ECharts大屏可视化
文章目录
ECharts大屏可视化
一、项目概述
1.1 项目介绍
本项目是一个基于 Python + Flask + Echarts 打造的一个疫情监控系统,涉及到的技术有:
- Python 网络爬虫
- 使用 Python 与 MySQL 数据库交互
- 使用 Flask 构建 web 项目
- 基于 Echarts 数据可视化展示
效果展示:
1.2 项目架构
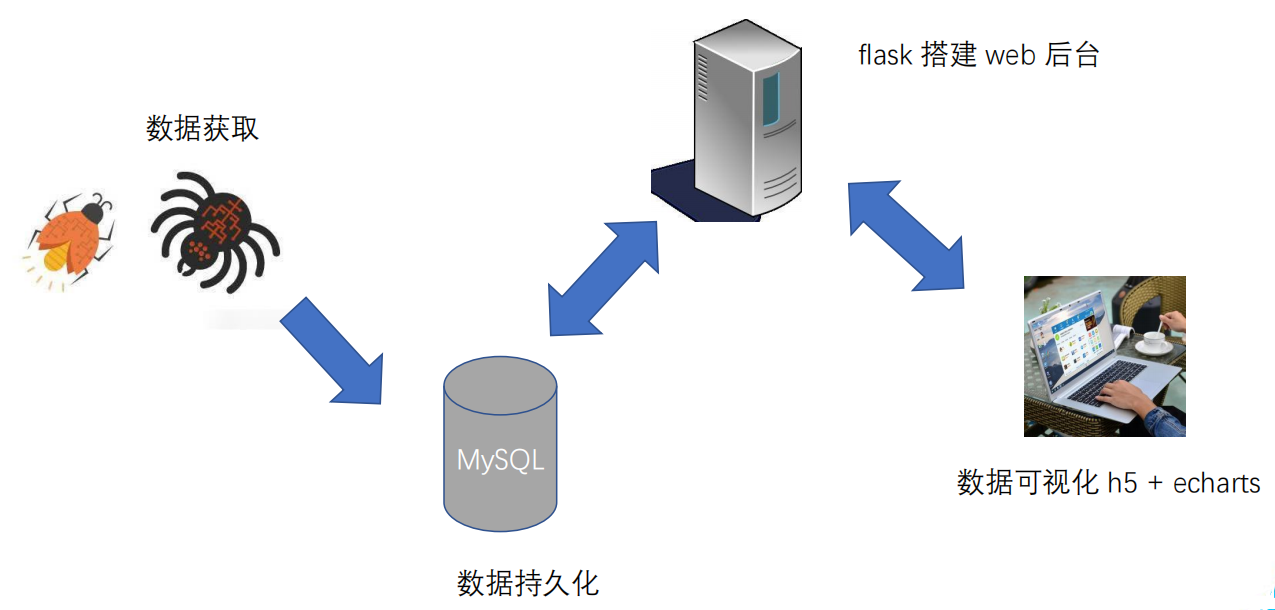
1.3 使用环境
- Python 3.10.2(3.x以上版本)
- Python库:requests、pymysql、time、json、hashlib、traceback、bs4、flask、jieba、string
- MySQL(这里使用phpstudy_pro集成环境 MySQL5.7.26)
- MySQL可视化工具 MySQL-Front
- Visual Studio Code (Python/前端 编辑工具)
- 浏览器:Google Chrome
二、数据获取
1.获取腾讯数据
1.1数据爬取
网址:https://news.qq.com/zt2020/page/feiyan.htm#/
首先我们打开网址,进入网页:

现在的网页不会把数据直接放到网页里,而是通过接口从后台向网页传输数据,只要找到数据接口,我们发送请求,就可以得到数据了。
下面我们来找接口,按 F12打开检查面板,找到 network 选项,然后刷新页面,选择Fetch/XHR,最上面的两个就是我们要找的接口了。
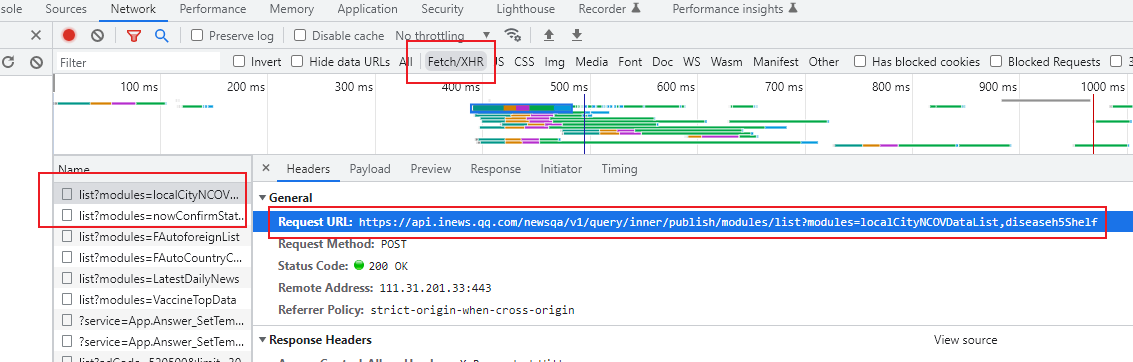
有了接口,接下来对数据进行分析与处理
数据结构

获取数据逻辑:


1.2数据存储
📖创建数据库
这里我们用MySQL 进行数据储存,首先创建 cov 数据库;然后创建两个表 history 和 details。
其中:history 表存储每日总数据,details 表存储每日详细数据。代码如下:
#创建数据库
create database cov;
use cov;
#创建history表
CREATE TABLE `history` (
`ds` datetime NOT NULL COMMENT '日期',
`confirm` int(10) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(10) DEFAULT NULL COMMENT '当日新增确诊',
`confirm_now` int(10) DEFAULT NULL COMMENT '剩余确诊',
`suspect` int(10) DEFAULT NULL COMMENT '剩余疑似',
`suspect_add` int(10) DEFAULT NULL COMMENT '当日新增疑似',
`heal` int(10) DEFAULT NULL COMMENT '累计治愈',
`heal_add` int(10) DEFAULT NULL COMMENT '当日新增治愈',
`dead` int(10) DEFAULT NULL COMMENT '累计死亡',
`dead_add` int(10) DEFAULT NULL COMMENT '当日新增死亡',
PRIMARY KEY (`ds`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
#创建 details表
CREATE TABLE `details` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`update_time` datetime DEFAULT NULL COMMENT '数据最后更新时间',
`province` varchar(50) DEFAULT NULL COMMENT '省',
`city` varchar(50) DEFAULT NULL COMMENT '市',
`confirm` int(10) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(10) DEFAULT NULL COMMENT '新增确诊',
`confirm_now` int(10) DEFAULT NULL COMMENT '现有确诊',
`heal` int(10) DEFAULT NULL COMMENT '累计治愈',
`dead` int(10) DEFAULT NULL COMMENT '累计死亡',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这里我们使用的是MySQL-Front对数据库进行管理,将上面的SQL语句复制下来,粘贴到SQL编辑器里
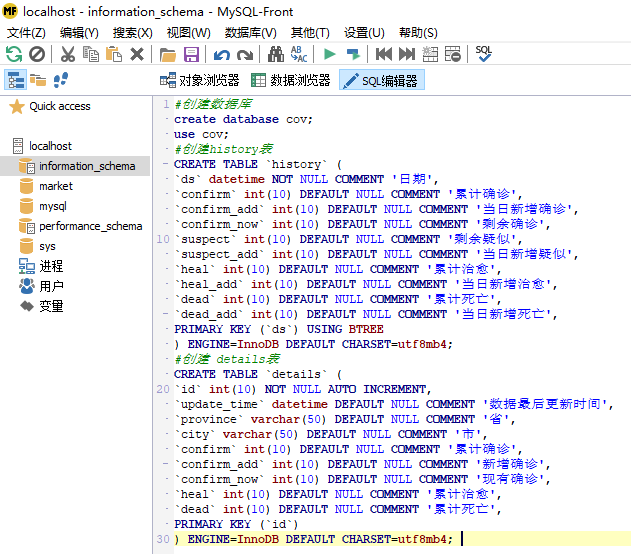
点击运行,数据库和两个表格就创建好了
📖连接数据库
-
使用 pymysql 模块与数据库交互
-
安装: pip install pymysql
-
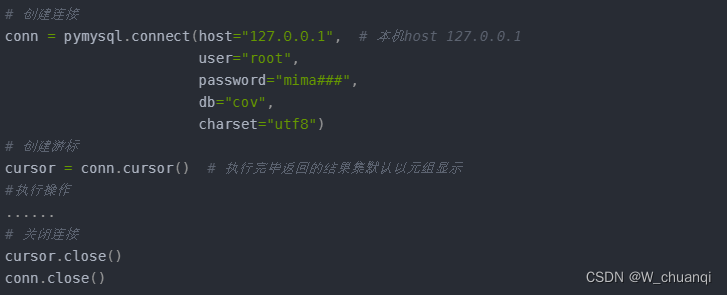
① 建立连接
-
② 创建游标
-
③ 执行操作
-
④ 关闭连接
-
代码如下:
📖插入和更新数据
插入数据
def get_tencent_data():
"""
:return: 返回历史数据和当日详细数据
"""
url_det = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=diseaseh5Shelf'
url_his = "https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=chinaDayList,chinaDayAddList,nowConfirmStatis,provinceCompare"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
r_det = requests.get(url_det, headers)
r_his = requests.get(url_his, headers)
res_det = json.loads(r_det.text) # json字符串转字典
res_his = json.loads(r_his.text)
data_det = res_det['data']['diseaseh5Shelf']
data_his = res_his['data']
history = {} # 历史数据
