kafka图解
一、QuickStart

二、Kafka系统化梳理
Kafka 最早是由美国领英公司(下称 Linkedln )的工程师们研发的
linkedIn开源
分布式数据同步系统Databus
高性能计算引擎Cubert
Java异步处理框架ParSeq
Kafka流数据框架
2011年开源
2.1消息引擎系统

1.消息设计
Kafka 的消息是用 二进制 方式。
传统Web使用xml或者json来传输。
2.传输协议设计
目前使用 AMQP Web Service + SOAP 以及微软的 MSMQ为主流协议。
3.消息引擎范型
最常见的两种消息引擎范型是消息队列模型和发布/订阅模型。
消息队列 可以类比火车站买票。
pub/subscribe 可以类比报纸,新闻。
4. JMS
java提供的通用的消息接口API规范。
2.2 Kafka设计在解决什么问题
吞吐量/延时
消息持久化
负载均衡和故障转移
伸缩性
**吞吐量( throughput )在知识引擎中都是至关重要的性能指标
性能指标
| 性能指标 | kafka | rabbitmq |
|---|---|---|
| 吞吐量 | ||
| 延时 | ||
吞吐量和延时是相互矛盾的组合体,即调优其中一 个指标通常会使另一指标变差 当然它们之间的关系也不是等比例地此消彼长的关系,比如牺牲 20% 的延时就能换20%的吞吐量的提升
Kafka 在设计时采用了追加写入消息的方式,即只能在日志文件末尾追加 写入新的消息,且不允许修改己写入的消息,因此它属于典型的磁盘顺序访问型操作,所以 Kafka 消息发送的吞吐量是很高的。 目的追求吞吐量。
1.kafka性能设计
零拷贝技术+大量使用操作系统页缓存,内存操作速度快且命中率高。
Kafka 不直接参与物理 1/0 操作,而是交由最擅长此事的操作系统来完成。
采用追加写入方式,摒弃了缓慢的磁盘随机读/写操作。
2.Kafka的持久化
消息重演---固定会议的创建。
Kafka 实现持久化的设计也有新颖之处。普通的系统在实现持久化时可能会先尽量 使用内存,当内存资源耗尽时,再 次性地把数据“刷盘”;而 Kafka 则反其道而行之, 有数据都会立即被写入文件系统的持久化日志中,之后 Kafka 服务器才会返回结果给客户端通 知它们消息已被成功写入。这样做既实时保存了数据,又减少了 Kafka 程序对于内存的消耗, 从而将节省出的内存留给页缓存使用,更进一步地提升了整体性能
3.负载均衡+心跳实现故障转移
4.伸缩性,依赖zookpeer
小结:
生产者发送-kafka-消费者消费
Kafka 服务器依托 ZooKeeper 集群进行服务的协调管理
2.3 kafka升级之路
兼并了部分下游处理工作-->流处理框架
kafka stream
元数据格式
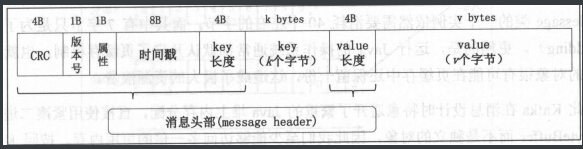
• Key:消息键,对消息做 partition 时使用,即决定消息被保存在某 topic 下的哪个 partition • Value :消息体,保存实际的消息数 • Timestamp :消息发送时间戳,用于流式处理及其他依赖时间的处理语义。如果不指定 则取当前时间
消息
大量使用页缓存而非堆内存还有一个好处一一当出现 Kafka broker 进程崩溃时,堆 内存上的数据也一并消失,但页缓存的数据依然存在。下次 Kafka broker 重启后可以继续提供 服务,不需要再单独“热”缓存了。
2.4 术语
2.41 broker
Kafka 服务器有 个官方名字: broker
2.42 topic和partition

