视频压缩和分析方面数据集 Tencent Video Dataset (TVD)
Tencent Video Dataset (TVD): A Video Dataset for Learning-based Visual Data Compression and Analysis
Link:https://multimedia.tencent.com/resources/tvd
Paper:https://arxiv.org/abs/2105.05961
2022/6/11:其实没有啥内容就是一个视频数据集而已,稍微试了一下27.5GB太大了还是不下了,UVG多香啊。
Abstract
近年来,基于学习的可视数据压缩和分析收到了工业界和学界的高度关注。更多的训练和测试数据集,尤其是高质量的视频数据集,对于相关的研究和标准化活动是十分需要的。腾讯视频数据集(TVD)的建立是为了服务于各种任务,如训练基于神经网络的编码工具和测试机器视觉任务,包括目标检测和跟踪。TVD包含86个视频序列,内容覆盖多样。每个视频序列由65帧4K (3840x2160)空间分辨率的帧组成。本文介绍了该数据集的详细内容,以及它在用VVC和HEVC视频编解码器压缩时的性能。
Index Term: 4K数据集,视频压缩,机器学习,面向机器的视频编码,目标检测,目标跟踪
1. Introduction
近年来,很多新的机器学习技术在可视数据压缩和分析领域带来了巨大的提升。在这些领域,深度神经网络或广泛基于学习的方法通过数据驱动的方法提高了压缩效率和机器任务的准确性。
高效的基于学习的方法通常是通过广泛的培训过程来设计的。因此,高质量的视频数据集是相关研究和标准化活动的迫切需要。JPEG人工智能,基于JVET神经网络的视频编码(NNVC)和MPEG机器视频编码(VCM)只是少数几个例子。腾讯视频数据集(TVD)[1]是为各种任务而建立的,例如训练基于神经网络的编码工具和测试机器视觉任务,包括目标检测和跟踪。
TVD包含86个视频序列,内容覆盖多样。每个视频序列由65帧以3840x2160空间分辨率组成。这个视频数据集已在JVET NNVC的科研探索中被用作训练集。
对于目标检测研究,166幅图像从TVD采样,空间分辨率为1920x1080,格式为rgb24 png。提供了这些图像的边框注释。这些带注释的图像已经作为测试集[3]包含在MPEG VCM的常见测试条件中。
2. Video Data Collection
TVD中的所有序列都使用Red Helium 8k, Red Monstro 8k和Blackmagic
