Pandas 数据操作实践总结
Pandas 数据的选择
相比于Numpy的矩阵,Pandas的数据对象多了自定义的索引。因此,在对Pandas数据选择时,更推荐使用loc和iloc两种方法。
但在数据分析实践中,也会结合.索引、布尔值索引和isin属性等方式。
import numpy as np
import pandas as pd
首先,读取一个用于测试的数据。
test = pd.read_excel("../table.xlsx", sheet_name="Sheet2", index_col=0)
test
| sample1 | sample2 | sample3 | sample4 | group | |
|---|---|---|---|---|---|
| gene1 | 1.0 | 2.000000 | 3.000000 | 4.000000 | case |
| gene2 | 5.0 | 3.000000 | 1.000000 | 2.000000 | control |
| gene3 | 12.0 | 12.000000 | 21.000000 | 13.000000 | case |
| gene4 | 17.0 | 15.666667 | 26.333333 | 15.333333 | control |
| gene5 | 22.5 | 20.666667 | 35.333333 | 19.833333 | case |
| gene6 | 28.0 | 25.666667 | 44.333333 | 24.333333 | control |
| gene7 | 33.5 | 30.666667 | 53.333333 | 28.833333 | case |
| gene8 | 39.0 | 35.666667 | 62.333333 | 33.333333 | control |
| gene9 | 44.5 | 40.666667 | 71.333333 | 37.833333 | case |
| gene10 | 50.0 | 45.666667 | 80.333333 | 42.333333 | control |
| gene11 | 55.5 | 50.666667 | 89.333333 | 46.833333 | case |
| gene12 | 61.0 | 55.666667 | 98.333333 | 51.333333 | control |
| gene13 | 66.5 | 60.666667 | 107.333333 | 55.833333 | case |
| gene14 | 72.0 | 65.666667 | 116.333333 | 60.333333 | control |
| gene15 | 77.5 | 70.666667 | 125.333333 | 64.833333 | case |
| gene16 | 83.0 | 75.666667 | 134.333333 | 69.333333 | control |
| gene17 | 88.5 | 80.666667 | 143.333333 | 73.833333 | case |
| gene18 | 94.0 | 85.666667 | 152.333333 | 78.333333 | control |
| gene19 | 99.5 | 90.666667 | 161.333333 | 82.833333 | case |
通过iloc属性,实现数据的切片选择
iloc属性是通过数据的隐藏索引实现切片选择的。所谓隐藏索引是指数据矩阵的每个轴都有一个有序的0,1,2,…的索引值。
- 如下所示,选择第1行的所有值:
test.iloc[0,:]
sample1 1.0
sample2 2.0
sample3 3.0
sample4 4.0
Name: gene1, dtype: float64
- 选择第1-4行的所有值
test.iloc[1:5,:]
| sample1 | sample2 | sample3 | sample4 | group | |
|---|---|---|---|---|---|
| gene2 | 5.0 | 3.000000 | 1.000000 | 2.000000 | control |
| gene3 | 12.0 | 12.000000 | 21.000000 | 13.000000 | case |
| gene4 | 17.0 | 15.666667 | 26.333333 | 15.333333 | control |
| gene5 | 22.5 | 20.666667 | 35.333333 | 19.833333 | case |
通过loc属性,实现数据的切片选择
loc属性是通过数据的显性索引进行切片选择。所谓显性索引是指用户自己定义的数据索引,如这里的sample1, sample2, gene1,gene2…
如下所示,选择’gene2’这一行和sample1这一列。
test.loc['gene2']
sample1 5
sample2 3
sample3 1
sample4 2
group control
Name: gene2, dtype: object
test.loc[:,'sample1']
gene1 1.0
gene2 5.0
gene3 12.0
gene4 17.0
gene5 22.5
gene6 28.0
gene7 33.5
gene8 39.0
gene9 44.5
gene10 50.0
gene11 55.5
gene12 61.0
gene13 66.5
gene14 72.0
gene15 77.5
gene16 83.0
gene17 88.5
gene18 94.0
gene19 99.5
Name: sample1, dtype: float64
通过.索引选择数据特定的一列
然而,由于该方式可能会与对象属性方法调用重合。例如,如果选择的列名为’shape’,那么就与shape属性相冲突,此时程序会默认为调用shape属性。因此,实际使用过程中需要慎重!