Kafka partition 实际上并没有太多的业务含义,它的引入就是单纯地为 了提升系统的吞吐量,因此在创建 Kafka topic 的时候可以根据集群实际配置设置具体的 partition 数, 实现整体性能的最大。
2.43 offset
topic partition 下的每条消息都被分配一个位移值。实际上 Kafka 消费者端也 有位移( offset )的概念,但 定要注意这两个 offset 属于不同的概念
2.44 唯一组合查询标识--kakfa三元组
kafka中的一条消息就是一个<topic,partition,offset> 三元组(tuple),能够作为唯一的索引查询消息。
2.45 replica
己知 partition 是有序消息日志,那么一定不能只保存这一份日志,否则一旦保partition Kafka 服务器挂掉了,其上保存的消息也就都丢失了。分布式系统必然要实现高可靠性,而目前实现的主要途径还是依靠冗余机制一一简单地说,就是备份多份日志。
副本分为两类 领导者副本( leader replica )和追随者副本( follower replica follower)
leader机制
Kafka 保证同 partition 的多个 replica 一定不会分配在同一台 broker 。毕竟如果同一broker 上有同一个 partition 的多个 replica ,那么将无法实现备份冗余的效果。
isr,am,leo,lag
2.46 ISR
ISR 全称是 in-sync replica
“己提交”状态的消息就不会丢失 ---维护kafka 副本的repla 确认所有副本都同步了已提交状态。
3. kafka的应用场景
主要是 实时流数据、实时流数据管道
为什么呢?官网说明:

| 场景 | |
|---|---|
| 消息传输 | |
| 网站行为日志追踪 | |
| 审计数据收集 | |
| 日志收集 | 日志收集汇总解决方案。每个企业都会产生大量的服务日志,这些日志分散在不同的机器上 我们可以使用 fka 对它们进行全 收集,井集中送往下游的分布式存储中(比如 等) |
| Event Sourcing | Event Sourcing 实际上是领域驱动设计(OOD)思想。 |
| 流式处理 |
三、Kafak 版本
Kafka 0.9 0.0 版本不仅废弃了旧版本 producer ,还提供了新版本的 consumer 同样地,新 版本 consumer 也是使用 Java 编写的,也不再需要依赖 ZooKeeper 的帮助 新版本 consumer 的入口 org.apache.kafka.clients.consumer.KafkaConsumer 由
旧版本 consumer 中,消费位移( offset )的保存与 理都是依托于 ZooKeeper 来完成的 数据 很大且消费很频繁时, ZooKeeper 的读 写性能往往容易成为系统瓶颈
版本选择:
功能场景:
流式处理 0.10.0+
安全 0.9+
消息引擎 无限制
客户端场景:
自行研发客户端和第 方框架提供客户端
第三方框架:
Spark-kafka
以 Storm 为例: Storm 目前提供了两套 Kafka 实际数据传输的插件 stormkafka storm-kafka-client ,

