C++数据结构——二叉树
二叉树
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
二叉搜索树
二叉搜索树是二叉树的一种特殊形式。 二叉搜索树具有以下性质:每个节点中的值必须大于(或等于)其左侧子树中的任何值,但小于(或等于)其右侧子树中的任何值。
我们将在本章中更详细地介绍二叉搜索树的定义,并提供一些与二叉搜索树相关的习题。
完成本卡片后,你将:
- 理解二叉搜索树的特性
- 熟悉在二叉搜索树中的基本操作
- 理解高度平衡二叉搜索树的概念
二叉搜索树的定义
**二叉搜索树(BST)**是二叉树的一种特殊表示形式,它满足如下特性:
- 每个节点中的值必须大于(或等于)存储在其左侧子树中的任何值。
- 每个节点中的值必须小于(或等于)存储在其右子树中的任何值。
注意:指的是任何值,即左/右子树上的所有节点。
下面是一个二叉搜索树的例子:

这段之后,我们提供了一个习题来让你验证一个树是否是二叉搜索树。 你可以运用我们上述提到的性质来判断。 前一章介绍的递归思想也可能会对你解决这个问题有所帮助。
像普通的二叉树一样,我们可以按照前序、中序和后序来遍历一个二叉搜索树。 但是值得注意的是,对于二叉搜索树,我们可以通过中序遍历得到一个递增的有序序列。因此,中序遍历是二叉搜索树中最常用的遍历方法。
在文章习题中,我们也添加了让你求解二叉搜索树的中序后继节点(in-order successor)的题目。显然,你可以通过中序遍历来找到二叉搜索树的中序后继节点。 你也可以尝试运用二叉搜索树的特性,去寻求更好的解决方案。
验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:
2
/ \
1 3
输出: true
示例 2:
输入:
5
/ \
1 4
/
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。
方法1:递归
根据二叉搜索树的定义,我们要知道一个结点的左子树中结点的最大值不会超过结点的值,一个结点的右子树中结点的最小值也会大于结点的值。同时我们能按照中序顺序递归遍历子树。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isValidBST(TreeNode* root,TreeNode* left=NULL,TreeNode* right=NULL)
{
if(root==nullptr) return true;
if(left!=nullptr&&root->val<=left->val)return false;
if(right!=nullptr&&root->val>=right->val)return false;
return isValidBST(root->left,left,root)&&isValidBST(root->right,root,right);
}
};
复杂度分析
- 时间复杂度 : O(n),其中 n 为二叉树的节点个数。在递归调用的时候二叉树的每个节点最多被访问一次,因此时间复杂度为 O(n)。
- 空间复杂度 : O(n),其中 n 为二叉树的节点个数。递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度,即二叉树的高度。最坏情况下二叉树为一条链,树的高度为n ,递归最深达到 n 层,故最坏情况下空间复杂度为 O(n)。
除此之外,还有更简单高效的方法:
二叉树中序遍历,保留前驱结点与当前结点对比,是否小于当前结点,小于则为二叉树。
详解
二叉搜索树迭代器
实现一个二叉搜索树迭代器。你将使用二叉搜索树的根节点初始化迭代器。
调用 next() 将返回二叉搜索树中的下一个最小的数。
示例:
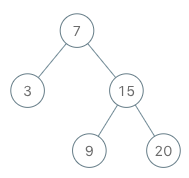
BSTIterator iterator = new BSTIterator(root);
iterator.next(); //返回 3
iterator.next(); // 返回 7
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 9
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 15
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 20
iterator.hasNext(); // 返回 false
方法一:扁平化二叉搜索树
在计算机程序设计中,迭代器是使程序员能够遍历容器的对象。这是维基百科对迭代器的定义。当前,实现迭代器的最简单的方法是构建一个类似数组的容器。如果我们有一个数组,则我们只需要一个指针或者索引,就可以在O(1)的时间复杂度内实现函数 next() 和 hasNext()。
因此,我们要研究的第一种方法就是基于这种思想。我们将使用额外的数组,并将二叉搜索树展开存放到里面。我们想要数组的元素按升序排序,则我们应该对二叉搜索树进行中序遍历,然后我们在数组中构建迭代器函数。
算法:
- 初始化一个空数组用来存放二叉搜索树的中序序列。
- 我们按中序遍历二叉搜索树,按照左中右的顺序处理节点。