for i in data_his["chinaDayList"]:
ds = i["y"]+"."+i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式,不然插入数据库会报错,数据库是datetime类型
confirm = i["confirm"]
confirm_now = i["nowConfirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {"confirm": confirm, "confirm_now": confirm_now,
"suspect": suspect, "heal": heal, "dead": dead}
for i in data_his["chinaDayAddList"]:
ds = i["y"]+"."+i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup)
confirm_add = i["confirm"]
suspect_add = i["suspect"]
heal_add = i["heal"]
dead_add = i["dead"]
history[ds].update({"confirm_add": confirm_add, "suspect_add": suspect_add,
"heal_add": heal_add, "dead_add": dead_add})
details = [] # 当日详细数据
update_time = data_det["lastUpdateTime"]
data_country = data_det["areaTree"] # list 之前有25个国家,现在只有中国
data_province = data_country[0]["children"] # 中国各省
for pro_infos in data_province:
province = pro_infos["name"] # 省名
for city_infos in pro_infos["children"]:
city = city_infos["name"] # 城市名
confirm = city_infos["total"]["confirm"] # l累计确诊
confirm_add = city_infos["today"]["confirm"] # 新增确诊
confirm_now = city_infos["total"]["nowConfirm"] # 现有确诊
heal = city_infos["total"]["heal"] # 累计治愈
dead = city_infos["total"]["dead"] # 累计死亡
details.append([update_time, province, city, confirm,
confirm_add, confirm_now, heal, dead])
return history, details
更新数据
def update_details():
"""
更新 details 表
:return:
"""
cursor = None
conn = None
try:
li = get_tencent_data()[1] # 0 是历史数据字典,1 最新详细数据列表
conn, cursor = get_conn()
sql = "insert into details(update_time,province,city,confirm,confirm_add,confirm_now,heal,dead) " \
"values(%s,%s,%s,%s,%s,%s,%s,%s)"
# 对比当前最大时间戳
sql_query = 'select %s=(select update_time from details order by id desc limit 1)'
cursor.execute(sql_query, li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新最新数据")
for item in li:
cursor.execute(sql, item)
conn.commit() # 提交事务 update delete insert操作
print(f"{time.asctime()}更新最新数据完毕")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
def update_history():
"""
更新历史数据
:return:
"""
cursor = None
conn = None
try:
dic = get_tencent_data()[0] # 0 是历史数据字典,1 最新详细数据列表
print(f"{time.asctime()}开始更新历史数据")
conn, cursor = get_conn()
sql = "insert into history values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from history where ds=%s"
for k, v in dic.items():
# item 格式 {'2020-01-13': {'confirm': 41, 'suspect': 0, 'heal': 0, 'dead': 1}
if not cursor.execute(sql_query, k): # 如果当天数据不存在,才写入
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("confirm_now"),
v.get("suspect"), v.get(
"suspect_add"), v.get("heal"),
v.get("heal_add"), v.get("dead"), v.get("dead_add")])
conn.commit() # 提交事务 update delete insert操作
print(f"{time.asctime()}历史数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
2.爬取百度热搜数据
2.1数据爬取
这个网页比较简单,直接爬取就可以了。
2.2数据存储
📖创建数据库
这里创建表
use cov;