- 选择sample1列
test.sample1
gene1 1.0
gene2 5.0
gene3 12.0
gene4 17.0
gene5 22.5
gene6 28.0
gene7 33.5
gene8 39.0
gene9 44.5
gene10 50.0
gene11 55.5
gene12 61.0
gene13 66.5
gene14 72.0
gene15 77.5
gene16 83.0
gene17 88.5
gene18 94.0
gene19 99.5
Name: sample1, dtype: float64
通过布尔值索引
- 例如,选择sample1列大于5的所有行:
test[test.sample1 > 5]
| sample1 | sample2 | sample3 | sample4 | group | |
|---|---|---|---|---|---|
| gene3 | 12.0 | 12.000000 | 21.000000 | 13.000000 | case |
| gene4 | 17.0 | 15.666667 | 26.333333 | 15.333333 | control |
| gene5 | 22.5 | 20.666667 | 35.333333 | 19.833333 | case |
| gene6 | 28.0 | 25.666667 | 44.333333 | 24.333333 | control |
| gene7 | 33.5 | 30.666667 | 53.333333 | 28.833333 | case |
| gene8 | 39.0 | 35.666667 | 62.333333 | 33.333333 | control |
| gene9 | 44.5 | 40.666667 | 71.333333 | 37.833333 | case |
| gene10 | 50.0 | 45.666667 | 80.333333 | 42.333333 | control |
