MySqL速成教程笔记系列六
分组查询
在实际的应用中,可能有这样的需求,需要先进行分组,然后对每一组的数据进行操作。
这个时候我们需要使用分组查询。
select …… from…… group by……
之前的关键字全部组合在一起,关键字顺序:
select…… from……where……group by……
order by……
执行顺序:
1.from 2.where 3.group by 4.select 5.order by
问题:
1.为什么分组函数不能直接使用在where后面?
select ename,sal from emp where sal > min(sal); //会报错
因为分组函数在使用的时候必须先分组之后才能使用。
where执行的时候,还没有分组。所以where后面不能出现分组函数。
2.select sum(sal) from emp;
这个没有分组,为啥sum()函数可以用?
因为select在group by之后执行
看几个例子:
(1)计算每个部门的工资和?
实现思路:按照工作岗位进行分组,然后对工资求和。
select job,sum(sal) from emp group by job;
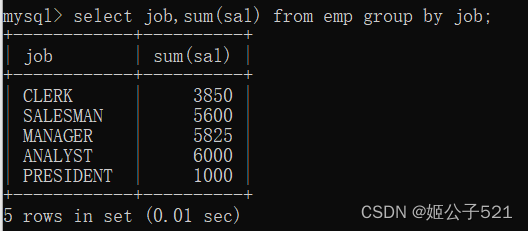
这句话的执行顺序:先从emp表中查询数据,根据job字段进行分组,然后对每一组的数据进行sum(sal)
注意:
select ename,job,sum(sal) from emp group by job;
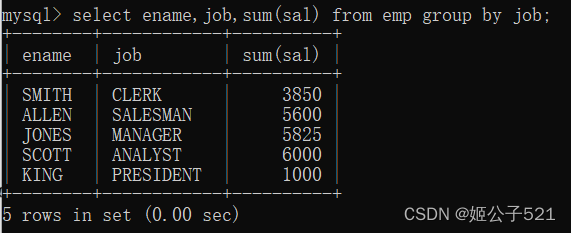
可以发现ename和job根本没有任何关系,只是取了前几个名字显示出来而已。
以上语句在mysql中可以执行,但是毫无意义。
以上语句在oracle中执行报错。
Oracle的语法比mysql的语法更加严格。
重点结论:
在一条select语句当中,如果有group by语句的话,select后面只能跟:参加分组的字段,以及分组函数。其他的一律不能跟。
(2)找出每个部门的最高薪资
select deptno,max(sal) from emp group by deptno;
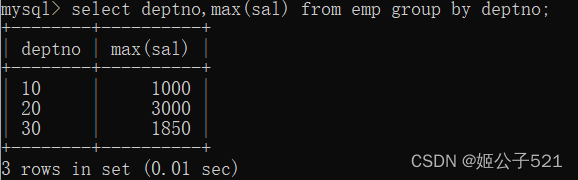
(3)找出每个部门,不同工作岗位的最高薪资?
select deptno,job,max(sal) from emp group by deptno,job;
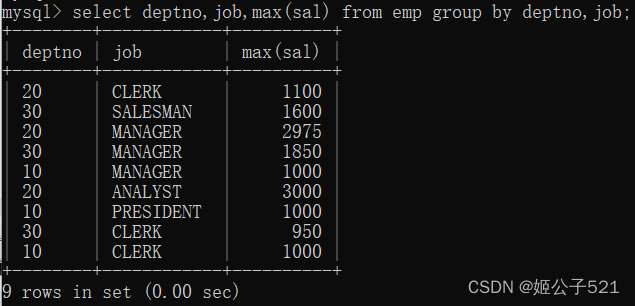
(4)找出每个部门最高薪资,要求显示最高薪资大于3000的?
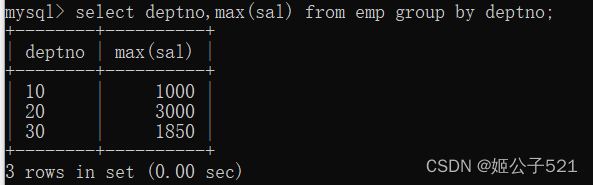
第一步:找出每个部门的最高工资
select deptno,max(sal) from emp group by deptno;
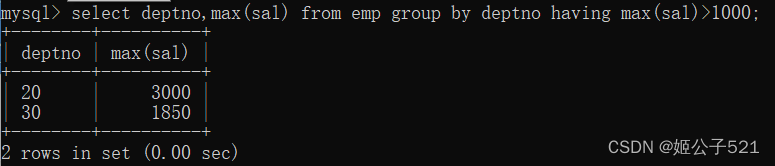
第二步:要求显示最高薪资大于1000
select deptno,max(sal) from emp group by deptno having max(sal)>1000;
思考:以上的sql语句执行效率是不是低?
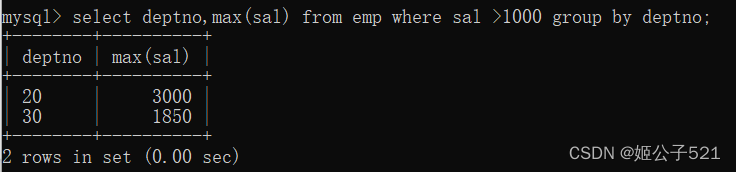
比较低。实际上可以这样考虑:先将大于1000的都找出来,然后再分组。
select deptno,max(sal) from emp where sal >1000 group by deptno;
优化策略:where和having,优先选择where,where实在完成不了,再选择having。
(5)找出每个部门平均薪资,要求平均薪资大于2000.
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2000;

(6)大总结
关键字顺序:
select……from……where……group by……having……order by……
执行顺序:
1.from 2.where 3.group by 4.having 5.select 6.order by
从某张表中查询数据,先经过where条件筛选出有价值的数据。对这些有价值的数据进行分组。分组之后可以使用having继续筛选,select查询出来,最后排序输出。
(7)找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除MANAGER岗位之外,要求按照平均薪资降序排。
select job,avg(sal) as avgsal from emp where job<>‘MANAGER’ group by job having avg(sal)>1500 order by avgsal desc;
