HashMap底层实现原理
1 HashMap底层实现原理
1.1 底层使用的数据结构
- JDK8之前:数组、链表
- JDK8之后:数组、链表、红黑树
1.2 重要字段
transient int size; //当前存储的键值对总数
int threshold; //阈值,默认为16
final float loadFactor; //负载因子
transient int modCount; //HashMap被改变的次数,比如使用迭代器进行迭代时,如果其他线程对当HashMap
//进行了修改,则会改变该字段值,即结构已经发生变化,那么迭代器就会抛出并发
//修改异常
1.2 扩容操作(JDK8HashMap)
- 数组:初始容量为16(2^4),初始负载因子为0.75,即当存储元素个数超过threshold(当前容量)*0.75(负载因子)时会进行扩容,每次扩容后容量为之前得2倍。
- 链表:使用哈希函数计算存储位置后,如果数组中该位置已经被使用,那么就会在该位置处添加链表,链表的最大容量为8,如果超过8,就会转换为红黑树来存储。
- 红黑树:使用红黑树的查询效率高于普通链表,因为使用红黑树相当于二分查找,二分查找的效率要高于顺序查找,并且红黑树会自动保持平衡,从而进一步保证查询效率。当红黑树结点减少到6(不是8)时,会转换回链表。
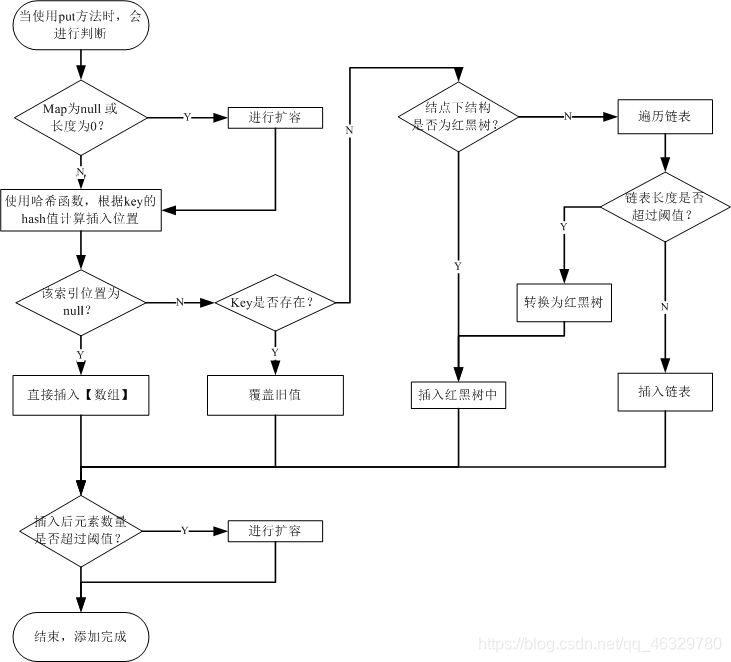
注意:当添加元素时会进行扩容,同理,减少元素时也会进行减少容量的操作。所以,Map集合会在增加、减少等修改Map集合时对整体结构进行维护(修改内部结构和容量)。
- 为什么默认值都为2^n?
