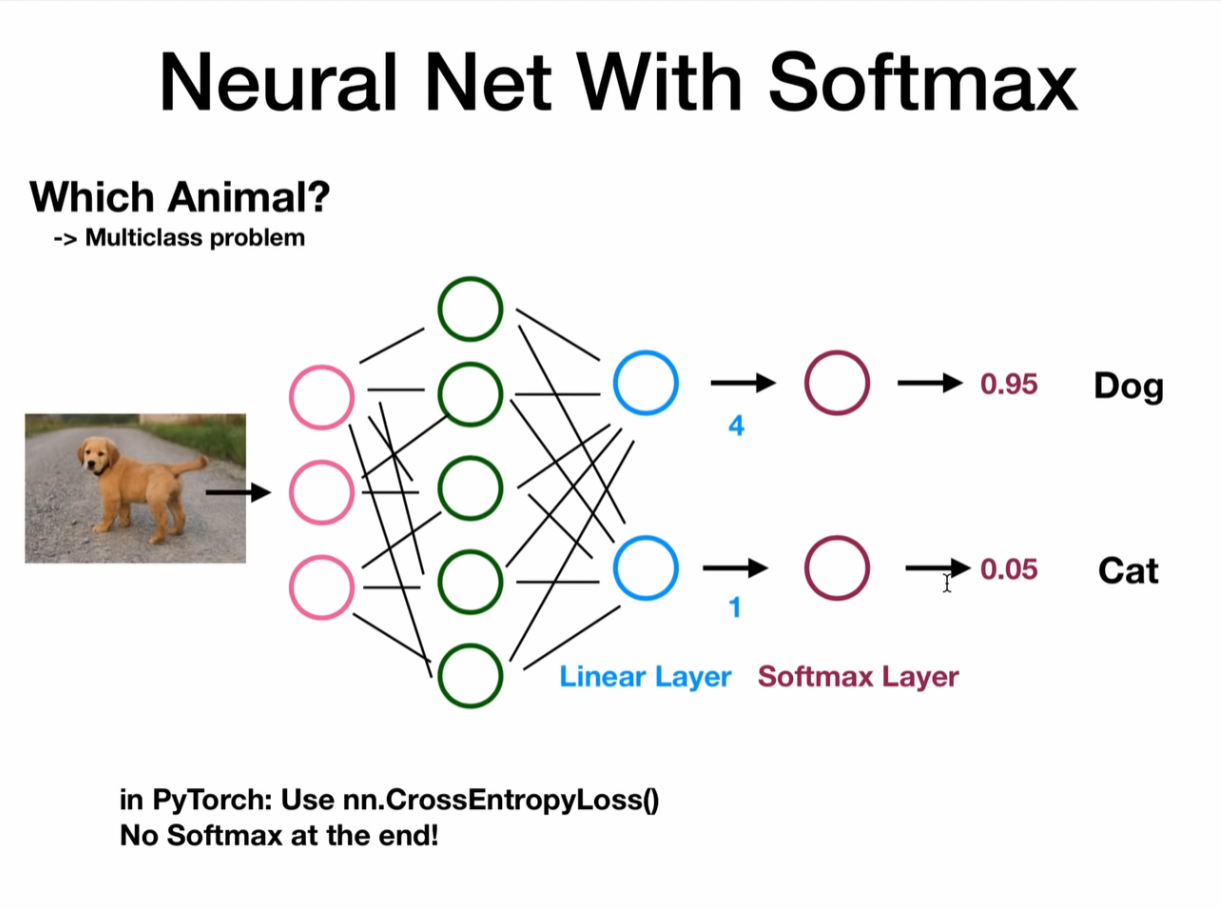
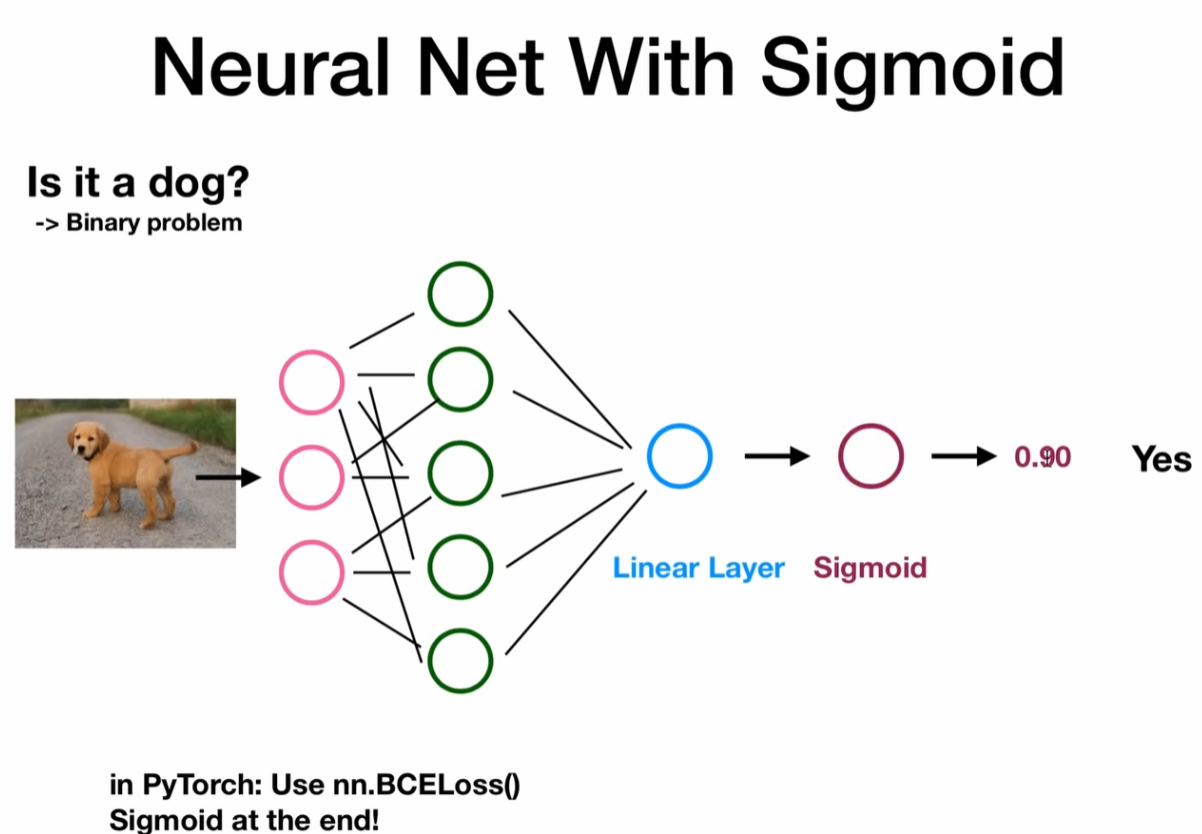
import torch
import torch.nn as nn
# Multiclass problem
class NeuralNet2(nn.Module):
def __init__(self,input_size,hidden_size,num_classes):
super(NeuralNet2,self).__init__()
self.linear1 = nn.Linear(input_size,hidden_size)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(hidden_size,num_classes)
def forward(self,x):
out = self.linear1(x)
out = self.relu(out)
out = self.linear2(out)
y_pred = torch.sigmoid(out)
return y_pred
model = NeuralNet2(input_size=28*28,hidden_size=5,num_classes=1)
criterion = nn.CrossEntropyLoss()
Activation Function
import torch
import torch.nn as nn
import torch.nn.functional as F
# option1 create nn modules
class NeuralNet2(nn.Module):
def __init__(self,input_size,hidden_size,num_classes):
super(NeuralNet2,self).__init__()
self.linear1 = nn.Linear(input_size,hidden_size)
self.relu = nn.ReLU()
#nn.Sigmoid
#nn.Softmax
#nn.TanH
#nn.LeakyReLU
self.linear2 = nn.Linear(hidden_size,num_classes)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
out = self.linear1(x)
out = self.relu(out)
out = self.linear2(out)
out = self.sigmoid(out)
return out