- 一旦所有节点都在数组中,则我们只需要一个指针或索引来实现 next() 和 hasNext 这两个函数。每当调用 hasNext()时,我们只需要检查索引是否达到数组末尾; 每当调用 next() 时,我们只需要返回索引指向的元素,并向前移动一步,以模拟迭代器的进度。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class BSTIterator {
vector<int> array;
int index;
public:
BSTIterator(TreeNode* root) {
index = -1;
Iterater(root);
}
void Iterater(TreeNode* root)
{
if(root==nullptr)return;
Iterater(root->left);
array.push_back(root->val);
Iterater(root->right);
return;
}
/** @return the next smallest number */
int next() {
index++;
return array[index];
}
/** @return whether we have a next smallest number */
bool hasNext() {
return index+1< array.size();
}
};
/**
* Your BSTIterator object will be instantiated and called as such:
* BSTIterator* obj = new BSTIterator(root);
* int param_1 = obj->next();
* bool param_2 = obj->hasNext();
*/
复杂度分析
时间复杂度:构造迭代器花费的时间为 O(N),问题陈述只要求我们分析两个函数的复杂性,但是在实现类时,还要注意初始化类对象所需的时间;在这种情况下,时间复杂度与二叉搜索树中的节点数成线性关系。
- next():O(1)
- hasNext():O(1)
空间复杂度:O(N),由于我们创建了一个数组来包含二叉搜索树中的所有节点值,这不符合问题陈述中的要求,任一函数的最大空间复杂度应为 O(h),其中 h 指的是树的高度,对于平衡的二叉搜索树,高度通常为 logN。
在二叉搜索树中实现搜索操作
二叉搜索树主要支持三个操作:搜索、插入和删除。 在本章中,我们将讨论如何在二叉搜索树中搜索特定的值。
1. Search in a Binary Search Tree
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
方法一递归
递归实现非常简单:
- 如果根节点为空 root == null 或者根节点的值等于搜索值 val == root.val,返回根节点。
- 如果 val < root.val,进入根节点的左子树查找 searchBST(root.left, val)。
- 如果 val > root.val,进入根节点的右子树查找 searchBST(root.right, val)。
- 返回根节点。
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if(root==nullptr)return nullptr;
if(root->val==val)return root;
return root->val>val?searchBST(root->left,val):searchBST(root->right,val);
}
};
复杂度分析
时间复杂度:O(H),其中 HH 指的是树的高度。平均情况下 O(logN),最坏的情况下 O(N)。
空间复杂度:平均情况下O(H)。最坏的情况下是O(N),是在递归过程中堆栈使用的空间。
2. Insert into a Binary Search Tree
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 保证原始二叉搜索树中不存在新值。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回任意有效的结果。
方法一:递归
算法:
- 若 root == null,则返回 TreeNode(val)。
- 若 val > root.val,插入到右子树。
- 若 val <root.val,插入到左子树。
- 返回 root。
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(root==nullptr)
{
return new TreeNode(val);
}
//insert to left tree
if(root->val>=val)
{
root->left = insertIntoBST(root->left,val);
}
//insert to right tree
if(root->val<val)
{
root->right = insertIntoBST(root->right,val);
}
//final return value
return root;
}
};
