【ML】embeding是什么?怎么理解?生成方式有哪些?
1.什么是embedding?
简单来说,embedding就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。
性质:
1.embedding向量能使距离相近的向量对应的物体有相近的含义。比如 Embedding(复仇者联盟)和Embedding(钢铁侠)之间的距离就会很接近,但 Embedding(复仇者联盟)和Embedding(乱世佳人)的距离就会远一些。
2.Embedding还具有数学运算的关系,比如Embedding(马德里)-Embedding(西班牙)+Embedding(法国)≈Embedding(巴黎)
Embedding能够用低维向量对物体进行编码还能保留其含义的特点非常适合深度学习。在传统机器学习模型构建过程中,我们经常使用one hot encoding对离散特征,特别是id类特征进行编码,但由于one hot encoding的维度等于物体的总数,比如阿里的商品one hot encoding的维度就至少是千万量级的。这样的编码方式对于商品来说是极端稀疏的,甚至用multi hot encoding对用户浏览历史的编码也会是一个非常稀疏的向量。而深度学习的特点以及工程方面的原因使其不利于稀疏特征向量的处理(补充一篇文章,为什么dnn不利于处理稀疏特征向量)。
2.怎么理解embeding?embeding的过程?
平时口中所述embeding,指的是一个概念,表示将一个物体映射为低维向量的这一动作。TensorFlow中的embeding层是神经网络的一个层,跟全连接层同等级别。
embedding的过程是什么样子的呢?它其实就是一层全连接的神经网络(问题:神经网络怎么训练?反向传播更新网络参数),如下图所示([1]中描述的非常好,这里摘下来):
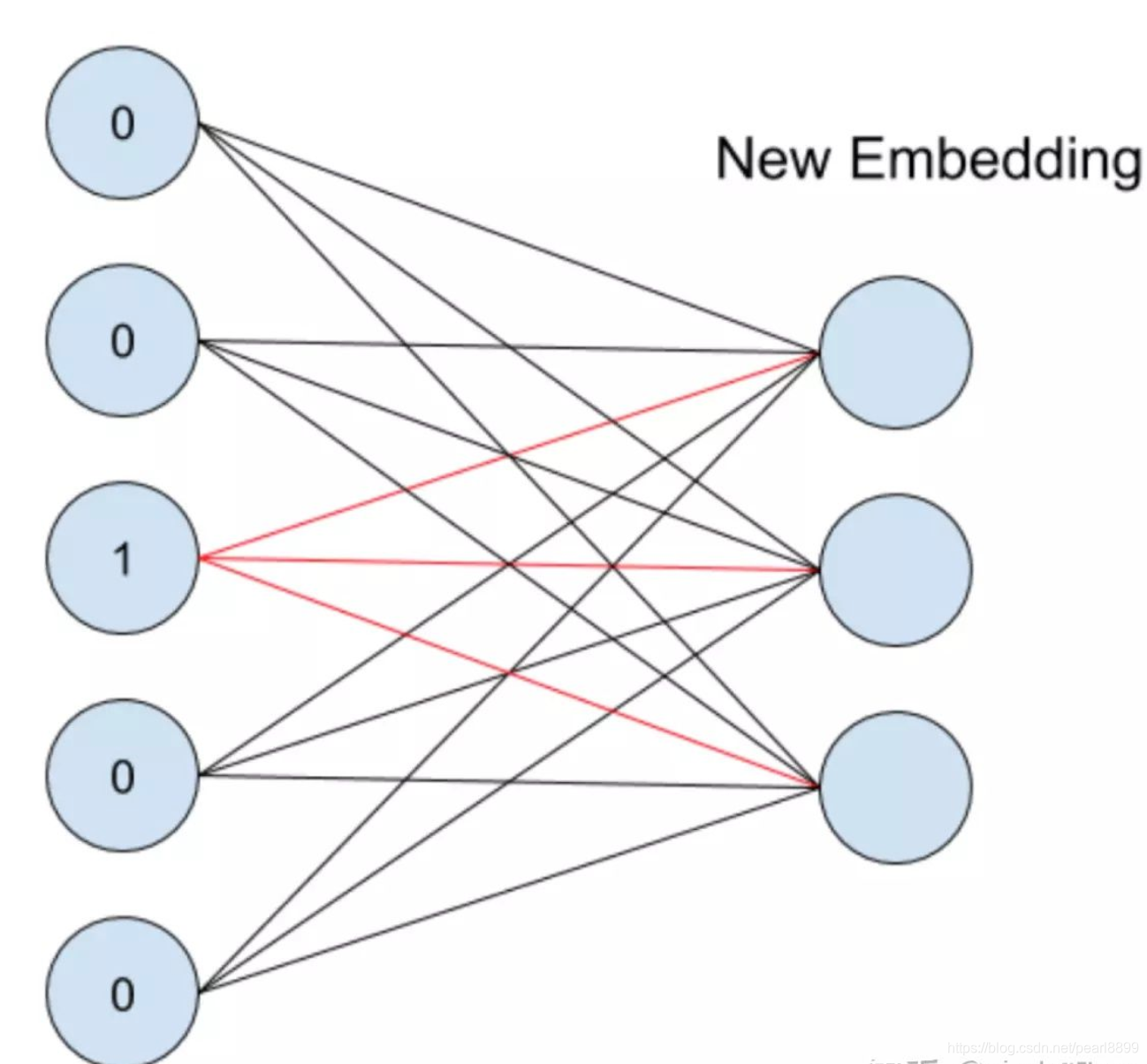
假设一个特征共有5个取值,也就是说one-hot之后会变成5维,我们想将其转换为embedding表示,其实就是接入了一层全连接神经网络。由于只有一个位置是1,其余位置是0,因此得到的embedding就是与其相连的图中红线上的权重,也就是输入节点是1时,对应输出节点的权重,组合在一起,成为一个向量,就是我们要的embeding向量。
2.word2vec将embeding推上了高点
将每一个item表示为向量,用户也表示为向量,计算用户和召回item list的相似度,可作为一个新的特征用于预测。
3.生成embeding向量的方法:
3.1MF
3.2word2vector
Item2Vec 与 MF 有什么区别?