| gene11 | 55.5 | 50.666667 | 89.333333 | 46.833333 | case |
| gene12 | 61.0 | 55.666667 | 98.333333 | 51.333333 | control |
| gene13 | 66.5 | 60.666667 | 107.333333 | 55.833333 | case |
| gene14 | 72.0 | 65.666667 | 116.333333 | 60.333333 | control |
| gene15 | 77.5 | 70.666667 | 125.333333 | 64.833333 | case |
| gene16 | 83.0 | 75.666667 | 134.333333 | 69.333333 | control |
| gene17 | 88.5 | 80.666667 | 143.333333 | 73.833333 | case |
| gene18 | 94.0 | 85.666667 | 152.333333 | 78.333333 | control |
| gene19 | 99.5 | 90.666667 | 161.333333 | 82.833333 | case |
通过isin属性选择符合的数据
如下,选择所有case的行。
test[test.group.isin(['case'])]
| sample1 | sample2 | sample3 | sample4 | group | |
|---|---|---|---|---|---|
| gene1 | 1.0 | 2.000000 | 3.000000 | 4.000000 | case |
| gene3 | 12.0 | 12.000000 | 21.000000 | 13.000000 | case |
| gene5 | 22.5 | 20.666667 | 35.333333 | 19.833333 | case |
| gene7 | 33.5 | 30.666667 | 53.333333 | 28.833333 | case |
