RocketMQ
官方文档:https://github.com/apache/rocketmq/blob/master/docs/cn 中文的很爽
1.AKF拆分
和Kafka一样,broker,topic拆分模式是一样的
2.元数据模型
1. HDFS RocketMQ
汇报模型,每个部分维护自己的元数据,最终汇报给一个主Master 在HDFS中为NameNode,最后对外提供一个可用的元数据列表
2. Kafka
元数据统一维护,所有节点一致,ZK有元数据,每个节点有MetaDataCache
3.消费方式
广播形式: broadcast
1:N 一个消息可以被多个消费者消费,offset自己维护进度
这里就是不同于Kafka常用的消费模型,但是Kafka也能模拟出来这种,Kafka非常自由,由开发者控制,并且自己维护offset
consumer.setMessageModel(MessageModel.BROADCASTING)
集群形式:
1:1 一个消息只能被一个组的一个consumer消费,集群自己维护offset
这里更像Kafka的消费方式,但是offset无需自己维护了
同一个Queue多线程乱序消费: 这种模式才有死信队列,延时队列,类似于Kafka多线程消费一个partition,只不过RocketMQ提供了更好的API和队列维护,以及底层的offset维护
同一个Queue顺序消费: 这种模式没有上述的队列,只能有一个线程消费一个Queue保证有序
4.消息特点
Kafka就是Topic,然后按消息的顺序Segment一个一个添加,每个partition负责管理0-10,10-20这样的Segment 而RocketMQ将消息更细化了,在Topic增加了tag,properties<k,v>的概念,通过子分区的概念将数据进一步划分,有点像预分区,先给某一个范围的数据分好存储位置,这个分区的数据就都放入这个范围 这样设计增加了消息的开销,但是能够适应更多的场景消息队列管道: 使用队列完成RPC调用 两端都需要封装数据的RequestID,才能保证RPC处理的准确性,那么两端都需要编写对消息RequestID的处理和封装的过程,但是RocketMQ在消息上提供了大量的tag等额外的属性,我们可以将RequestID切割出来用额外属性来维护,由RocketMQ维护,无需在两端的业务中自己维护 同时在消费时,RocketMQ的Server可以把tag作为一个过滤条件,在Server端进行过滤以后给消费者,并且还分为简单过滤和复杂SQL过滤
5.消息顺序
和Kafka一样,局部有序,需要有序的只能一个consumer消费 全局有序,只有一个queue就ok了,一个consumer消费 消息的顺序性这里和Kafka中的消息顺序性是一样的,只不过RocketMQ有Queue的概念粒度更细,并且提供了大量的原生API来完成各种消费模型消息顺序的情况以及无需我们关注的offset维护,而Kafka中这些都是要程序员写代码完成的。
6.NameServer

NameServer作为一个生产者和消费者连接并消费的地方,在图中NameServer1可以得到broker1和broker2上报的全量元数据,而NameServer2只能得到broker2的元数据,所以两个NameServer的数据是有差异的 在Kafka中,元数据是一致的,但是在RocketMQ中元数据在NameServer中是有差异的,并且这个差异在RocketMQ中并不是作为问题存在,我们的NameServer是给生产者消费者的,当生产者消费者向同一个缺失的NameServer处理数据,只不过是使用的broker少的问题,对数据没有影响,当生产者向一个完整的NameServer中写数据,消费者消费一个缺失的NameServer读数据,只是读不到完整的数据,这部分不完整的也是没问题的,在RocketMQ中是允许的,合理的。