四、Kafka 线上部署
4.1 集群环境
操作系统
谈到 I/O 模型,就不能不说当前主流且耳熟能详的 5种模型:阻塞I/O 、非阻塞I/O 、I/O多路复用、信号驱动 I/O和异步I/O。每一种 模型都有典型的使用场 ,比如 Socket 的阻塞模式和非阻塞模式就对应于前两种模型。
这些和 Kafka 又有什么关系呢?关键就在于 clients 底层网络库的设计。Kafka 新版本 clients 在设计底层网络库时采用了 Java Selector 机制,而后者在 Linux 上的现机制就是巳poll ;但是在 Windows 平台上, Java NIO Selector 层是使用 select 模型而非IOCP 实现的,只有 Java NI02 才是使用 IOCP 实现的 。因此在这一点上,在 Linux 上部Kafka 要比在 Windows 上部署能够得到更高效的 1/0 处理性能。
第二个方面,即数据网络传输效率而言, Linux 也更有优势。具体来说, Kafka 这种 应用必然需要大量地通过网络与磁盘进行数据传输 ,而大部分这样的操作都是通过 Java F ileChannel. transferTo 方法实现的。在 Linux 平台上该方法底层会调用 sendfile 系统调用,即 用了 Linux 提供的零拷贝( Zero Copy )技术。
所以linux 牛B。
磁盘规划
择普通的机械硬盘( HDD )还是固态硬盘 (CSS )
HDD基本就可以了
主要是
JBOD (一大堆普通磁盘)与磁盘阵列(下称 RAID )之争。
磁盘容量
如果每天1 亿条消息,那么每天 生的消息会占lKB I 1000 I 1000 = 200GB 的磁盘空间 我们最好再额外预留 10% 的磁盘空间用于其他数据文件(比如索引文件等)的存储,因此在这种使用场景下每天新发送的消息将占用210GB 左右的磁盘空间因为还要保存 周的数据,所以整体的磁盘容 规划是 210*7=1.5TB,clients 启用了消息压缩,我们可以预估 1个平均的压缩比(比如 0. 5,那么整体的磁盘容量就是 0.75TB )
相关因素: • 新增消息数。 • 消息留存时间。 • 平均消息大小 • 副本数。 • 是否启用压缩
内存
总之对于内存规划的建议如下。 • 尽量分配更多的内存给操作系统的 page cache • 不要为 broker 设置过大的堆内存,最好不超过 6GB • page cache 大小至少要大于一个日志段的大小。
CPU
对 CPU 资源规划的建议如下 • 使用多核系统, CPU 核数最好大于 • 如果使用 Kafka 0.10 0.0 之前的版本或 clients 端与 broker 端消息版本不一致(若无显式 配置,这种情况多半由 clients broker 版本不一致造成),则考虑多配置 些资源以 防止消息解压缩操作消耗过多 CPU
带宽
带宽主要也有两种: lGb/s lOGb/s ,即平时所说的千兆位网络和万兆位网络。无论是哪种带宽,对于大多数的 Kafka 集群来说都足矣了。
样例:
• CPU 24 核。 •.内存 32GB • 磁盘 lTB 7200 SAS 盘两块 • 带宽 lGb/s • ulimit -n 1000000 • Socket Buffer 至少 64KB一一适用于跨机房网络传输。
4.2 性能测试
生产者测试
katka-producer-perf-test 脚本是 Kafka 提供的用于测试 producer 性能的脚本
消费者测试
katka-consumer-perf-test 脚本
4.3 参数设置:
Kafka 集群涉及的
• broker 参数。 • topic 级别参数 • GC 配置参数。 • Jvm参数。 • OS 参数。
| 参数 | |
|---|---|
| broker | 1.broker.id标识broker.2.log.dirs持久化消息目录3.zoo keeper.connect4.listeners一-broker 监听器的 csv 列表,5.advertised.listeners一一平日 listeners 类似,该参数也是用于发布给 clients 的监昕器,不过该参数主要用于 IaaS 环境。6.unclean.leader.election.enable-7.delete.topic.enable一一是否允许 Kafka 删除 topic 。8.log.retention.消息留存时间 9.log.retention.bytes--空间留存.10.min.insync.replicas-一该参数其实是与 producer 端的 acks 参数配合使用的11.num.network threads一一一个非常重要的参数 它控制了 broker 在后台用于处理网络请求的线程数,默认是3 。12.num.io.threads-一这个参数就是控制 broker 端实际处理网络请求的线程数.13.message.max. es-Kafka broker 能够接收的最大消息大小,默认是 977KB,还不到lMB ,可见是非常小的。在实际使用场景中,突破 lMB 大小的消息十分常见,最好重配置。 |
| topic | 1.delete.retention.ms-一每个 topic 可以设置自己的日志留存时间以覆盖全局默认值。2.max.message.bytes一一覆盖全局的 message.max.bytes ,即为每个 topic 指定不同的最大消息尺寸。3.retention. bytes 一一覆盖全局的 log.retention. bytes ,每个 topic 设置不同的日志留存尺寸关于如何设置 topic 级别的参数。 |
| GC | 1. 如果用户机器上的 CPU 资源非常充裕,那么推荐使用 CMS 收集器 这样可以充分利用多 CPU 执行并发垃圾收集 启用方法为-:XX:+UseCurrentMarkSweepGC 2.相反地,则使用吞吐量收集器,即所谓的 throughput collector 这样不会挤占紧张的CPU 资源,使 Kafka broker 达到最大的吞吐量 启用方法为-XX:+UseParallelGC |
| JVM | -Xmx6g -Xms6g -XX:MetaspaceSize=96m -XX:+UseGlGC -XX:MaxGCPauseMillis=20 -XX: Ini tiatingHeapOccupancyPercent=35 - XX : G1HeapRegionSize=l 6M -XX: MinMetaspaceFreeRatio=SO -XX: MaxMetaspaceFreeRatio=80 |
| OS | 1.文件描述符限制:设置方法为 ulimit -n 100000 2.更长的 flush 时间 :我们知道 Kafka 依赖 OS 页缓存的“刷盘”功能实现消息真正写入物理磁盘,默认的刷盘问隔是 秒。通常情况下,这个间隔太短了,适当增加该加时间。 |