URSA Mini Pro 12K得到的。序列被转码,然后使用FFmpeg[4]转换为YUV 4:2:0颜色格式。相同内容的更高分辨率格式是可能的,因为某些源视频剪辑以更高分辨率(至少8K)捕获。
这个数据集包含各种带有静态或移动对象的场景。TVD网站[1]提供了整个视频数据集的缩略图。图1给出了TVD中序列的一些样本帧。

3. Evaluation on Video Compressiopon Tools
当一个视频序列被一个典型的视频编解码器压缩时,它的变现是收到关注的。在本文中,在TVD上的视频编码解码使用了VVC参考软件VTM-11.0和HEVC参考软件HM16.23。文中报告总体结果统计数据以及一些选定序列的结果。
3.1 Compression Results and Comparison
使用配置 AI、RA、LDB、LDP,GP设置为{22,27,32,37,42},VTM-11.0和HM-16.23都在TVD数据上运行编解码过程,使用默认的编码参数。在后续的表格中,给出了整个数据集的平均统计量。对于HM-16.23,不同QPs下Y/U/V通道的PSNR平均值如表I和表II所示。对VTM -11.0,不同QPs下Y/U/V信道的PSNR平均值见表III和表IV。
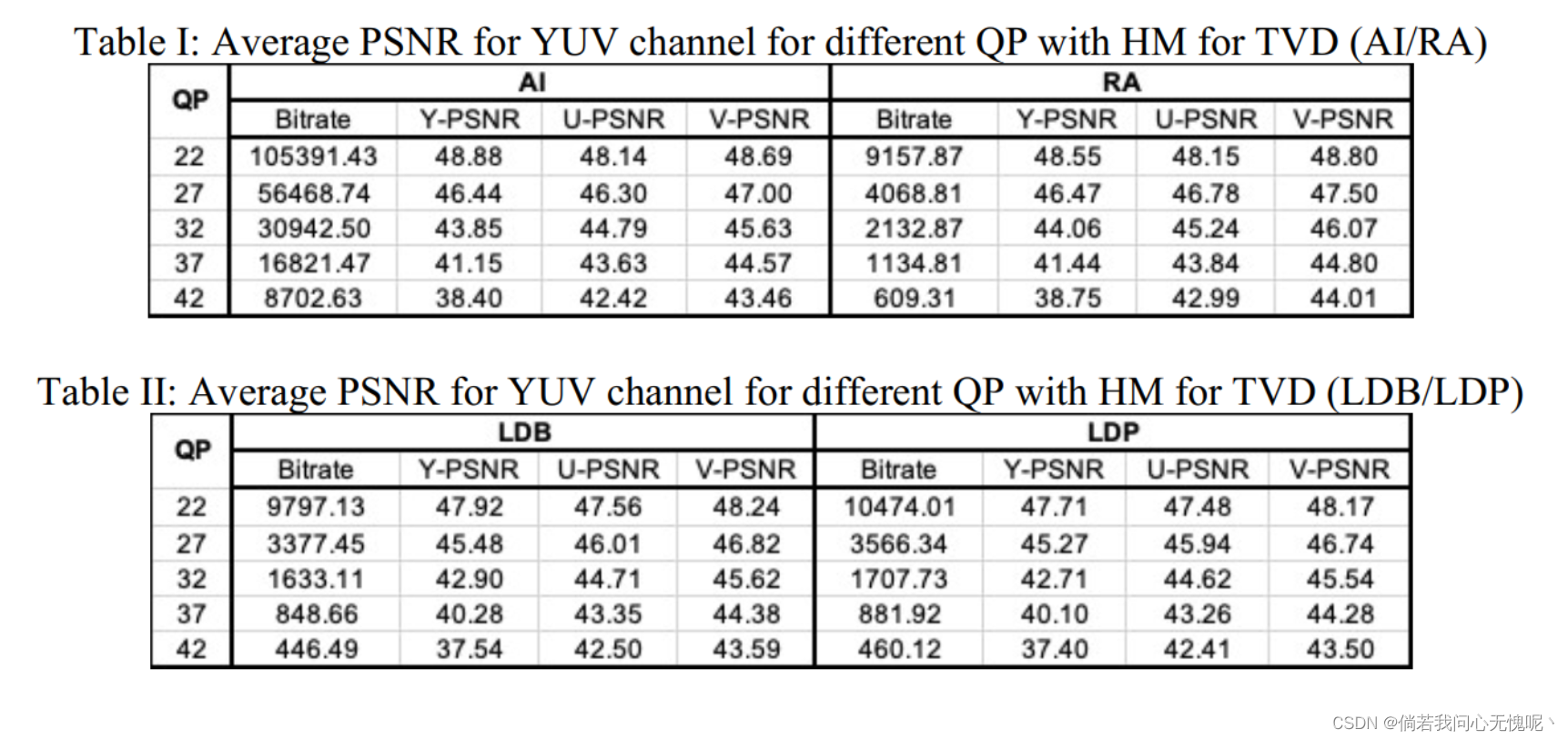
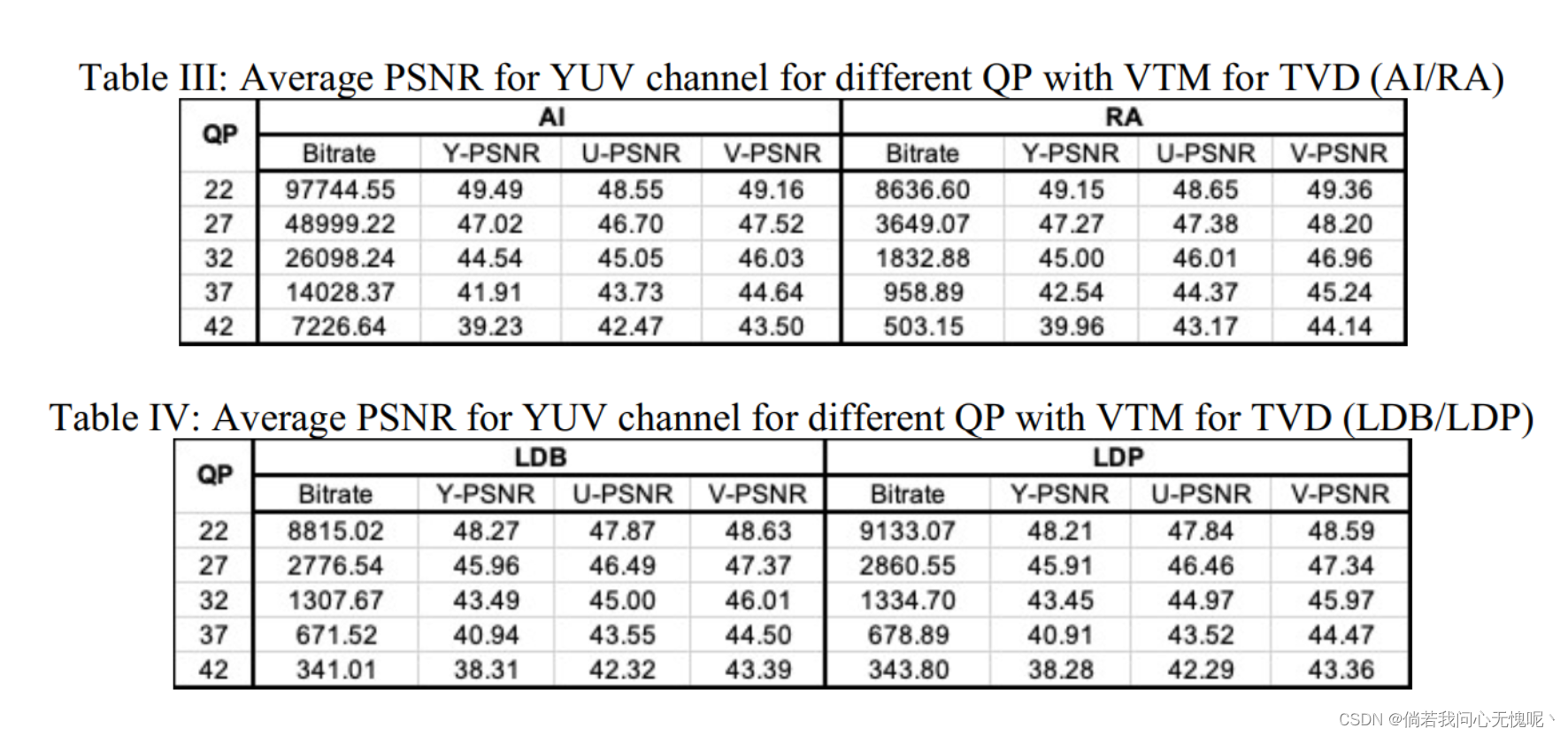
比特流就差这么点??在每个模式上差的感觉就是百分之十不到啊,HEVC和VVC之间的差别就这点嘛。
3.2 Comparison between VTM-11.0 and HM-16.23
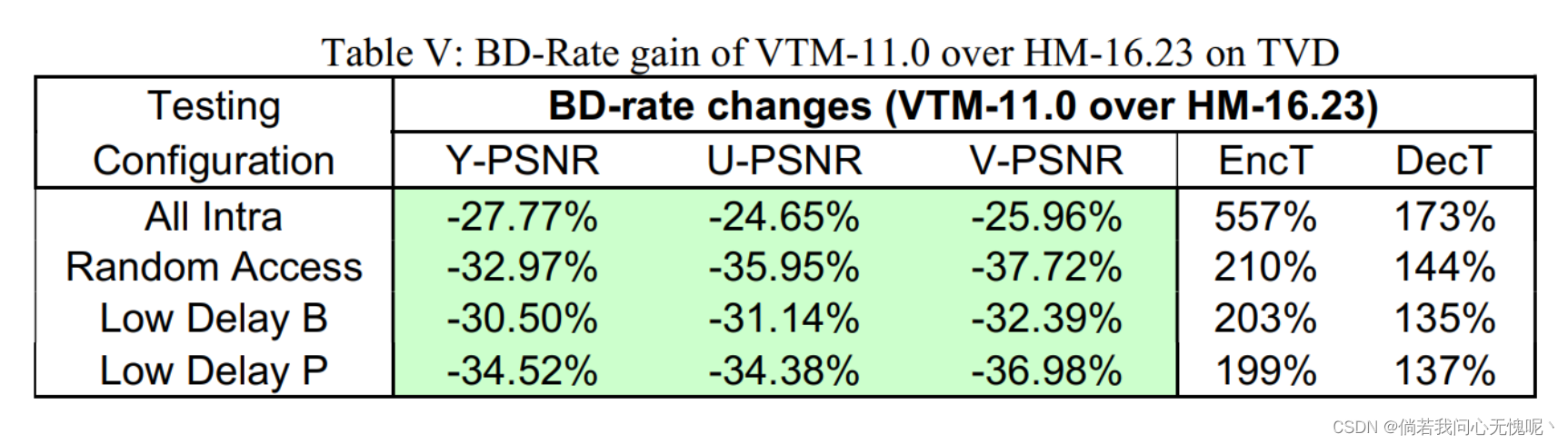
VTM-11.0和HM-16.23之间的整体BD-Rate[7]性能比较如表V所示。结果表明,在TVD的所有YUV通道中,VTM-11.0比HM-16.23提供更好的BD-Rate结果。与HM软件相比,在RA配置下,使用VTM参考软件可以实现大约33%的bd率降低。这些测试中的失真度指标被选择为PSNR。
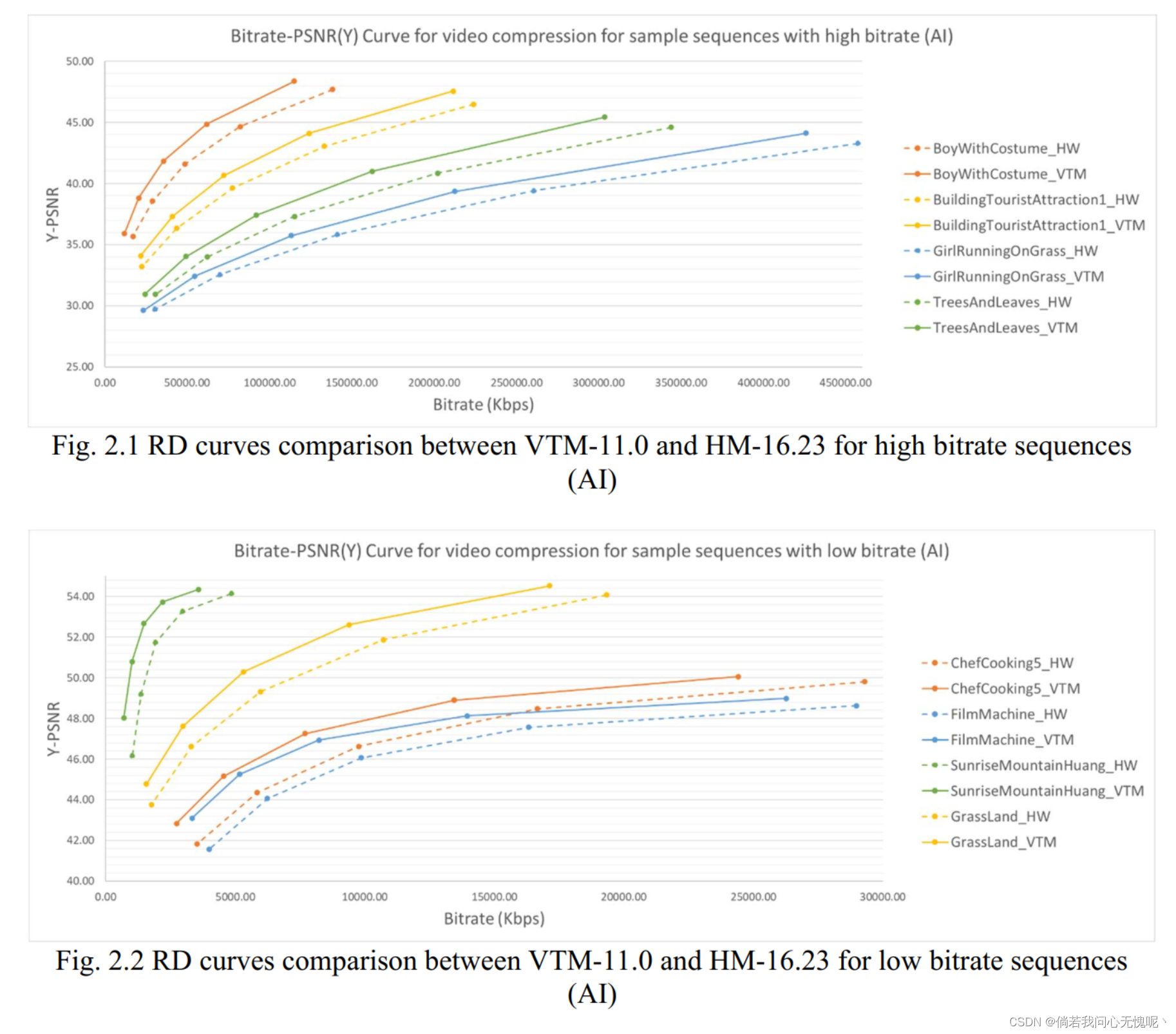
显示整个视频数据集的RD曲线需要太多的工作,可能没有预期的信息量大。如图2至图5所示,本文给出了VTM-11.0和HM-16.23在TVD上视频编/解码的一组序列的RD曲线,以比较VTM-11.0和HM-16.23在TVD上的视频编/解码性能。