CREATE TABLE `hotsearch` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`dt` datetime DEFAULT NULL ON UPDATE
CURRENT_TIMESTAMP,
`content` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT
CHARSET=utf8mb4
📖插入和更新数据
def get_baidu_hot():
"""
:return: 返回百度疫情热搜
"""
url = "https://top.baidu.com/board?tab=realtime"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
res = requests.get(url, headers=headers)
# res.encoding = "gb2312"
html = res.text
soup = BeautifulSoup(html, features="html.parser")
kw = soup.select("div.c-single-text-ellipsis")
count = soup.select("div.hot-index_1Bl1a")
context = []
for i in range(len(kw)):
k = kw[i].text.strip() # 移除左右空格
v = count[i].text.strip()
# print(f"{k}{v}".replace('\n',''))
context.append(f"{k}{v}".replace('\n', ''))
return context
def update_hotsearch():
"""
将疫情热搜插入数据库
:return:
"""
cursor = None
conn = None
try:
context = get_baidu_hot()
print(f"{time.asctime()}开始更新热搜数据")
conn, cursor = get_conn()
sql = "insert into hotsearch(dt,content) values(%s,%s)"
ts = time.strftime("%Y-%m-%d %X")
for i in context:
cursor.execute(sql, (ts, i)) # 插入数据
conn.commit() # 提交事务保存数据
print(f"{time.asctime()}数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
3.爬取中高风险地区数据
3.1数据爬取
国家卫建委网站:https://bmfw.www.gov.cn/yqfxdjcx/risk.html
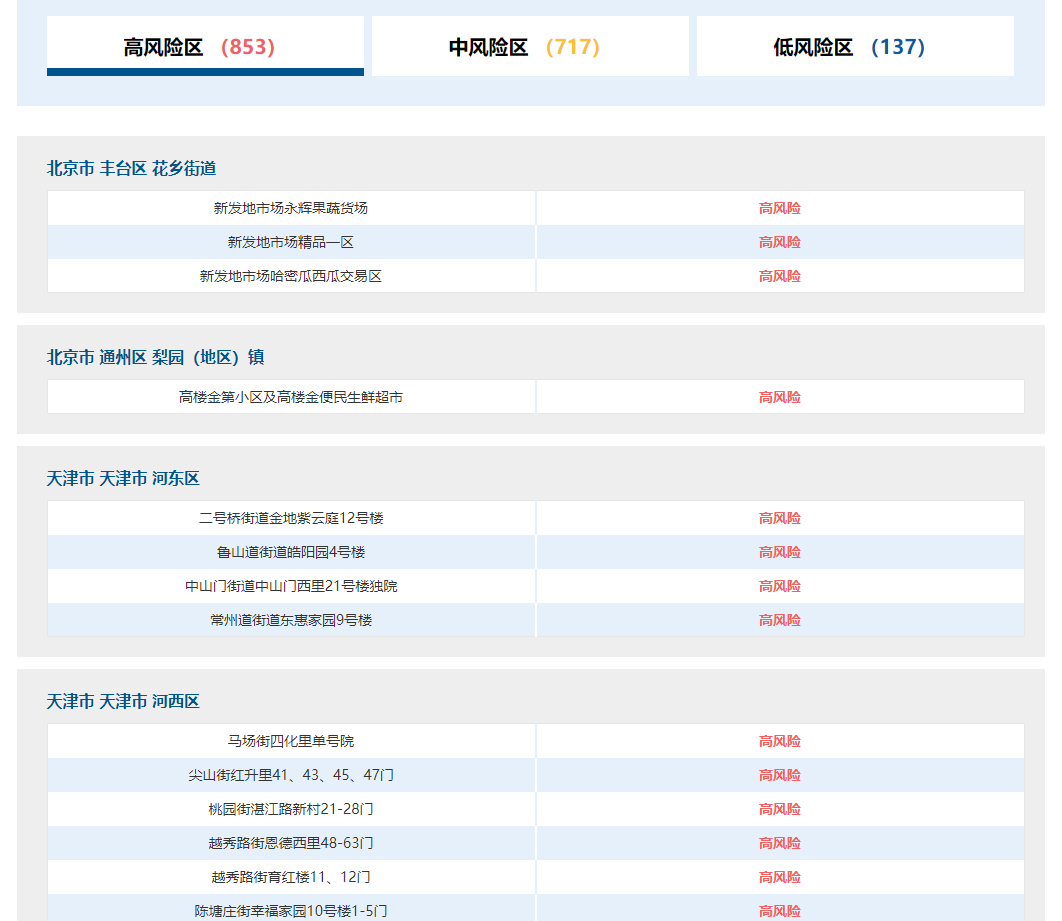
主要难点在于反爬,这就需要我们进行反反爬。代码如下:
import hashlib
import json
import requests
import time
timestamp = str(int((time.time())))
nonce = '123456789abcdefg'
passid = 'zdww'
key = "3C502C97ABDA40D0A60FBEE50FAAD1DA"
zdwwsign = timestamp + 'fTN2pfuisxTavbTuYVSsNJHetwq5bJvC' + \
'QkjjtiLM2dCratiA' + timestamp
hsobj = hashlib.sha256()
hsobj.update(zdwwsign.encode('utf-8'))
zdwwsignature = hsobj.hexdigest().upper()
has256 = hashlib.sha256()
sign_header = timestamp + token + nonce + timestamp
has256.update(sign_header.encode('utf-8'))
signatureHeader = has256.hexdigest().upper()
url = 'https://bmfw.www.gov.cn/bjww/interface/interfaceJson'
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
# "Content-Length": "235",
"Content-Type": "application/json; charset=UTF-8",
"Host": "bmfw.www.gov.cn",
"Origin": "http://bmfw.www.gov.cn",
"Referer": "http://bmfw.www.gov.cn/yqfxdjcx/risk.html",
# "Sec-Fetch-Dest": "empty",
# "Sec-Fetch-Mode": "cors",
# "Sec-Fetch-Site": "cross-site",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
"x-wif-nonce": "QkjjtiLM2dCratiA",
"x-wif-paasid": "smt-application",
"x-wif-signature": zdwwsignature,
"x-wif-timestamp": timestamp
}
params = {
'appId': "NcApplication",
'paasHeader': "zdww",
'timestampHeader': timestamp,
'nonceHeader': "123456789abcdefg",
'signatureHeader': signatureHeader,
'key': "3C502C97ABDA40D0A60FBEE50FAAD1DA"
}
resp = requests.post(url, headers=headers, json=params)
res = json.loads(resp.text)
print(res['data'])
3.2数据存储
📖创建数据库
use cov;
CREATE TABLE `risk_area` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`end_update_time` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '数据最后更新时间',