- 为了减少碰撞,源码中计算索引位置为了效率考虑使用的是按位与操作(&),并不是直接取余,所以2的幂的效率相比于其他更高。
- 扩容时为二倍,因为当扩容完成后会将键值对全部移入新的Map中(所以扩容是耗时操作),而直接扩容为原来的二倍能更有效的是之前的元素均匀的分部在新的Map中。
使用程序来模拟实现
/**
结论(进行1000次测试):
使用方差来获取阈值扩容时的离散程度(方差越大说明存储的越分散)
初始容量不同,扩容倍数相同:
容量为8:770.625==> 容量为16:408.21875
容量为7:755.8775510204122==> 容量为14:397.7551020408195
初始容量相同,扩容倍数不同:
容量为8:751.125==> 容量为16:406.21875
容量为8:751.125==> 容量为24:276.5972222222216
说明容量和扩容都为2的倍数时方差大,更不容易产生哈希冲突
*/
//测试代码
public class Demo01 {
public static void main(String[] args) {
double[] testNumber = new double[4];
for (int i = 0; i < 1000; i++) {
double[] test = test();
for (int i1 = 0; i1 < test.length; i1++) {
testNumber[i1] += test[i1];
}
}
System.out.println("容量为8:" + testNumber[0] + "==> 容量为16:" + testNumber[1]);
System.out.println("容量为8:" + testNumber[2] + "==> 容量为24:" + testNumber[3]);
}
private static double[] test() {
//当前准备存入Map的值,1000以内不重复的7个数(6为阈值)
int[] numbers1 = getRamNums(7);
//存入大小为8的数组中,即使用 number % 8 获取索引值,最后查看各个位置哈希冲突的情况
int[] getHash_8 = new int[8];
for (int number : numbers1) {
getHash_8[number % 8]++;
}
//存入大小为16的数组中,即使用 number % 16 获取索引值,最后查看各个位置哈希冲突的情况
int[] getHash_16 = new int[16];
for (int number : numbers1) {
getHash_16[number % 16]++;
}
//当前准备存入Map的值,1000以内不重复的6个数(5为阈值)
int[] numbers2 = getRamNums(6);
//存入大小为7的数组中,即使用 number % 7 获取索引值,最后查看各个位置哈希冲突的情况
int[] getHash_7 = new int[7];
for (int number : numbers2) {
getHash_7[number % 7]++;
}
//存入大小为14的数组中,即使用 number % 16 获取索引值,最后查看各个位置哈希冲突的情况
int[] getHash_14 = new int[14];
for (int number : numbers2) {
getHash_14[number % 14]++;
}
return new double[]{comvariance(getHash_8),comvariance(getHash_16),comvariance(getHash_7),comvariance(getHash_14)};
}
private static int[] getRamNums(int n) {
//获取1000以内不重复的100个数
Random random = new Random();
int[] numbers = new int[n];
for (int i = 0; i < numbers.length; i++) {
int number = random.nextInt(1000) + 1;
if (show1(number,numbers)){
numbers[i] = number;
}else {
i--;
}
}
return numbers;
}
private static boolean show1(int number,int[] numbers) {
//判断number是否在数组中出现
for (int number1 : numbers) {
if (number1 == number) return false;
}
return true;
}
private static double comvariance(int[] numbers){
//计算方差
double sum = 0; //求和
for (int number : numbers) {
sum += number;
}
double ave = sum / numbers.length;//平均数
sum = 0; //存储均差和
for (int number : numbers) {
sum += (number - ave) * (number - ave);
}
ave = sum / numbers.length;
return ave;
}
}
1.3 其他的几个问题
-
为什么JDK8添加了红黑树提高性能?
红黑树查找事件复杂度为O(logn),链表为O(n);
-
为什么会有链表会达到阈值将结构修改为红黑树,而不是直接为红黑树?
红黑树结点基本上为链表结点大小的两倍,所以在存储元素较少时,不宜使用较多的存储空间。
-
为什么会在红黑树结点数量为6的时候转换回链表,而不是和链表转换为红黑树时一样为8?
避免在阈值附近增加删除元素而引起频繁的链表和红黑树的转换。
-
JDK8之前存在的多线程情况下的死循环问题?
JDK 1.7 扩容采用的是“头插法”,会导致同一索引位置的节点在扩容后顺序反掉。而 JDK 1.8 之后采用的是“尾插法”,扩容后节点顺序不会反掉,不存在死循环问题。
-
JDK8对Map的优化。
- 底层数据结构从“数组+链表”改成“数组+链表+红黑树”;
- 计算 table (底层数组)初始容量的方式发生了改变;
- 优化了 hash 值的计算方式,新的计算方式是让高16位参与了运算;
- 扩容时插入方式从“头插法”改成“尾插法”,避免了并发下的死循环;
- 扩容时计算节点在新表的索引位置方式从“h & (length-1)”改成“hash & oldCap”。
1.4 Map集合的选择问题
| 类 | 介绍 | 使用 |
|---|---|---|
| HashTable | 早期线程安全的Map,使用synchronized修饰方法实现的。 | 基本不会使用 |
| CocurrentHashMap | 线程安全的Map,使用synchronized+CAS实现的。 | 需要保证线程安全时使用 |
| LinkedHashMap | 能记录访问顺序或插入顺序 | 需要记录顺序时使用 |
| TreeMap | 可是自定义排序规则进行存储 | 需要自定义排序规则时使用 |
| HashMap | 非线程安全、无序 | 没有特殊要求,一般使用 |
版权声明:本文为qq_46329780原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
THE END