# option 2 use activation functions directly in forward pass
class NeuralNet(nn.Module):
def __init__(self,input_size,hidden_size):
super(NeuralNet,self).__init__()
#F.leaky_relu()
self.linear = nn.Linear(input_size,hidden_size)
self.linear2 = nn.Linear(hidden_size,1)
def forward(self,x):
out = torch.relu(self.linear1(x))
out = torch.simoid(self.linear2(out))
return out
Feed-Forward Neural Net
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# device config
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#hyper parameters
input_size = 784 #28*28
hidden_size = 100
num_classes = 10
num_epochs = 2
batch_size = 100
learning_rate = 0.001
# MNIST
train_dataset = torchvision.datasets.MNIST(root="./data",train=True,transform=transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.MNIST(root="./data",train=False,transform=transforms.ToTensor())
# DataLoader,Transformation
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
examples = iter(train_loader)
samples,labels = examples.next()
print(samples.shape,labels.shape)
for i in range(6):
plt.subplot(2,3,i+1)
plt.imshow(samples[i][0],cmap='gray')
class NeuralNet(nn.Module):
def __init__(self,input_size,hidden_size,num_classes):
super(NeuralNet,self).__init__()
self.l1 = nn.Linear(input_size,hidden_size)
self.relu = nn.ReLU()
self.l2 = nn.Linear(hidden_size,num_classes)
def forward(self,x):
out = self.l1(x)
out = self.relu(out)
out = self.l2(out)
return out
model = NeuralNet(input_size,hidden_size,num_classes)
model=model.to(device)
## loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
#training loo
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i,(images,labels) in enumerate(train_loader):
#100,1,28,28
#100,784
images = images.reshape(-1,28*28).to(device)
labels = labels.to(device)
#forward
outputs = model(images)
loss = criterion(outputs,labels)
#backwards
optimizer.zero_grad()
loss.backward()
optimizer.step()
if(i+1)%100==0:
print(f'epoch {epoch+1}/{num_epochs},step {i+1}.n_ntotal_steps, loss = {loss.item():.4f}')
# test
with torch.no_grad():
n_correct = 0
n_samples = 0
for images,labels in test_loader:
images = images.reshape(-1,28*28).to(device)
labels = labels.to(device)
outputs = model(images)
#value,index
_,predictions = torch.max(outputs,1)
n_samples+= labels.shape[0]
n_correct = (predictions == labels).sum().item()
acc = 100.0* n_correct/n_samples
print(f'accuracy = {acc}')