首先,二者都应用了隐向量来表征实体特征,不同的是,传统的 MF 通常是 user-item 矩阵,而 Item2Vec 通过滑动窗口样本生成的方式构造出的则更像是 item-item 矩阵;另外,二者得到隐向量的方式也不同,MF 利用均方差损失,使预测得分与已有得分之间的误差尽可能地小,而 Item2Vec 则是利用空间信息并借助了最大似然估计的思想,使用对数损失,使上下文关系或者共现关系构造出的正样本的 item Pair 出现的概率可能地大;此外训练 Item2Vec 的时候还要引入负样本,这也是与 MF 不同的地方。
对于二者在推荐效果上的差异,一个经验是传统 MF 推荐会让热门内容经常性排在前面,而 Item2vec 能更好的学到中频内容的相似性。Iterm2Vec 加上较短的时间窗口,相似推荐会比 MF 好很多。5
Embedding 的在推荐下局限性
在推荐算法中使用 Embedding 有个前提,item 必须很庞大,如果 item 很小,估计效果就很不理想。也就是说,如果推荐的候选集很小(比如是供应商,供应商一般不会很大),此方法可能会失效(为什么呐?权重学习不充分?)。
3.3graphembeding
待学习
4.4 TensorFlow中的embedding_lookup函数来实现emedding。
# embedding,设置好了权重矩阵,其来源可以是预训练的,也可以是通过BP学习得到,这里应该是定义了一个权重矩阵
embedding = tf.constant(
[[0.21,0.41,0.51,0.11]],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]],dtype=tf.float32)
#输入,首先将其one-hot,然后通过embedding_lookup操作表示出feature_batch每一维输入的embeding向量
feature_batch = tf.constant([2,3,1,0])
get_embedding1 = tf.nn.embedding_lookup(embedding,feature_batch)上面的代码计算过程如下:

解释下:
1)举个例子,从[2, 3, 1, 0]中拿出[1, 0]进行onehot,这里有四个维度,所以one-hot之后,有4维,单看[1, 0],他的onehot结果:
[ [1, 0, 0, 0], [0, 1, 0, 0] ],其中红色表示的是[1, 0]中的1,黑色的表示[1, 0]中的0,1代表的原始数据在1这个索引位上有值,没有大小的含义。

[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
那如果按照上述矩阵计算的方式进行计算,是否能得到跟embeding_lookup函数一样的结果呢?