复杂度分析
时间复杂度:O(H),其中 HH 指的是树的高度。平均情况下 O(logN),最坏的情况下 O(N)。
空间复杂度:平均情况下O(H)。最坏的情况下是O(N),是在递归过程中堆栈使用的空间。
3. Delete Node in a BST
重要概念:后继节点和前驱结点
Successor 代表的是中序遍历序列的下一个节点。即比当前节点大的最小节点,简称后继节点。
先取当前节点的右节点,然后一直取该节点的左节点,直到左节点为空,则最后指向的节点为后继节点。
Predecessor 代表的是中序遍历序列的前一个节点。即比当前节点小的最大节点,简称前驱节点。先取当前节点的左节点,然后取该节点的右节点,直到右节点为空,则最后指向的节点为前驱节点。
方法:递归
这里有三种可能的情况:
- 要删除的节点为叶子节点,可以直接删除。

- 要删除的几点不是叶子节点且拥有右节点,则该节点可以由该节点的后继节点进行替代,该后继节点位于右子树中较低的位置。然后可以从后继节点的位置递归向下操作以删除后继节点。

3. 要删除的节点不是叶子节点,且没有右节点但是有左节点。这意味着它的后继节点在它的上面,但是我们并不想返回。我们可以使用它的前驱节点进行替代,然后再递归的向下删除前驱节点。

算法:
- 如果 key > root.val,说明要删除的节点在右子树,root.right = deleteNode(root.right,key)。
- 如果 key < root.val,说明要删除的节点在左子树,root.left = deleteNode(root.left, key)。
- 如果 key == root.val,则该节点就是我们要删除的节点,则:如果该节点是叶子节点,则直接删除它:root = null。
- 如果该节点不是叶子节点且有右节点,则用它的后继节点的值替代root.val = successor.val,然后删除后继节点。
- 如果该节点不是叶子节点且只有左节点,则用它的前驱节点的值替代 root.val = predecessor.val,然后删除前驱节点。 返回 root。
class Solution {
public:
//find the successor node
TreeNode* Successor(TreeNode *root)
{
root = root->right;
while(root->left!=nullptr)
root = root->left;
return root;
}
//find the precessor node
TreeNode* Predecessor(TreeNode *root)
{
root = root->left;
while (root->right != nullptr)
root = root->right;
return root;
}
TreeNode* deleteNode(TreeNode* root, int key) {
if(root==nullptr)return nullptr;
//search node to delete
if(root->val>key)root->left = deleteNode(root->left,key);
if(root->val<key)root->right = deleteNode(root->right,key);
if(root->val==key)
{
//situation1: a leaf
if(root->left==nullptr&&root->right==nullptr)
{
root = nullptr;
}
//situation2: has right child
else if(root->right!=nullptr)
{
int succ = Successor(root)->val;
root->val = succ;
root->right = deleteNode(root->right,succ);
}
//situation3: has left child
else
{
int pred = Predecessor(root)->val;
root->val = pred;
root->left = deleteNode(root->left,pred);
}
}
return root;
}
};
复杂度分析
- 时间复杂度: O(logN)。在算法的执行过程中,我们一直在树上向左或向右移动。首先先用 O(H1) 的时间找到要删除的节点,H 1值得是从根节点到要删除节点的高度。然后删除节点需要 O(H2) 的时间,H2指的是从要删除节点到替换节点的高度。由于 O(H1 +H2 )=O(H),H 值是树的高度,若树是一个平衡树则 H = logN。
- 空间复杂度:O(H),递归时堆栈使用的空间,H 是树的高度。
二叉搜索树简介 - 小结
我们已经介绍了二叉搜索树的相关特性,以及如何在二叉搜索树中实现一些基本操作,比如搜索、插入和删除。熟悉了这些基本概念之后,相信你已经能够成功运用它们来解决二叉搜索树问题。
二叉搜索树的优点是,即便在最坏的情况下,也允许你在O(h)的时间复杂度内执行所有的搜索、插入、删除操作。
通常来说,如果你想有序地存储数据或者需要同时执行搜索、插入、删除等多步操作,二叉搜索树这个数据结构是一个很好的选择。