`province` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '省',
`city` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '市',
`county` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '县',
`address` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '详细地址',
`type` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '风险类型',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
📖插入和更新数据库
def get_tencent_data():
"""
:return: 返回历史数据和当日详细数据
"""
url_det = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=diseaseh5Shelf'
url_his = "https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=chinaDayList,chinaDayAddList,nowConfirmStatis,provinceCompare"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
r_det = requests.get(url_det, headers)
r_his = requests.get(url_his, headers)
res_det = json.loads(r_det.text) # json字符串转字典
res_his = json.loads(r_his.text)
data_det = res_det['data']['diseaseh5Shelf']
data_his = res_his['data']
history = {} # 历史数据
for i in data_his["chinaDayList"]:
ds = i["y"]+"."+i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式,不然插入数据库会报错,数据库是datetime类型
confirm = i["confirm"]
confirm_now = i["nowConfirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {"confirm": confirm, "confirm_now": confirm_now,
"suspect": suspect, "heal": heal, "dead": dead}
for i in data_his["chinaDayAddList"]:
ds = i["y"]+"."+i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup)
confirm_add = i["confirm"]
suspect_add = i["suspect"]
heal_add = i["heal"]
dead_add = i["dead"]
history[ds].update({"confirm_add": confirm_add, "suspect_add": suspect_add,
"heal_add": heal_add, "dead_add": dead_add})
details = [] # 当日详细数据
update_time = data_det["lastUpdateTime"]
data_country = data_det["areaTree"] # list 之前有25个国家,现在只有中国
data_province = data_country[0]["children"] # 中国各省
for pro_infos in data_province:
province = pro_infos["name"] # 省名
for city_infos in pro_infos["children"]:
city = city_infos["name"] # 城市名
confirm = city_infos["total"]["confirm"] # l累计确诊
confirm_add = city_infos["today"]["confirm"] # 新增确诊
confirm_now = city_infos["total"]["nowConfirm"] # 现有确诊
heal = city_infos["total"]["heal"] # 累计治愈
dead = city_infos["total"]["dead"] # 累计死亡
details.append([update_time, province, city, confirm,
confirm_add, confirm_now, heal, dead])
return history, details
def update_risk_area():
"""
更新 risk_area 表
:return:
"""
cursor = None
conn = None
try:
risk_h, risk_m = get_risk_area()
conn, cursor = get_conn()
sql = "insert into risk_area(end_update_time,province,city,county,address,type) values(%s,%s,%s,%s,%s,%s)"
# 对比当前最大时间戳
sql_query = 'select %s=(select end_update_time from risk_area order by id desc limit 1)'
cursor.execute(sql_query, risk_h[0][0]) # 传入最新时间戳
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新最新数据")
for item in risk_h:
cursor.execute(sql, item)
for item in risk_m:
cursor.execute(sql, item)