embedding = tf.constant(
[
[0.21,0.41,0.51,0.11],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
],dtype=tf.float32)
feature_batch = tf.constant([2,3,1,0])
feature_batch_one_hot = tf.one_hot(feature_batch,depth=4)
get_embedding2 = tf.matmul(feature_batch_one_hot,embedding)答案是肯定的。得到结果一致,不信你试试~~。通过上面的讲解,embedding_lookup函数的作用更像是一个搜索操作,即根据我们提供的索引,从对应的tensor中寻找对应位置的切片。
关于embedding_lookup函数,想了解更多,可以去看看tf中的gather函数。
如果想要在神经网络中使用embedding层,推荐使用Keras,下面是demo:
num_classes=10
input_x = tf.keras.Input(shape=(None,),)
embedding_x = layers.Embedding(num_classes, 10)(input_x) #将输入进行embeding
hidden1 = layers.Dense(50,activation='relu')(embedding_x) # 隐藏层50个节点
output = layers.Dense(2,activation='softmax')(hidden1) #输出 激活函数是softmax
x_train = [2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7]
y_train = [0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1]
model2 = tf.keras.Model(inputs = input_x,outputs = output)
model2.compile(optimizer=tf.keras.optimizers.Adam(0.001),
#loss=tf.keras.losses.SparseCategoricalCrossentropy(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model2.fit(x_train, y_train, batch_size=4, epochs=1000, verbose=0)4.Embedding 在推荐中的一些用法:
- 获得用户和物品的隐语义表达
- 作为深度神经网络的输入
- 根据物品映射得到的特征向量去找相似的物品
从word2vec到item2vec
在word2vec诞生之后,embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,我们既然可以对一个序列中的词进行embedding,那自然可以对用户购买序列中的一个商品,用户观看序列中的一个电影进行embedding。而广告、推荐、搜索等领域用户数据的稀疏性几乎必然要求在构建DNN之前对user和item进行embedding后才能进行有效的训练。
具体来讲,如果item存在于一个序列中,item2vec的方法与word2vec没有任何区别。而如果我们摒弃序列中item的空间关系,在原来的目标函数基础上,自然是不存在时间窗口的概念了,取而代之的是item set中两两之间的条件概率。
YouTube在serve其candidate generation model的时候,只将最后softmax层的输出矩阵的列向量当作item embedding vector,而将softmax之前一层的值当作user embedding vector。在线上serving时不用部署整个模型,而是只存储user vector和item vector,再用最近邻索引进行快速搜索,这无疑是非常实用的embedding工程经验,也证明了我们可以用复杂网络生成user和item的embedding。
spark官网中,mllib中代码,有相关代码实现,可以落地,应用到真实业务场景中,并且效果正向。
Embedding 本质上也是体现物品关联,但是比协同过滤的覆盖度高。
aribnb的论文可以仔细研读几遍
1.相比One-hot编码,Embedding方法能够得到更紧凑的向量表示。
参考链接:
1.tf中的embeding:https://zhuanlan.zhihu.com/p/85802954
2.