Java集合
一:集合框架
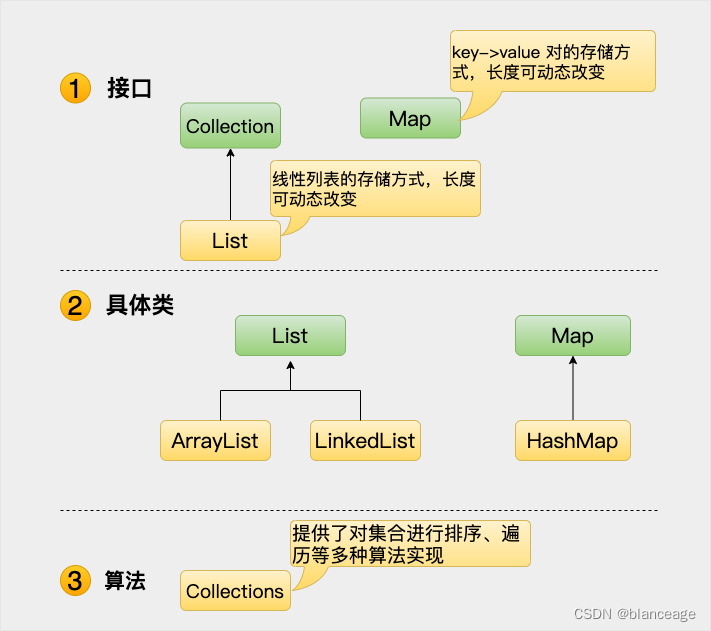
1.1 集合框架图

从上面的集合框架图我们可以看出 ,java集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection接口又有3种子类型,分别是List,Set和Queue;再往下呢就是一些抽象类了,最后是具体实现类。我们比较常用的实现类有ArrayList、LinkedList、HashSet、LinkedHasSet、HasMap、LinkedHasMap等等。
所有的集合框架都包含如下内容:
1.接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。
2.实现类: 是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
3.算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
1.2 集合框架体系图
Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包。
二:集合接口
2.1 Collection集合接口
Collection接口是集合最基本的接口,一个Collection接口代表一组Object,即Collection的元素,Java不会直接提供直接继承自Collection接口的实现类,而是只提供继承自Collection接口的子接口,例如List和Set。
Collection接口储存的元素是不唯一并且是无序的。
Colloction集合接口的方法:
| 1 | boolean add(E e) | 在集合末尾添加元素 |
| 2 | boolean remove(Object o) | 删除与o的值相等的元素,并返回true。 |
| 3 | void clear() | 清除集合中所有的元素,然后集合为空。 |
| 4 | boolean contains(Objiect o) | 判断集合中是否包含该元素 |
| 5 | boolean isEmpty | 判断集合是否为空 |
| 6 | int size() | 返回集合中的元素个数 |
| 7 | boolean addAll(Collection c) | 将一个集合中的所有元素添加到另一个集合 |
| 8 | Object【】 toArray() | 返回一个包含了本集合中所有元素的数组,数组类型为Object类 |
| 9 | Iterator iterator() | 迭代器,遍历集合用的 |
2.2 List集合接口
List接口是一个有序的集合接口,使用List接口能精确的控制每个元素存储的位置,而且还能通过索引值来访问List中的元素,第一个元素的索引值为0,并且List可以允许有相同的元素。
List接口存储的元素不唯一,并且是有序的。
List集合接口的方法:
| 1 | void add(int index,Object obj) | 在指定位置添加元素 |
| 2 | Object remove(int index) | 根据索引值删除元素,并把删除的元素返回 |
| 3 | Object set(int index,Object obj) | 把指定索引值位置上的元素修改为指定的值,返回修改前的值。 |
| 4 |
int indexOf(Object obj) |
返回指定元素在集合中第一次出现的索引值 |
| 5 | Object get(int index) | 获取指定位置上的元素 |
| 6 | List subList(int fromIndex,int toIndex) | 截取集合 |
| 7 | ListIterator listIterator() | 列表迭代器 |
2.3 Set集合接口
Set接口具有与Collection完全一样的接口,只是行为上有所区别,Set不会保存重复的元素。
Set接口储存的元素唯一,并且无序。
2.4 Map集合接口
Map 接口存储一组键值对象,提供key(键)到value(值)的映射。它们都可以使用任何引用类型的数据,但key值是不能够重复的。另外要注意,Map并没有继承Collection接口。而是由一堆Map自身接口方法和一个Entry接口组成,Entry接口定义了主要是关于Key-Value自身的一些操作,Map接口定义的是一些属性和关于属性查找修改的一些接口方法。
Map集合接口的方法:
| 1 | void clear() | 清除集合中所有的元素,然后集合为空。 |
| 2 | boolean containsKey(Object key) | 查询Map中是否包含指定key,如果包含则返回true |
| 3 | boolean containsValue(Object value) | 查询Map中是否包含指定value,如果包含则返回true |
| 4 | Set entrySet() | 返回Map中所包含的键值所对应的Set集合,每个元素都是Map.Entry对象 |
| 5 | Object get(Object key) | 返回指定key多对应的value,如果Map中不包含key则返回null |
| 6 | boolean isEmpty() | 查询Map是否为空,如果为空则返回true |
| 7 | Set KeySet() | 返回该Map中所有key值所组成的set集合 |
| 8 | Object put(Object key,Object value) | 添加一个键值对,如果已有一个相同的key值则新的键值对覆盖旧的键值对 |
| 9 | void putAll(Map m) | 将指定Map中的键值对复制到新的Map中去 |
| 10 | Object remove(Object key) | 删除指定key所对应的键值对,返回关联的value,如果key不存在,返回null |
| 11 | int size() | 返回该Map中键值对的个数 |
| 12 | Collection values() | 返回该Map里所有value组成的Collection |
内部类Entry的方法:
| 1 | Object getKey() | 返回该Entry里包含的key值 |
| 2 | Object getValue() | 返回该Entry里包含的value值 |
| 3 | Object setValue() | 设置该Entry里包含的value值,并返回新设置的value值 |
2.5 Set和List的区别
1.Set接口存储的是无序的,不重复的数据。List接口存储的是有序的,可以重复的元素。
2.Set检索效率低下,删除和插入效率高,删除和插入不会影响元素位置的改变。
3.List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率很高,但是插入和删除效率很低,因为会引起其他元素位置的改变。
三:集合实现类