CNN
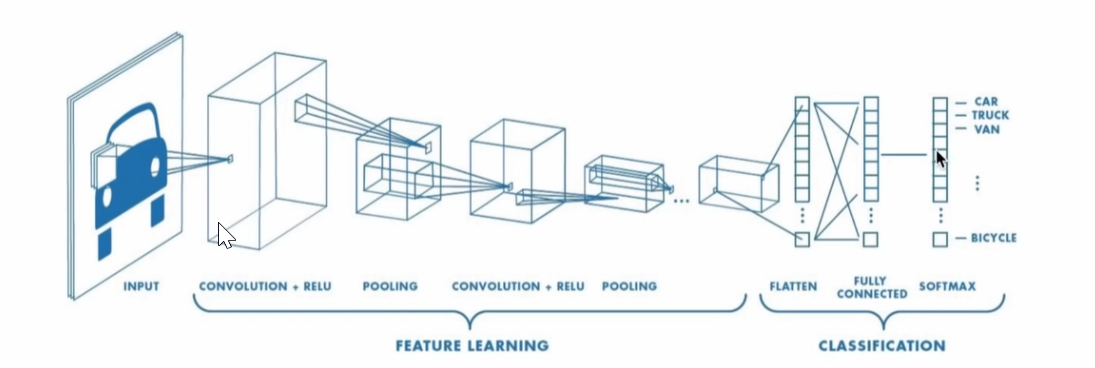
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
num_epochs = 5
batch_size = 4
learning_rate = 0.001
# dataset has PILImage images of range [0, 1].
# We transform them to Tensors of normalized range [-1, 1]
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# CIFAR10: 60000 32x32 color images in 10 classes, with 6000 images per class
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size,
shuffle=False)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(train_loader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# -> n, 3, 32, 32
x = self.pool(F.relu(self.conv1(x))) # -> n, 6, 14, 14
x = self.pool(F.relu(self.conv2(x))) # -> n, 16, 5, 5
x = x.view(-1, 16 * 5 * 5) # -> n, 400
x = F.relu(self.fc1(x)) # -> n, 120
x = F.relu(self.fc2(x)) # -> n, 84
x = self.fc3(x) # -> n, 10
return x
model = ConvNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# origin shape: [4, 3, 32, 32] = 4, 3, 1024
# input_layer: 3 input channels, 6 output channels, 5 kernel size
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 2000 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{n_total_steps}], Loss: {loss.item():.4f}')
print('Finished Training')
PATH = './cnn.pth'
torch.save(model.state_dict(), PATH)
with torch.no_grad():
n_correct = 0
n_samples = 0
n_class_correct = [0 for i in range(10)]
n_class_samples = [0 for i in range(10)]
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
# max returns (value ,index)
_, predicted = torch.max(outputs, 1)
n_samples += labels.size(0)
n_correct += (predicted == labels).sum().item()
for i in range(batch_size):
label = labels[i]
pred = predicted[i]
if (label == pred):
n_class_correct[label] += 1
n_class_samples[label] += 1
acc = 100.0 * n_correct / n_samples
print(f'Accuracy of the network: {acc} %')
for i in range(10):
acc = 100.0 * n_class_correct[i] / n_class_samples[i]
print(f'Accuracy of {classes[i]}: {acc} %')
Transfer Learning
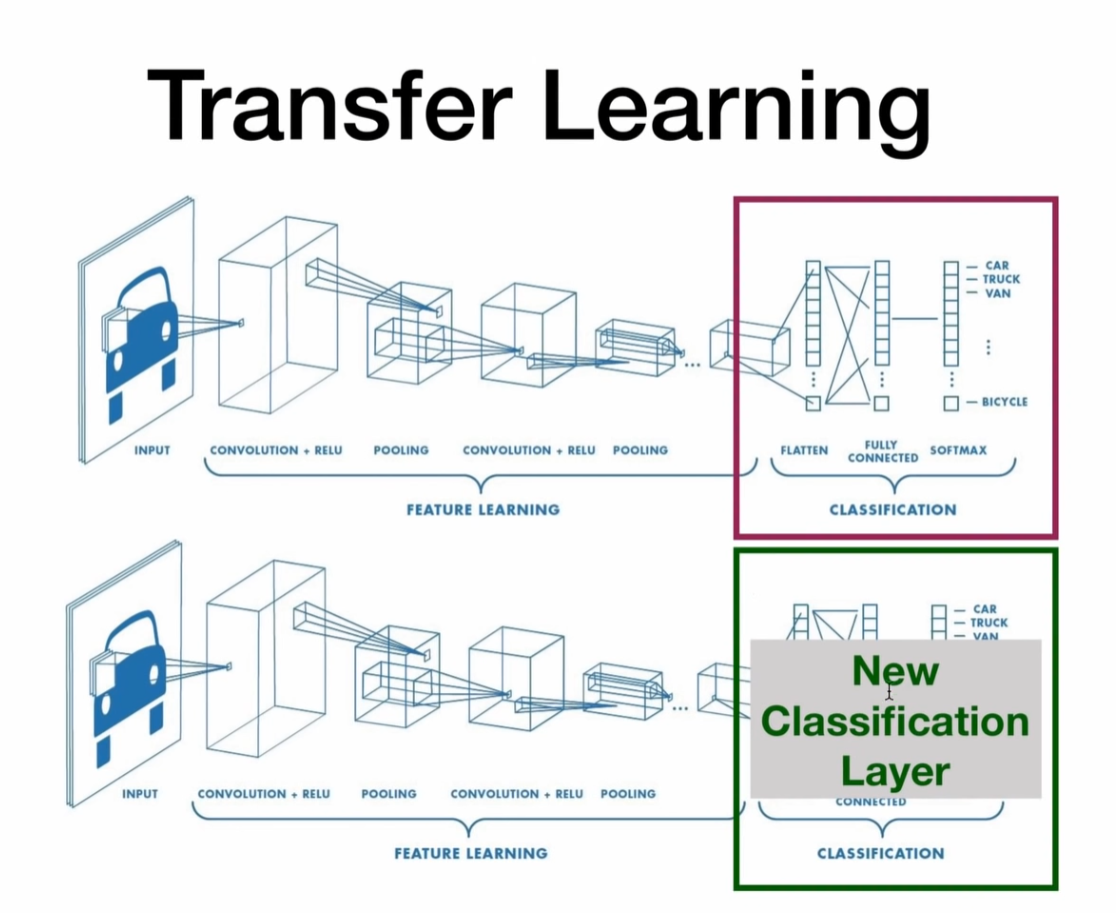
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.25, 0.25, 0.25])
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=0)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(class_names)
def imshow(inp, title):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
plt.title(title)
plt.show()
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
#### Finetuning the convnet ####
# Load a pretrained model and reset final fully connected layer.
model = models.resnet18(pretrained=True)
num_ftrs = model.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model.fc = nn.Linear(num_ftrs, 2)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer = optim.SGD(model.parameters(), lr=0.001)
# StepLR Decays the learning rate of each parameter group by gamma every step_size epochs
# Decay LR by a factor of 0.1 every 7 epochs
# Learning rate scheduling should be applied after optimizer’s update
# e.g., you should write your code this way:
# for epoch in range(100):
# train(...)
# validate(...)
# scheduler.step()
step_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
model = train_model(model, criterion, optimizer, step_lr_scheduler, num_epochs=25)
#### ConvNet as fixed feature extractor ####
# Here, we need to freeze all the network except the final layer.
# We need to set requires_grad == False to freeze the parameters so that the gradients are not computed in backward()
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model_conv = train_model(model_conv, criterion, optimizer_conv,