7.mqadmin
mqadmin作为RocketMQ的管理工具,可以进行创建Topic等
1. 将topic指定创建到某些broker上,指定某些队列
2. 将topic水平创建,通过当前Nameserver能找到的broker,在每个broker上创建若然队列
这里类比kafka,它是创建topic指定partition个数,随机分配到broker上,某些broker上可能没有partition,而RocketMQ是每个broker都创建一个partition,而partition又有更细粒度的read/write queue。
3. 生产者向一个不存在的topic生产数据触发的是配置中Nameserver其中某一个broker进行创建
如果想在其他没有topic的broker中添加topic,只需要在没有的上面执行如下命令
./mqadmin updateTopic -b 'xxxx:10911' -t topic名 -r 数量 -w 数量
最终再次查看topic信息发现没有的也被成功创建,因此NameServer是一个汇总的概念更加明确,想要改变汇总的信息只需要改变broker的信息就可以完成
8.W/RQueue
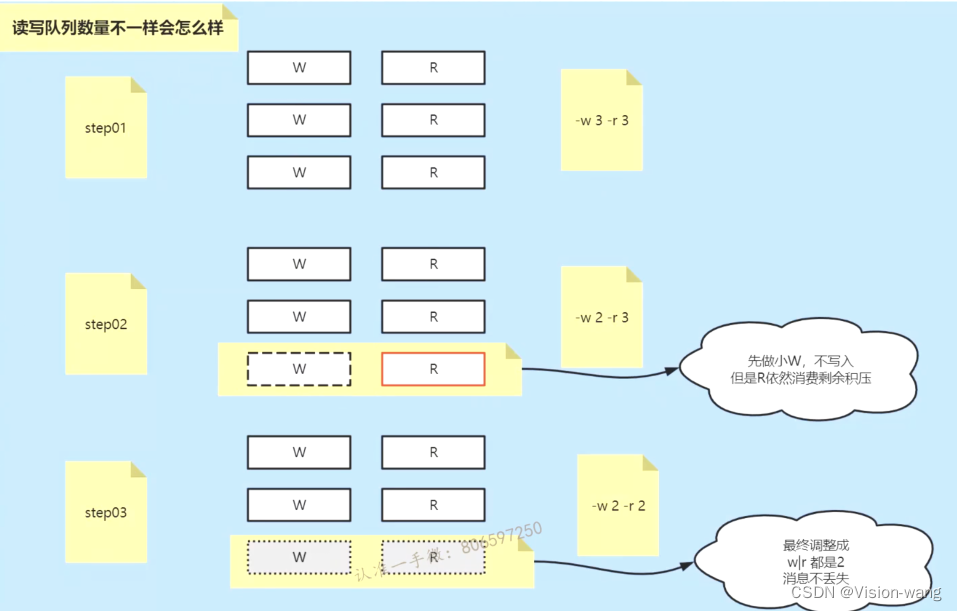
对于Read/Write Queue一般在设计的时候就是为了对等的生产消费,如果想减少Read/Write Queue可以先减少一个Write,这样这个被减少的Write的数据并不会被清理掉,依然可以使用Read进行消费,如果将Write和Read一起减少,那么这个Queue的数据就丢了,显然不合理 所以Write/Read的数量不对等是完全可以的,但是主要是看开发者对于这个队列的目的,如果Write多那就是多的那个Write不消费只生产,反之就是只消费但是消费不到数据而已。 broker是无状态的,每个broker只会维护自己的topic分区(partition但是没有partition的概念)中的Queue
9.集群搭建
#这里的主从模式是对broker进行主从配置,并且可以看到在下面的配置文件中并没有配置多机中主从broker或者broker之间建立联系的配置,因为RocketMQ中broker之间是无状态的,自己维护自己的,无需管别人,只要在NameServer做汇聚就可以了
1. 主机名一定不要带_ -可以使用
2. 目录规划,数据存放的目录
mdkir -p /var/rocketmq/{logs,store/{commitlog,consumerqueue,index}}
{}: 是linux的扩展使用方法,{}中的东西可以拼接上前面的目录
3. /rocketmq/conf存放的是RocketMQ的启动配置文件
在这个目录下有官方的两主两从的案例配置文件夹 2m-2s-async 异步的2主2从配置样例 下面有4个具体的配置文件
2m-2s-sync 同步的2主2从配置样例 下面有4个具体的配置文件
#集群名字
brokerClusterName=DefaultCluster
#通过这个名字的一致建立主从关系
brokerName=broker-a
#master是0,slave是>0
brokerId=0
deleteWhen=04
fileReservedTime=48
#主从间异步数据同步,主配置ASYNC_MASTER,从配置SLAVE
brokerRole=ASYNC_MASTER
#异步刷写磁盘,不是每一条都刷,和Kafka一样,在集群模式中做trade off,使用HA取代每条刷写的可靠性
flushDiskType=ASYNC_FLUSH
#配置nameServer的地址,让broker去注册
namesrvAddr=192.168.76.96,192.168.76.92,192.168.76.94
storePathRootDir=/var/rocketmq/store