Java提供了一套实现了Collection接口的标准集合类。其中一些是具体类,这些类可以直接拿来使用,而另外一些是抽象类,提供了接口的部分实现。诸如AbstractCollection 、AbstractList 、AbstractSet 等等,在这里我们重点说一下List接口,Set接口和Map接口的几种常用的实现类。
3.1 ArrayList
ArrayList是List接口最常用的一个实现类,支持List接口的一些列操作。
ArrayList的特点是实现了可变大小的数组,随机访问和遍历元素时,能提供更好的性能。但是在多线程的时候会有数据损失。可以进行扩容,扩容量为50%。插入删除效率低。
3.1.1 ArrayList的底层组成
说到ArrayList的组成,我们可以先看看关于它的源码。
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
我们去掉注释重点看这几行代码。
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;// non-private to simplify nested class access
private int size;可以看到里面有一个transient Object[] elementDate,这个elementDate才是存放元素的容器,可见ArrayList是基于数组实现的。
3.1.2 ArrayList的构造方法
我们知道ArrayList可以大小构造,还可以空构造,那我们再来看一下它的构造方法。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}从这里可以简单看出ArraysList的构造原理。
3.1.3 ArrayList中添加元素
我们都知道ArrayList中可以添加元素,使用add()方法就可以,那么它添加元素的方法和原理是什么样的呢,我们再来看看add方法的源码。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}可以看到第二行代码后面的注释中有一个modCount,代表了修改的次数。而add方法的添加元素是将新元素添加到list的尾部。
3.1.4 ArrayList的扩容
我们知道如果我们对ArrayList当中添加元素的时候,当其中存放的元素数量超过了数组可以存放的最大值的时候就会进行扩容,那么到底是怎么扩容的呢,是什么原理呢,我们再来看看它的源码。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}先看这个,说的是如果ArrayList为空的话,那么就会默认直接扩容到DEFAULT_CAPACITY。
private static final int DEFAULT_CAPACITY = 10;而上面 定义了这个值默认为10。但如果超过了这个范围,ArrayList就会进行扩容。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}看第四行代码,这就是ArrayList的扩容规则,采用的是右移运算,就是扩容的量是原来的一半,也就是说变成原来的1.5倍。比如10的二进制是1010,右移后变成了0101就是5。
3.2 LinkedList
LinkedList也是List接口的实现类,它里面可以有空元素(null)。主要用于创建链表结构。我们来看一下它的底层原理。
3.2.1 LinkedList的结构
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;这是LinkedList的结构。由一个头部节点和尾部节点组成,分别指向链表的头部和尾部。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}这是LinkedList中Node的源码,它定义了一个item,并由它指向上一个节点prev和下一个节点next。其中含有一个构造方法,有prev,item,next三个参数。
3.2.2 LinkedList查询方法
我们在这块来看一看LinkedList中的get方法。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}LinkedLinst的查询方法就是定义一个index,然后获取第index个节点。但是node(index)是怎么实现这个方法的呢,我们点进去看一下源码。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}上面注释有写,简单来说就是先判断index是更靠近头部还是尾部,靠近哪边就从哪边开始遍历。
3.3 HashSet
HashSet是Set接口的实现类,在HashSet中是不允许存在重复的元素的。
3.3.1 HashSet的结构
我们知道HashSet的底层结构是HashMap,我们来看看它的源码结构。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
}去掉注释我们可以很清楚的看到HashSet的内部结构其实全是HashMap 。
3.4 HashMap
HashMap是Map接口的实现类,根据key的HashCode值去存储数据,具有很快的访问速度。对于HashMap中存储的键值对我们将其称为Entry,HashMap对Entry进行了扩展(称作Node)。接下来我们来看看HashMap的组成结构吧。
3.4.1 HashMap的结构
//是hashMap的最小容量16,容量就是数组的大小也就是变量,transient Node<K,V>[] table。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大数量,该数组最大值为2^31一次方。
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子,如果构造的时候不传则为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//一个位置里存放的节点转化成树的阈值,也就是8,比如数组里有一个node,这个
// node链表的长度达到该值才会转化为红黑树。
static final int TREEIFY_THRESHOLD = 8;
//当一个反树化的阈值,当这个node长度减少到该值就会从树转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
//满足节点变成树的另一个条件,就是存放node的数组长度要达到64
static final int MIN_TREEIFY_CAPACITY = 64;
//具体存放数据的数组
transient Node<K,V>[] table;
//entrySet,一个存放k-v缓冲区
transient Set<Map.Entry<K,V>> entrySet;
//size是指hashMap中存放了多少个键值对
transient int size;
//对map的修改次数
transient int modCount;
//加载因子
final float loadFactor;可以看到里面第一行注释上面写着transient Node<K,V>[] table,这个table就是存放数据的数组。