exp_lr_scheduler, num_epochs=25)
Tensorboard
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
############## TENSORBOARD ########################
import sys
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
# default `log_dir` is "runs" - we'll be more specific here
writer = SummaryWriter('runs/mnist1')
###################################################
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
input_size = 784 # 28x28
hidden_size = 500
num_classes = 10
num_epochs = 1
batch_size = 64
learning_rate = 0.001
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
examples = iter(test_loader)
example_data, example_targets = examples.next()
for i in range(6):
plt.subplot(2,3,i+1)
plt.imshow(example_data[i][0], cmap='gray')
#plt.show()
############## TENSORBOARD ########################
img_grid = torchvision.utils.make_grid(example_data)
writer.add_image('mnist_images', img_grid)
#writer.close()
#sys.exit()
###################################################
# Fully connected neural network with one hidden layer
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.input_size = input_size
self.l1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.l2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.l1(x)
out = self.relu(out)
out = self.l2(out)
# no activation and no softmax at the end
return out
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
############## TENSORBOARD ########################
writer.add_graph(model, example_data.reshape(-1, 28*28))
#writer.close()
#sys.exit()
###################################################
# Train the model
running_loss = 0.0
running_correct = 0
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# origin shape: [100, 1, 28, 28]
# resized: [100, 784]
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
running_correct += (predicted == labels).sum().item()
if (i+1) % 100 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{n_total_steps}], Loss: {loss.item():.4f}')
############## TENSORBOARD ########################
writer.add_scalar('training loss', running_loss / 100, epoch * n_total_steps + i)
running_accuracy = running_correct / 100 / predicted.size(0)
writer.add_scalar('accuracy', running_accuracy, epoch * n_total_steps + i)
running_correct = 0
running_loss = 0.0
###################################################
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
class_labels = []
class_preds = []
with torch.no_grad():
n_correct = 0
n_samples = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
# max returns (value ,index)
values, predicted = torch.max(outputs.data, 1)
n_samples += labels.size(0)
n_correct += (predicted == labels).sum().item()
class_probs_batch = [F.softmax(output, dim=0) for output in outputs]
class_preds.append(class_probs_batch)
class_labels.append(predicted)
# 10000, 10, and 10000, 1
# stack concatenates tensors along a new dimension
# cat concatenates tensors in the given dimension
class_preds = torch.cat([torch.stack(batch) for batch in class_preds])
class_labels = torch.cat(class_labels)
acc = 100.0 * n_correct / n_samples
print(f'Accuracy of the network on the 10000 test images: {acc} %')
############## TENSORBOARD ########################
classes = range(10)
for i in classes:
labels_i = class_labels == i
preds_i = class_preds[:, i]
writer.add_pr_curve(str(i), labels_i, preds_i, global_step=0)
writer.close()