storePathCommitlog=/var/rocketmq/store/commitlog
storePathIndex=/var/rocketmq/store/index
storePathConsumerqueue=/var/rocketmq/store/consumerqueue
4. 替换日志目录
日志目录配置在 /rocketmq/conf/ *.xml conf下的所有.xml文件中都有这个log的路径,一个一个替换非常麻烦
sed -i 's#${user.name}#/var/rocketmq#g' *.xml
#默认是一个${user.name}取用户目录的方式配置的log路径,通过sed工具快速的将所有的.xml中${user.name}替换成绝对路径
5. 启动
node02~node04: nameserver
node02~node05: broker
node02: mqbroker -c /opt/rocketmq/conf/22conf/broker-a.properties
node03: mqbroker -c /opt/rocketmq/conf/22conf/broker-a-s.properties
node04: mqbroker -c /opt/rocketmq/conf/22conf/broker-b.properties
node05: mqbroker -c /opt/rocketmq/conf/22conf/broker-b-s.properties
10.集群数据同步方式
同步: sync 异步: async message.setWaitStoreMsgOk(false); 这三种方式,对照Kafka中三种,同步就是-1,异步就是1,主节点确认就可以了,代码控制方式就是0,连主节点都无需确认,就是往里打
11.死信队列,延时队列
消息在乱序消费时,有一下两个概念:
延时队列:
消费者可以在某些消息或者出现一些异常情况时为这个消息加入延时队列,后续进行重投递再次消费
生产者可以直接将消息放入到延时队列
ConsumerConcurrentlyStatus.RECONSUME_LATER //java代码中,加入延时队列
messageDelayLevel=1s 5s 10s 30s 1m 2m.......1h 2h //18种延时级别,重投递的时间间隔步进的
consumer.setMaxReconsumeTimes(2) //java代码配置重投递的最大次数,超过次数不再投递
死信队列:
当延时队列的消息在达到最大重投递次数或者默认的16重投递次数仍然无法被消费,将会别加入到死信队列中
这个死信队列会被RocketMQ的broker维护着,我们程序员可以对这个队列消息再进行后续的处理
这两个队列以group的信息进行维护,由RocketMQ进行维护,不需要自己维护,也提供了非常简单的API就能将消息加入到延时队列和配置进行队列的场景。
Kafka一样可以做这件事,但是需要我们自己在Consumer定义队列,以及向队列中放消息的场景,也就是不再由Kafka进行维护
public class ScheduledMessageProducer {
public static void main(String[] args) throws Exception {
// 实例化一个生产者来产生延时消息
DefaultMQProducer producer = new DefaultMQProducer("ExampleProducerGroup");
// 启动生产者
producer.start();
int totalMessagesToSend = 100;
for (int i = 0; i < totalMessagesToSend; i++) {
Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes());
