ShardingSphere 5.0.0 实现按月水平分表
背景:
业务数据从大数据进行同步,数据量大概1个月1000W条,如果选择按字段进行hash取模分表时间久了数据量依然会很大,所以直接选择按月进行水平分表。
废话不多说,直接上代码
1.Maven引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.0.0</version>
</dependency>2.application.yml配置
spring:
shardingsphere:
props:
# 是否显示sql
sql-show: false
datasource:
ds0:
url: jdbc:mysql://127.0.0.1:3306/db_test?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
names: ds0
rules:
sharding:
key-generators:
snowflake:
type: SNOWFLAKE
sharding-algorithms:
ota-strategy-inline:
props:
strategy: standard
# 自定义标准分配算法
algorithmClassName: com.test.business.algorithm.OTAStrategyShardingAlgorithm
type: CLASS_BASED
tables:
#逻辑表 下面是节点表,分表后还有数据在原来的表,所有查询节点需要加上原来的表
ota_strategy_info:
actual-data-nodes: ds0.ota_strategy_info_202$->{201..212}
key-generate-strategy:
column: id
key-generator-name: snowflake
# 配置分表策略
table-strategy:
#分片策略 以创建时候分表,实现类计算
standard:
sharding-column: create_time
#对应下面的分表策略类
sharding-algorithm-name: ota-strategy-inline
# OTA升级策略表水平分表 ================================================================3.数据分配算法类 OTAStrategyShardingAlgorithm.java
import com.alibaba.fastjson.JSON;
import com.google.common.collect.Range;
import org.apache.commons.lang.StringUtils;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
/**
* @Description: sharding分表规则:按单月分表
* @Author: lg
* @Date: 2022/6/9
* @Version: V1.0
*/
@Component
public class OTAStrategyShardingAlgorithm implements StandardShardingAlgorithm<String> {
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
private static final DateTimeFormatter yyyyMM = DateTimeFormatter.ofPattern("yyyyMM");
/**
* 【范围】数据查询
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
// 逻辑表名
String logicTableName = rangeShardingValue.getLogicTableName();
// 范围参数
Range<String> valueRange = rangeShardingValue.getValueRange();
Set<String> queryRangeTables = extracted(logicTableName, LocalDateTime.parse(valueRange.lowerEndpoint(), formatter),
LocalDateTime.parse(valueRange.upperEndpoint(), formatter));
ArrayList<String> tables = new ArrayList<>(collection);
tables.retainAll(queryRangeTables);
System.out.println(JSON.toJSONString(tables));
return tables;
}
/**
* 根据范围计算表明
*
* @param logicTableName 逻辑表明
* @param lowerEndpoint 范围起点
* @param upperEndpoint 范围终端
* @return 物理表名集合
*/
private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) {
Set<String> rangeTable = new HashSet<>();
while (lowerEndpoint.isBefore(upperEndpoint)) {
String str = getTableNameByDate(lowerEndpoint, logicTableName);
rangeTable.add(str);
lowerEndpoint = lowerEndpoint.plusMonths(1);
}
// 获取物理表明
String tableName = getTableNameByDate(upperEndpoint, logicTableName);
rangeTable.add(tableName);
return rangeTable;
}
/**
* 根据日期获取表明
* @param dateTime 日期
* @param logicTableName 逻辑表名
* @return 物理表名
*/
private String getTableNameByDate(LocalDateTime dateTime, String logicTableName) {
String tableSuffix = dateTime.format(yyyyMM);
return logicTableName.concat("_").concat(tableSuffix);
}
/**
* 数据插入
*
* @param collection
* @param preciseShardingValue
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {
String str = preciseShardingValue.getValue();
if (StringUtils.isEmpty(str)) {
return collection.stream().findFirst().get();
}
LocalDateTime value = LocalDateTime.parse(str, formatter);
String tableSuffix = value.format(yyyyMM);
String logicTableName = preciseShardingValue.getLogicTableName();
String table = logicTableName.concat("_").concat(tableSuffix);
System.out.println("OrderStrategy.doSharding table name: " + table);
return collection.stream().filter(s -> s.equals(table)).findFirst().orElseThrow(() -> new RuntimeException("逻辑分表不存在"));
}
@Override
public void init() {
}
@Override
public String getType() {
// 自定义 这里需要spi支持
return null;
}
}
shardingsphere5.0版本开始,数据插入和数据查询都可以在一个类中实现,需要实现接口:StandardShardingAlgorithm
4.重写方法doSharding()、extracted()
// 根据精准值查询逻辑表
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
}
// 根据范围查询逻辑表
private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) {
}
// 插入数据时根据分表关键词获取物理表
public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {5.初始化分表
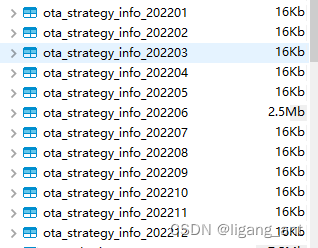
6.插入测试
这里直接使用mybatis或者mybatisplus插入即可,在步骤4中的doSharding方法查看是否匹配到对应的物理表即可,结果直接从表里查看即可。
7.查询测试
执行下述sql
select * from ota_strategy_info where create_time = '2022-04-14 17:21:48'结果:

这里的查询精确找到了4月的物理表,如果未找到则会查询所有表,同理会执行与表数量相对于的sql数量,所以查询的时候一定要命中物理表,否则效率不仅不会提高返回会降低!
总结:
官网文档:概览 :: ShardingSphere https://shardingsphere.apache.org/document/current/cn/overview/更多内容可以参考文档,查询sql是否会命中物理表得多测试,根据日志提示选择查询方法!
https://shardingsphere.apache.org/document/current/cn/overview/更多内容可以参考文档,查询sql是否会命中物理表得多测试,根据日志提示选择查询方法!
版权声明:本文为ligang_ant原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。