conn.commit() # 提交事务 update delete insert操作
print(f"{time.asctime()}更新最新数据完毕")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
三、ECharts可视化
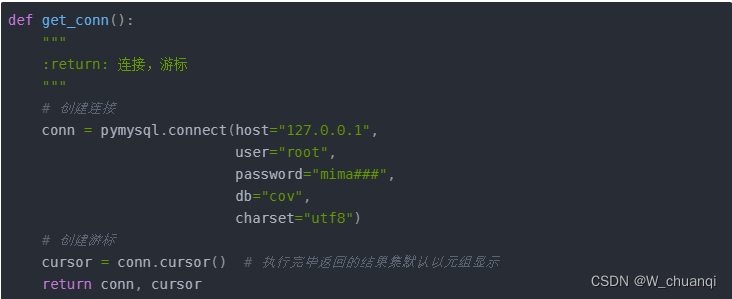
1.从数据库获取所需数据
我们需要从数据库中获取我们需要的数据,为下一步的绘图做准备。
首先连接到数据库:
从 details 表中获取累计确诊、现有确诊、累计治愈、累计死亡人数
def get_c1_data():
"""
:return: 返回大屏div id=c1 的数据
"""
# 因为会更新多次数据,取时间戳最新的那组数据
sql = """
SELECT total,total-heal-dead,heal,dead from (
select sum(confirm) total,
(SELECT heal from history ORDER BY ds desc LIMIT 1) heal ,
sum(dead) dead
from details where update_time=(
select update_time from details order by update_time desc limit 1)
) d;
"""
res = query(sql)
return res[0]
从 details 表中获取各省现有确诊人数
def get_c2_data():
"""
:return: 返回各省数据
"""
# 因为会更新多次数据,取时间戳最新的那组数据
sql = "select province,sum(confirm_now) from details " \
"where update_time=(select update_time from details " \
"order by update_time desc limit 1) " \
"group by province"
res = query(sql)
return res
从 history 表中获取新增确诊、新增疑似人数
def get_l1_data():
sql = "select ds,confirm_add,suspect_add from history"
res = query(sql)
return res
从 risk_area 表中获取全国中高风险地区
def get_l2_data():
# 因为会更新多次数据,取时间戳最新的那组数据
sql = "select end_update_time,province,city,county,address,type" \
" from risk_area " \
"where end_update_time=(select end_update_time " \
"from risk_area " \
"order by end_update_time desc limit 1) "
res = query(sql)
return res
从 details 表中获取现有确诊人数前10名的省份
def get_r1_data():
"""
:return: 返回现有确诊人数前10名的省份
"""
sql = 'SELECT province,confirm FROM ' \
'(select province ,sum(confirm_now) as confirm from details ' \
'where update_time=(select update_time from details ' \
'order by update_time desc limit 1) ' \
'group by province) as a ' \
'ORDER BY confirm DESC LIMIT 10'
res = query(sql)
return res
从 hotsearch 表中获取最近的30条热搜
def get_r2_data():
"""
:return: 返回最近的30条热搜
"""
sql = 'select content from hotsearch order by id desc limit 30'
res = query(sql) # 格式 (('民警抗疫一线奋战16天牺牲 1037364',), ('四川再派两批医疗队 1537382',)
return res
2.传递数据
使用 flask 将后台数据传递到服务器
from flask import Flask, request, render_template, jsonify
from jieba.analyse import extract_tags
import string
import utils
app = Flask(__name__)
@app.route("/l1")
def get_l1_data():
data = utils.get_l1_data()
day, confirm_add, suspect_add = [], [], []
for a, b, c in data:
day.append(a.strftime("%m-%d")) # a是datatime类型
confirm_add.append(b)
suspect_add.append(c)
return jsonify({"day": day, "confirm_add": confirm_add, "suspect_add": suspect_add})
@app.route("/l2")
def get_l2_data():
data = utils.get_l2_data()
# end_update_time, province, city, county, address, type
details = []
risk = []
end_update_time = data[0][0]
for a, b, c, d, e, f in data:
risk.append(f)
details.append(f"{b}\t{c}\t{d}\t{e}")
return jsonify({"update_time": end_update_time, "details": details, "risk": risk})
@app.route("/c1")
def get_c1_data():
data = utils.get_c1_data()