// 设置延时等级3,这个消息将在10s之后发送(现在只支持固定的几个时间,详看delayTimeLevel)
message.setDelayTimeLevel(3);
// 发送消息
producer.send(message);
}
// 关闭生产者
producer.shutdown();
}
}12.延迟机制
1. 粗粒度:
在RocketMQ中粗粒度是messageDelayLevel这种步进的方式,物理的就是18个这样的队列
如果消息期望30s,那么消息就放入到30s的队列中,RocketMQ的broker通过定时任务到达时间就对这个队列进行一个操作,最简单的就是一个18个任务的线程池,每个线程指定定时任务的时间,到时间就执行一次将指定的Queue消息全部取出进行业务的操作
2. 细粒度:
时间轮:排序成本,分治概念
13.事务
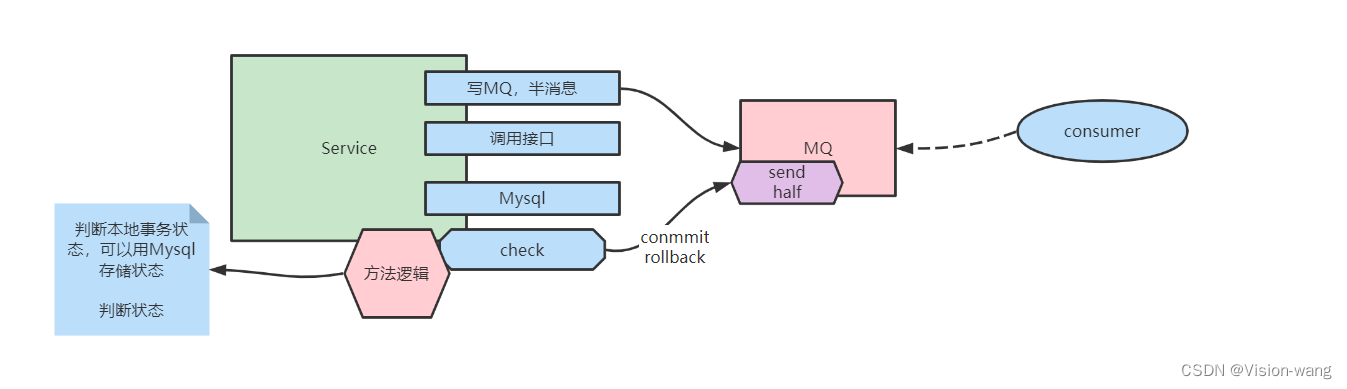
写入到RocketMQServer: RocketMQ的事务一般是和本地事务配合做柔性事务的 RocketMQ本身提供了两阶段提交,只有两阶段都成功,消息才可以被consumer看见,这是中间件级别的事务,而RocketMQ在业务中往往需要和其他的业务代码共同形成一个本地事务,RocketMQ事务只是本地事务的一部分,RocketMQ的第二阶段提交一般都是在本地事务的最后一步进行的,只有在本地事务第二阶段提交前面的操作都成功,RocketMQ的第二阶段提交才成功,RocketMQ才成功,进而整个柔性事务才成功。 RocketMQ的第二阶段类似于一个收尾操作,因为service的前面阶段会有各种各样的问题: 整个service宕机,调用接口Mysql等网络波动,失败,中途的各种异常 因此 预写(半消息half)+本地事务+回查机制(避免service宕机)+最终事务是否commit 才是整个柔性事务
consumer消费: consumer能够消费到的一定是Service完成后的数据,那么在这个阶段消息的异常情况就可以使用RocketMQ提供的延时队列等进行控制,或者只有成功消费offset才移动,进行重复尝试消费的操作。 这里的异常情况不应该再造成service中操作的回滚了,而是进行一套应该出现的流程继续进行下去,如果要service进行回滚,那么就失去了RocketMQ异步进行柔性事务的意义,是一个不正确的使用方式,在tradeoff时,MQ柔性事务本身就应该使用在解耦异步的业务上
1.事务开发
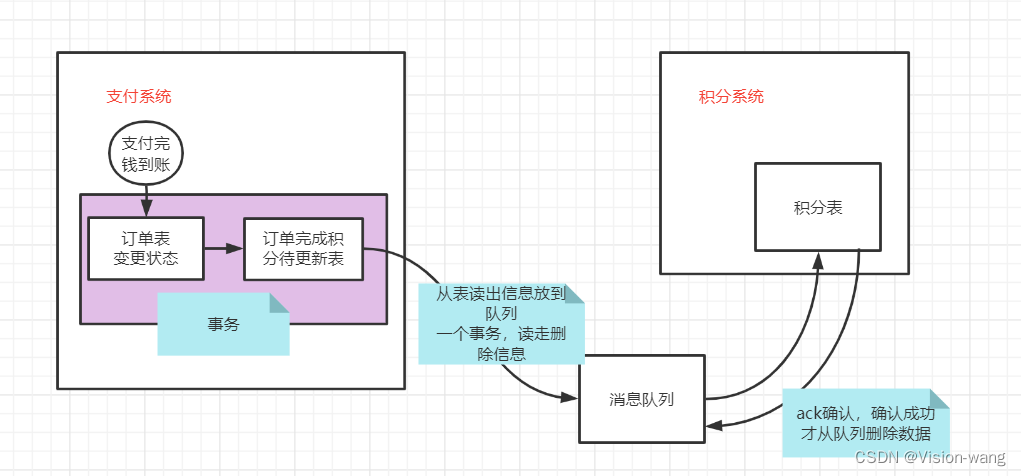
这里写的是伪代码,主要业务就是一个电商系统中,订单和积分的一个处理关系,订单生成以后,一般积分模块的业务是解耦的,如果订单生成以后还要等着积分系统也处理成功才表示这个订单生成成功,显然不太合理,因此这种场景适合使用MQ来做柔性
可不可以积分系统直接操作订单积分待更新表,当然可以,但是如果权限不允许呢? 这里只是举例场景,阐述一些RocketMQ队列实现事务的方式
public class RocketMQExample {
@Test
public void transactionProducer() throws Exception {
TransactionMQProducer producer = new TransactionMQProducer();
producer.setNamesrvAddr("192.168.76.90:9876;192.168.76.92:9876");
//TODO 从订单积分待处理表中获取到一条没有处理过的订单
byte[] order = new byte[10];
//两件事:
//1. half半消息执行成功才能执行本地事务,也需要监听
//2. 半消息的回调需要被监听到
producer.setTransactionListener(new TransactionListener() {