| gene9 | 44.5 | 40.666667 | 71.333333 | 37.833333 | case |
| gene11 | 55.5 | 50.666667 | 89.333333 | 46.833333 | case |
| gene13 | 66.5 | 60.666667 | 107.333333 | 55.833333 | case |
| gene15 | 77.5 | 70.666667 | 125.333333 | 64.833333 | case |
| gene17 | 88.5 | 80.666667 | 143.333333 | 73.833333 | case |
| gene19 | 99.5 | 90.666667 | 161.333333 | 82.833333 | case |
通过 .str.contains() 筛选含某字符的行
- 选择 Chr_Allele 列为字符A的所有行:
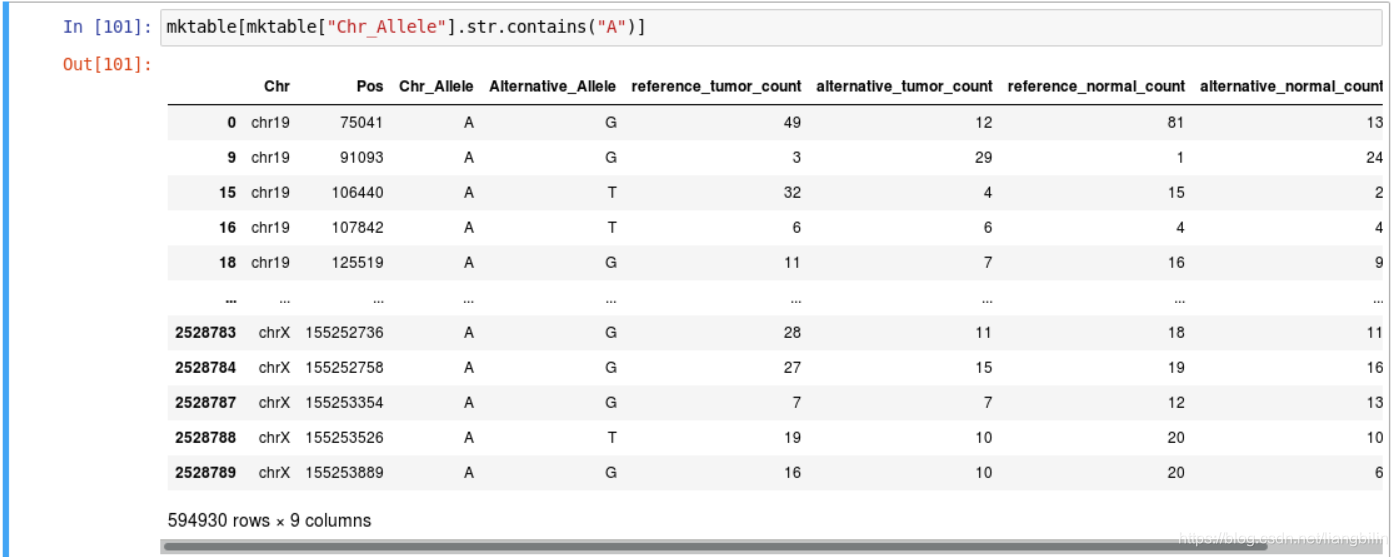
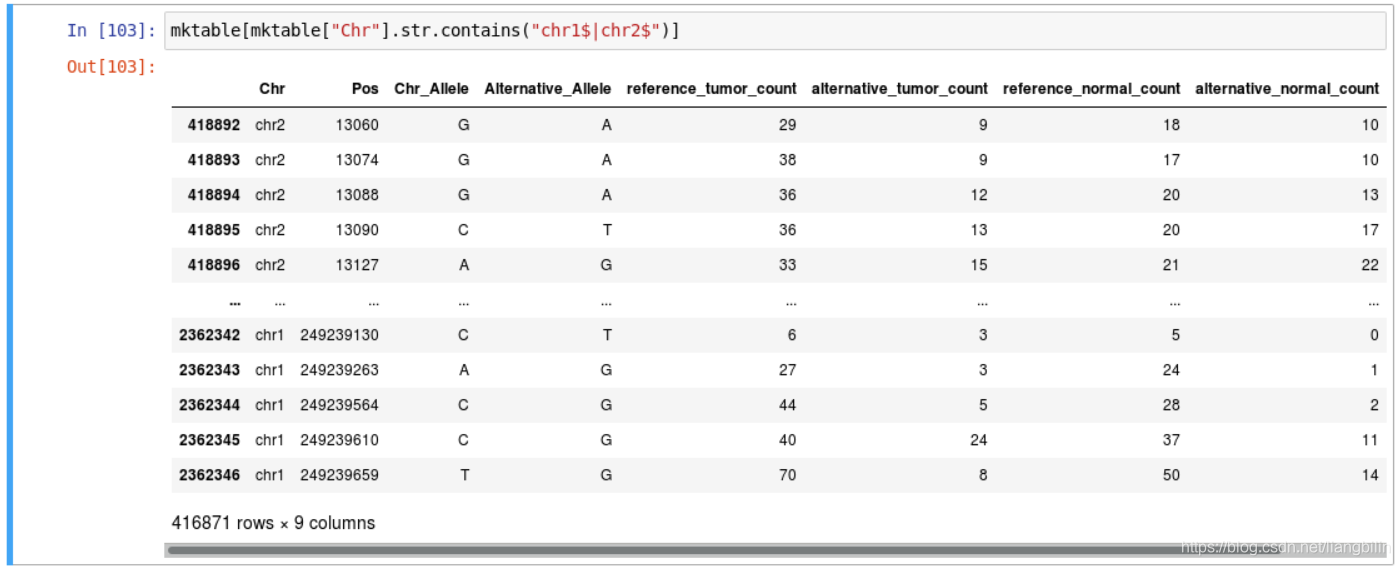
- 筛选条件支持正则表达式。如筛选 Chr 列为 chr1 或 chr2 的所有行。(需要注意的是,都需要用到
$,防止将chr10、chr11等行筛选出来)
通过 .between(start, end) 在数字区域内的所有行
- 如下,筛选出 reference_tumor_count 列的数据在20-30之间的所有行

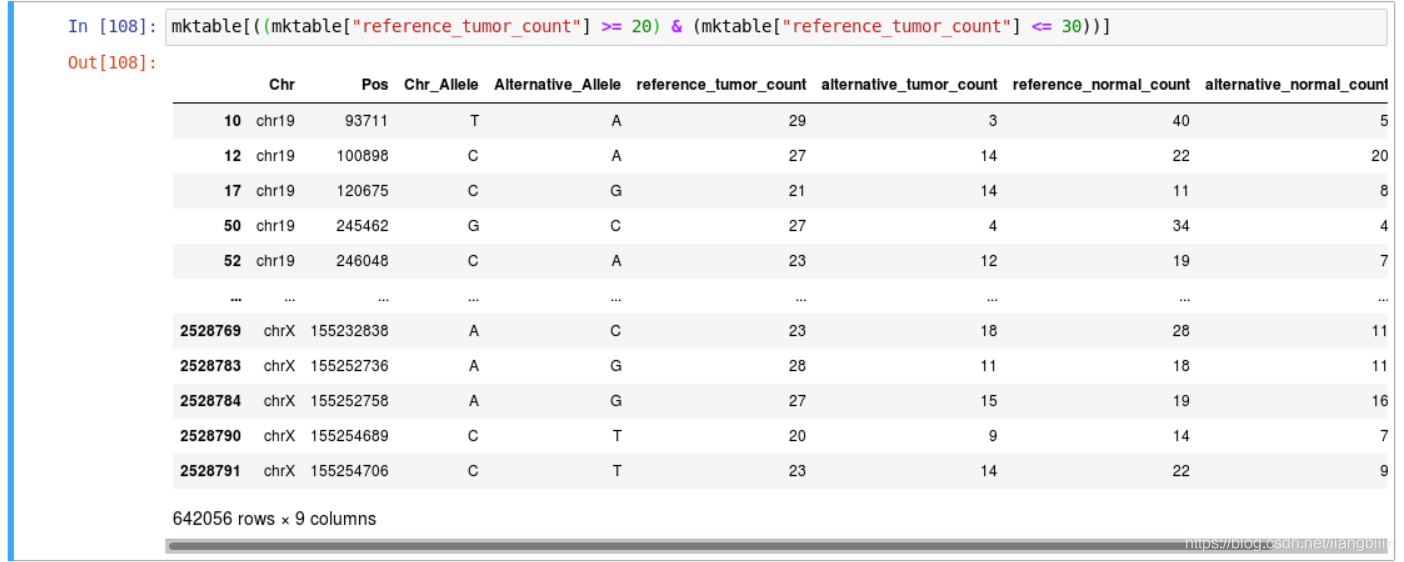
通过 & | 在数字区域内的所有行
-
语法:
table[((条件1) & (条件2))]、table[((条件1) | (条件2))] -
如下得到的结果与
.between结果是一致的。
版权声明:本文为liangbilin原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
THE END