###################################################
Save & Load
import torch
import torch.nn as nn
''' 3 DIFFERENT METHODS TO REMEMBER:
- torch.save(arg, PATH) # can be model, tensor, or dictionary
- torch.load(PATH)
- torch.load_state_dict(arg)
'''
''' 2 DIFFERENT WAYS OF SAVING
# 1) lazy way: save whole model
torch.save(model, PATH)
# model class must be defined somewhere
model = torch.load(PATH)
model.eval()
# 2) recommended way: save only the state_dict
torch.save(model.state_dict(), PATH)
# model must be created again with parameters
model = Model(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
'''
class Model(nn.Module):
def __init__(self, n_input_features):
super(Model, self).__init__()
self.linear = nn.Linear(n_input_features, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = Model(n_input_features=6)
# train your model...
####################save all ######################################
for param in model.parameters():
print(param)
# save and load entire model
FILE = "model.pth"
torch.save(model, FILE)
loaded_model = torch.load(FILE)
loaded_model.eval()
for param in loaded_model.parameters():
print(param)
############save only state dict #########################
# save only state dict
FILE = "model.pth"
torch.save(model.state_dict(), FILE)
print(model.state_dict())
loaded_model = Model(n_input_features=6)
loaded_model.load_state_dict(torch.load(FILE)) # it takes the loaded dictionary, not the path file itself
loaded_model.eval()
print(loaded_model.state_dict())
###########load checkpoint#####################
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
checkpoint = {
"epoch": 90,
"model_state": model.state_dict(),
"optim_state": optimizer.state_dict()
}
print(optimizer.state_dict())
FILE = "checkpoint.pth"
torch.save(checkpoint, FILE)
model = Model(n_input_features=6)
optimizer = optimizer = torch.optim.SGD(model.parameters(), lr=0)
checkpoint = torch.load(FILE)
model.load_state_dict(checkpoint['model_state'])
optimizer.load_state_dict(checkpoint['optim_state'])
epoch = checkpoint['epoch']
model.eval()
# - or -
# model.train()
print(optimizer.state_dict())
# Remember that you must call model.eval() to set dropout and batch normalization layers
# to evaluation mode before running inference. Failing to do this will yield
# inconsistent inference results. If you wish to resuming training,
# call model.train() to ensure these layers are in training mode.
""" SAVING ON GPU/CPU
# 1) Save on GPU, Load on CPU
device = torch.device("cuda")
model.to(device)
torch.save(model.state_dict(), PATH)
device = torch.device('cpu')
model = Model(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location=device))
# 2) Save on GPU, Load on GPU
device = torch.device("cuda")
model.to(device)
torch.save(model.state_dict(), PATH)
model = Model(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.to(device)
# Note: Be sure to use the .to(torch.device('cuda')) function
# on all model inputs, too!
# 3) Save on CPU, Load on GPU
torch.save(model.state_dict(), PATH)
device = torch.device("cuda")
model = Model(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location="cuda:0")) # Choose whatever GPU device number you want
model.to(device)
# This loads the model to a given GPU device.
# Next, be sure to call model.to(torch.device('cuda')) to convert the model’s parameter tensors to CUDA tensors
"""
版权声明:本文为exu131g原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。