//本地事务需要一些信息才能确定是哪个半消息成功了,才能进一步完成事务
// 信息从哪里来?
// 1. message的body 问题: 1. 消耗网络带宽 2. 可能会污染body的编码 不太好
// 2. userPorperties 1. 通过网络传送给consumer 也不太好
// 3. args方式 local 不需要给consumer传递,RocketMQ就是这么设计的 consumer用不着
@Override
public LocalTransactionState executeLocalTransaction(Message message, Object o) {
//String action = message.getUserProperty("action");
String args = (String) o;
String amsg = message.getBody().toString();
//TODO 删除订单积分待处理表的记录,通过事务id: args
//TODO 将MQ事务表的状态进行变更,通过务id: args
return LocalTransactionState.COMMIT_MESSAGE;
/*
* 状态有2个:
* rocketmq的半消息状态,这个状态启动rocketmq 回查producer
* service应该无状态,那么应该把transactionID 随着本地事务写入到事件状态表中
*/
//某些业务情况,UNKNOW可以被checkLocalTransaction继续检查,在这个案例中没有这种情况,因此也没使用
//return LocalTransactionState.UNKNOW;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt messageExt) {
String transactionId = messageExt.getTransactionId();
byte[] body = messageExt.getBody();
//其实在之前的步骤,不使用额外的事务表,只使用订单积分表中id作为arg,判断订单积分表中数据是否存在也可以做这件事
//TODO 判断订单积分表消息是否还存在,MQ事务表状态是否是本地事务完成的状态
if(状态成功) {
// 走到这里说明本地事务成功了,但是宕机了没有来得及提交第二阶段消息,应该提交上去
return LocalTransactionState.COMMIT_MESSAGE;
}else{
// 走到这里说明本地事务失败了,而我们这里使用的订单积分待处理表失败了记录就没有删除,那么让半消息失效就行
// 这个线程还会去消费订单积分待处理表的记录
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
});
// 可以配置一个线程池用于执行我们向MQ中存放半消息的线程执行器
producer.setExecutorService(new ThreadPoolExecutor(
1,
Runtime.getRuntime().availableProcessors(),
2000,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(2000),
Executors.defaultThreadFactory()
));
Message mgs = new Message();
mgs.setTopic("Topic");
mgs.setBody(order);
// UserPorperties的方式这里没有使用
//mgs.putUserProperty("action","XXX");
//发送的是半消息,除了消息体,还应该携带一个标签(事务id等),用于消息发送成功触发后期本地事务可以识别到