return jsonify({"confirm": int(data[0]), "confirm_now": int(data[1]), "heal": int(data[2]), "dead": int(data[3])})
@app.route("/c2")
def get_c2_data():
res = []
for tup in utils.get_c2_data():
# [{'name': '上海', 'value': 318}, {'name': '云南', 'value': 162}]
res.append({"name": tup[0], "value": int(tup[1])})
return jsonify({"data": res})
@app.route("/r1")
def get_r1_data():
data = utils.get_r1_data()
city = []
confirm = []
for k, v in data:
city.append(k)
confirm.append(int(v))
return jsonify({"city": city, "confirm": confirm})
@app.route("/r2")
def get_r2_data():
data = utils.get_r2_data() # 格式 (('民警抗疫一线奋战16天牺牲1037364',), ('四川再派两批医疗队1537382',)
d = []
for i in data:
k = i[0].rstrip(string.digits) # 移除热搜数字
v = i[0][len(k):] # 获取热搜数字
ks = extract_tags(k) # 使用jieba 提取关键字
for j in ks:
if not j.isdigit():
d.append({"name": j, "value": v})
return jsonify({"kws": d})
@app.route('/')
def hello_world():
return render_template("main.html")
@app.route('/ajaxtest', methods=["post"])
def hello_world4():
name = request.values.get("name")
return f"你好 {name},服务器收到了ajax请求"
@app.route('/xyz')
def hello_world3():
return render_template("a.html")
@app.route('/denglu')
def hello_world2():
name = request.values.get("name")
pwd = request.values.get("pwd")
return f'name={name},pwd={pwd}'
@app.route("/login")
def hello_world1():
id = request.values.get("id")
return f"""
<form action="/denglu">
<p>账号:<input name="name" value={id}></p>
<p>密码:<input name="pwd" ></p>
<p><input type="submit" ></p>
</form>
"""
if __name__ == '__main__':
app.run(host="0.0.0.0", port=9999)
通过 Ajax 向服务器发送请求,接收服务器返回的 json 数据,然后使用 JavaScript 修改网页的来实现页面局部数据更新
function showTime() {
var date = new Date()
var year = date.getFullYear()
var month = date.getMonth()+1
var day = date.getDate()
var hour = date.getHours()
var minute = date.getMinutes()
var second = date.getSeconds()
if(hour < 10){ hour = "0"+hour}
if(minute < 10){ minute = "0"+minute}
if(second < 10){ second = "0"+second}
var time = year + "年"+ month + "月"+day + "日"+hour + ":"+minute + ":"+second
$("#tim").html(time)
}
setInterval(showTime,1000) //1秒调用1次
function get_c1_data(){
$.ajax({
url:"/c1",
success:function (data) {
$(".num h1").eq(0).text(data.confirm)
$(".num h1").eq(1).text(data.confirm_now)
$(".num h1").eq(2).text(data.heal)
$(".num h1").eq(3).text(data.dead)
}
})
}
function get_c2_data() {
$.ajax({
url:"/c2",
success: function(data) {
ec_center_option.series[0].data=data.data
ec_center_option.series[0].data.push({
name:"南海诸岛",value:0,
itemStyle:{
normal:{ opacity:0},
},
label:{show:false}
})
ec_center.setOption(ec_center_option)
},
error: function(xhr, type, errorThrown) {
}
})
}
function get_l1_data() {
ec_left1.showLoading()
$.ajax({
url:"/l1",
success: function(data) {
ec_left1_Option.xAxis[0].data=data.day
ec_left1_Option.series[0].data=data.confirm_add
ec_left1_Option.series[1].data=data.suspect_add
ec_left1.setOption(ec_left1_Option)
ec_left1.hideLoading()
},
error: function(xhr, type, errorThrown) {
}
})
}
function get_l2_data() {
$.ajax({
url:"/l2",
success: function(data) {
var update_time = data.update_time
var details = data.details
var risk = data.risk
$("#l2 .ts").html("截至时间:" + update_time)
var s =""
for(var i in details){
if (risk[i] == "高风险"){
s += "<li><span class='high_risk'>高风险\t\t</span>"+ details[i] + "</li>"
}else{
s += "<li><span class='middle_risk'>中风险\t\t</span>"+ details[i] + "</li>"
}
}
$("#risk_wrapper_li1 ul").html(s)
start_roll()
},
error: function(xhr, type, errorThrown) {
}
})
}
function get_r1_data() {
$.ajax({
url: "/r1",
success: function (data) {
ec_right1_option.xAxis.data=data.city;
ec_right1_option.series[0].data=data.confirm;
ec_right1.setOption(ec_right1_option);
}
})
}
function get_r2_data() {
$.ajax({
url: "/r2",
success: function (data) {
ec_right2_option.series[0].data=data.kws;
ec_right2.setOption(ec_right2_option);
}
})
}
function refreshPage(){
window.location.reload()
}
get_c1_data()
get_c2_data()
get_l1_data()
get_l2_data()
get_r1_data()
get_r2_data()
3.ECharts绘图
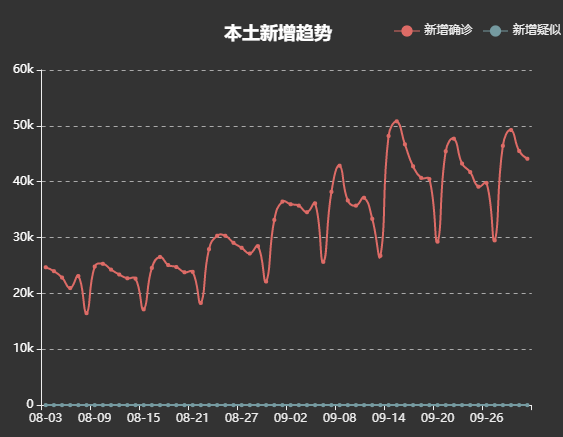
实现本土新增趋势折线图
var ec_left1 = echarts.init(document.getElementById('l1'), "dark");
var ec_left1_Option = {
tooltip: {
trigger: 'axis',
//指示器
axisPointer: {
type: 'line',
lineStyle: {
color: '#7171C6'
}
},
},
legend: {
data: ['新增确诊', '新增疑似'],
left: "right"
},
//标题样式
title: {
text: "本土新增趋势",
textStyle: {
color: 'white',
},
left: 'center'
},
//图形位置
grid: {
left: '4%',
right: '6%',
bottom: '4%',
top: 50,
containLabel: true
},
xAxis: [{
type: 'category',
//x轴坐标点开始与结束点位置都不在最边缘
// boundaryGap : true,
data: []
}],
yAxis: [{
type: 'value',
//y轴字体设置
//y轴线设置显示
axisLine: {
show: true
},
axisLabel: {
show: true,
color: 'white',
fontSize: 12,
formatter: function (value) {
if (value >= 1000) {
value = value / 1000 + 'k';
}
return value;
}
},
//与x轴平行的线样式
splitLine: {
show: true,
lineStyle: {
// color: '#FFF',
width: 1,
// type: 'solid',
}
}
}],
series: [{
name: "新增确诊",
type: 'line',
smooth: true,
data: []
}, {
name: "新增疑似",
type: 'line',
smooth: true,
data: []
}]
};
ec_left1.setOption(ec_left1_Option)
效果如下:
实现中高风险地区信息滚动
function start_roll() {
var speed = 30; // 可自行设置文字滚动的速度
var wrapper = document.getElementById('risk_wrapper');
var li1 = document.getElementById('risk_wrapper_li1');
var li2 = document.getElementById('risk_wrapper_li2');
li2.innerHTML = li1.innerHTML //克隆内容
function Marquee() {
if (li2.offsetHeight - wrapper.scrollTop <= 0) //当滚动至demo1与demo2交界时
wrapper.scrollTop -= li1.offsetHeight //demo跳到最顶端
else {
wrapper.scrollTop++ //如果是横向的 将 所有的 height top 改成 width left
}
}
var MyMar = setInterval(Marquee, speed) //设置定时器
wrapper.onmouseover = function () {
clearInterval(MyMar) //鼠标移上时清除定时器达到滚动停止的目的
}
wrapper.onmouseout = function () {
MyMar = setInterval(Marquee, speed) //鼠标移开时重设定时器
}
}
效果如下:

实现数字显示和地图