// TODO 在数据库设计一个MQ事务表,包含事务id,事务状态,处理的订单积分待处理表的id,存储一个MQ柔性事务处理id,也就是下面的args
TransactionSendResult res = producer.sendMessageInTransaction(mgs,"msg1");
producer.start();
System.in.read();
producer.shutdown();
}
}2.事务核心问题
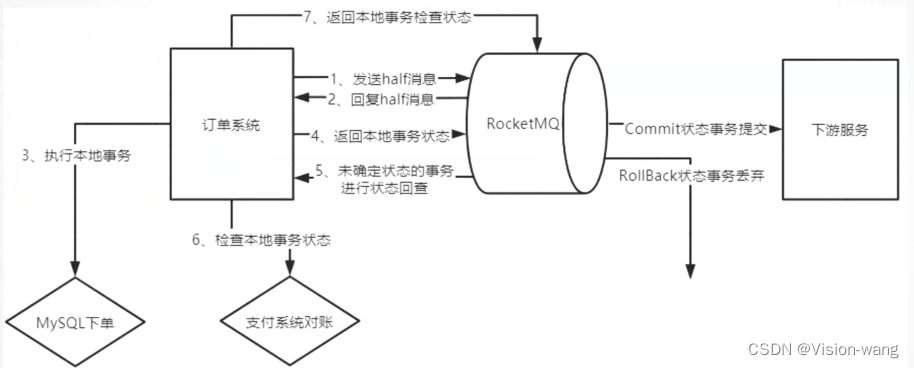
整体流程依赖于上图的RocketMQServer内部保存了半消息的状态,RocketMQ可以对producer发送两种消息
消息一:一种是half存储成功,会触发producer的本地事务执行
消息二:另一种是half存储成功消息发送后,producer发送本地事务状态仍然是Unknown推送的回查消息或迟迟没有收到producer发送本地事务状态主动发送的回查消息
我们在业务设计的时候,在本地事务成功时,发送本地事务状态时是应该设计直接第二阶段提交的,而不应该不管成功失败都走一下回查,回查应该只是一个面对极端情况的兜底做法
下面是极端的几种情况:
1. Service整个宕机,只进行了第一阶段提交,本地事务还没开始
这种情况触发的就是消息二,在回查的业务代码中发现本地业务没做,那么就让半消息失效ROLLBACK_MESSAGE,再重新做一次整个流程呗,重新推half消息,本地事务,回查的整个流程
2. Service整个宕机,第一阶段提交,本地事务执行完,但是没有将第二阶段写回去,说明是在本地事务的COMMIT_MESSAGE时候数据没有发送到RocketMQ就宕机了
这种情况触发的还是消息二,在回查的业务代码中发现本地业务做完了,直接再给RocketMQ发送一个COMMIT_MESSAGE,业务业务圆满成功
3. 本地事务执行之间过长,检查还要不要做
这种情况一定也会触发回查,因为这种情况和1,2一样,都是RocketMQ检测到迟迟没有收到返回本地事务状态
根据不同的业务,做ROLLBACK_MESSAGE(丢弃半消息),UNKNOW(状态不清楚,RocketMQ还会触发回查),COMMIT_MESSAGE(不再回查)
15.Kafka对比
1. 从集群架构上说是两种不同的设计风格:
Kafka中一个broker可以有多个partition,其中某些broker可以是主,某些broker可以是别人的从
RocketMQ中角色独立,一个broker主那么它就是主,如果是从那就是从
这在资源的使用率上,Kafka有更好的优势
2. 元数据
Kafka使用的是集群同步的方式,每个broker持有相同
RocketMQ使用的是独立维护自己的元数据,最终汇报给NameServer汇总
也是两种截然不同的设计风格,这里并没有找到准确的两种设计的优缺点,我认为这样设计可以更好的管理元数据等信息,避免数据多份冗余
3. 数据支持
Kafka并没有对消息进行加工,就是存磁盘,集群同步
RocketMQ在这里对消息提供了大量的细化支持,比如可以维护5W的Queue,消息的Args,UserPorpertis等,以及死信队列等各种应对与业务的数据管理,这里也照应上RocketMQ的设计风格,用更多的资源,更少的数据冗余做更多的事。
4. 计算
Kafka的Server中并没有提供计算
RocketMQ提供了计算相关的过滤,以及两阶段提交的事务处理方式
总结: Kafka实现了数据存储模型,提供了各种扩展方式来符合我们的业务,如果想拥有RocketMQ一样的额外功能就需要自己进行编码开发,RocketMQ在数据存储基础上,还提供了大量的计算支持,很多业务场景使用它的API就能完成而不需要额外开发
所以在两者的Trade off上,要根据业务,以及实现业务的开发成本上进行选择