var ec_center = echarts.init(document.getElementById('c2'), "dark");
var ec_center_option = {
title: {
text: '全国现有确诊',
subtext: '',
x: 'left'
},
tooltip: {
trigger: 'item'
},
//左侧小导航图标
visualMap: {
show: true,
x: 'left',
y: 'bottom',
textStyle: {
fontSize: 8,
},
splitList: [{ start: 1, end: 9 },
{ start: 10, end: 99 },
{ start: 100, end: 999 },
{ start: 1000, end: 9999 },
{ start: 10000 }],
color: ['#8A3310', '#C64918', '#E55B25', '#F2AD92', '#F9DCD1']
},
//配置属性
series: [{
name: '现有确诊人数',
type: 'map',
mapType: 'china',
roam: false, //拖动和缩放
itemStyle: {
normal: {
borderWidth: .5, //区域边框宽度
borderColor: '#62d3ff', //区域边框颜色
areaColor: "#b7ffe6", //区域颜色
},
emphasis: { //鼠标滑过地图高亮的相关设置
borderWidth: .5,
borderColor: '#fff',
areaColor: "#fff",
}
},
label: {
normal: {
show: true, //省份名称
fontSize: 8,
},
emphasis: {
show: true,
fontSize: 8,
}
},
data: [] //mydata //数据
}]
};
ec_center.setOption(ec_center_option)
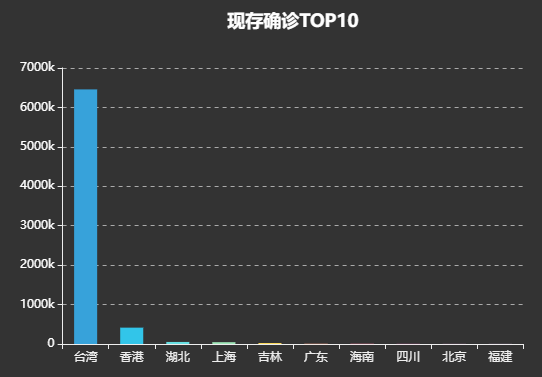
实现现存确诊TOP10柱形图
var ec_right1 = echarts.init(document.getElementById('r1'), "dark");
var ec_right1_option = {
//标题样式
title: {
text: "现存确诊TOP10",
textStyle: {
color: 'white',
},
left: 'center'
},
color: ['#3398DB'],
tooltip: {
trigger: 'axis',
axisPointer: { // 坐标轴指示器,坐标轴触发有效
type: 'shadow' // 默认为直线,可选为:'line' | 'shadow'
}
},
xAxis: {
type: 'category',
color: 'white',
data: []
},
yAxis: {
type: 'value',
color: 'white',
axisLabel: {
show: true,
color: 'white',
fontSize: 12,
formatter: function (value) {
if (value >= 1000) {
value = value / 1000 + 'k';
}
return value;
}
},
},
series: [{
data: [],
type: 'bar',
barMaxWidth: "50%",
itemStyle: {
normal: {
color: function (params) {
// 给出颜色组
var colorList = ['#37A2DA',
'#32C5E9',
'#67E0E3',
'#9FE6B8',
'#FFDB5C',
'#ff9f7f',
'#fb7293',
'#E062AE',
'#E690D1',
'#e7bcf3'
];
//循环调用
return colorList[params.dataIndex]
},
}
},
}]
};
ec_right1.setOption(ec_right1_option)
效果如下:
实现百度热搜词云图
var ec_right2 = echarts.init(document.getElementById('r2'), "dark");
// var ddd = [{'name': '肺炎', 'value': '12734670'}, {'name': '实时', 'value': '12734670'},
// {'name': '新型', 'value': '12734670'}]
var ec_right2_option = {
// backgroundColor: '#515151',
title: {
text: "百度热搜",
textStyle: {
color: 'white',
},
left: 'center'
},
tooltip: {
show: false
},
series: [{
type: 'wordCloud',
// drawOutOfBound:true,
gridSize: 1,
sizeRange: [12, 55],
rotationRange: [-45, 0, 45, 90],
// maskImage: maskImage,
textStyle: {
normal: {
color: function () {
return 'rgb(' +
Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) + ')'
}
}
},
// left: 'center',
// top: 'center',
// // width: '96%',
// // height: '100%',
right: null,
bottom: null,
// width: 300,
// height: 200,
// top: 20,
data: []
}]
}
ec_right2.setOption(ec_right2_option);
文章参考:
https://www.bilibili.com/video/BV177411j7qJ/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=56b2399413f9f507dd46a3f819cce95a
https://blog.csdn.net/kylner/article/details/125309260