【NLP开发】Python实现图片文字识别
🍺NLP开发系列相关文章编写如下🍺:
- 🎈【NLP开发】Python实现词云图🎈
- 🎈【NLP开发】Python实现图片文字识别🎈
- 🎈【NLP开发】Python实现中文、英文分词🎈
- 🎈【NLP开发】Python实现聊天机器人(ELIZA))🎈
- 🎈【NLP开发】Python实现聊天机器人(ALICE)🎈
- 🎈【NLP开发】Python实现聊天机器人(ChatterBot)🎈
- 🎈【NLP开发】Python实现聊天机器人(微软Azure)🎈
- 🎈【NLP开发】Python实现聊天机器人(微软小冰)🎈
- 🎈【NLP开发】Python实现聊天机器人(钉钉机器人)🎈
- 🎈【NLP开发】Python实现聊天机器人(微信机器人)🎈
OCR 的前身是光学字符识别,它对当今的数字世界具有革命性意义。OCR 实际上是一个完整的过程,在此过程中,数字世界中存在的图像/文档被处理,文本被处理成普通的可编辑文本。
1、Tesseract
Tesseract最初由惠普实验室支持,用于电子版文字识别,1996年被移植到Windows上,1998年进行了C++化,在2005年Tesseract由惠普公司宣布开源。2006年到现在,由Google公司维护开发。
最初Tesseract是用C语言写的,在1998年改用C++。
1.1 下载安装
https://digi.bib.uni-mannheim.de/tesseract/
https://tesseract-ocr.github.io/tessdoc/Data-Files
下载Tesseract的安装程序如下:
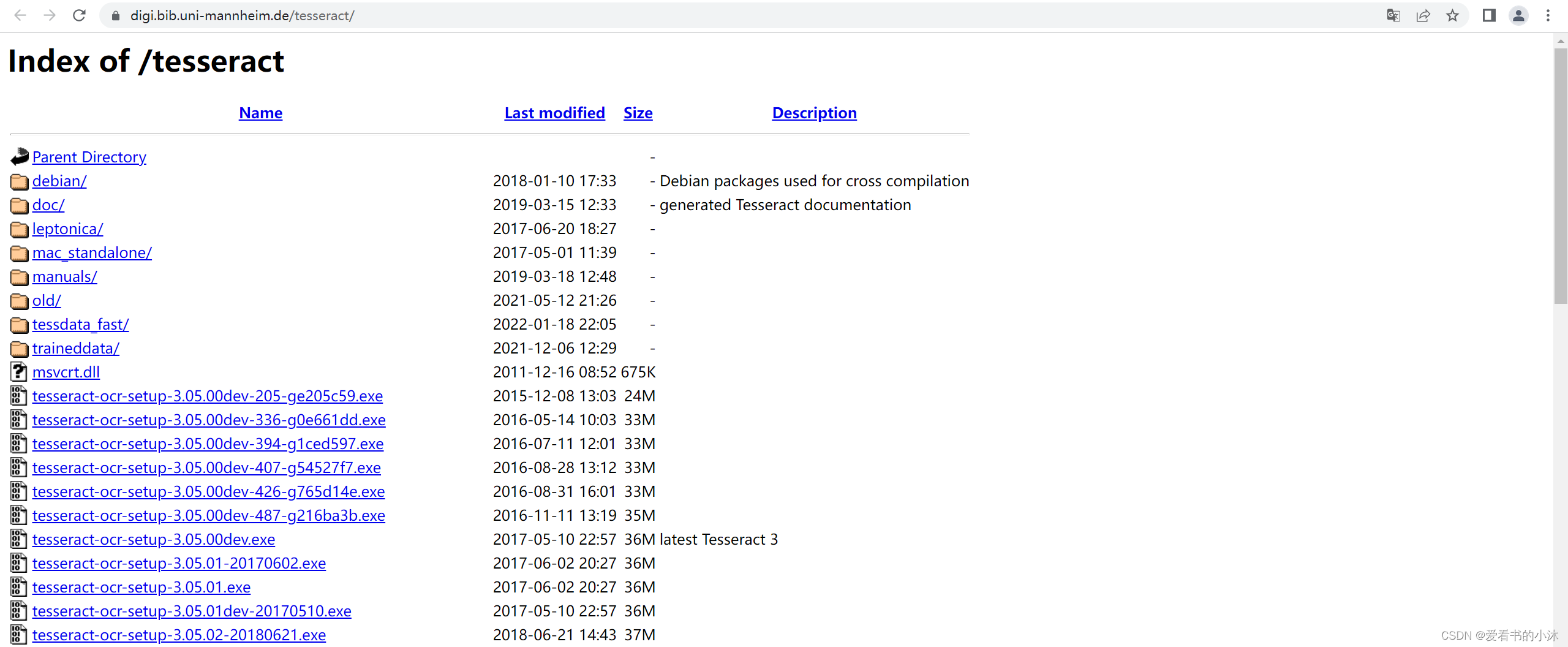
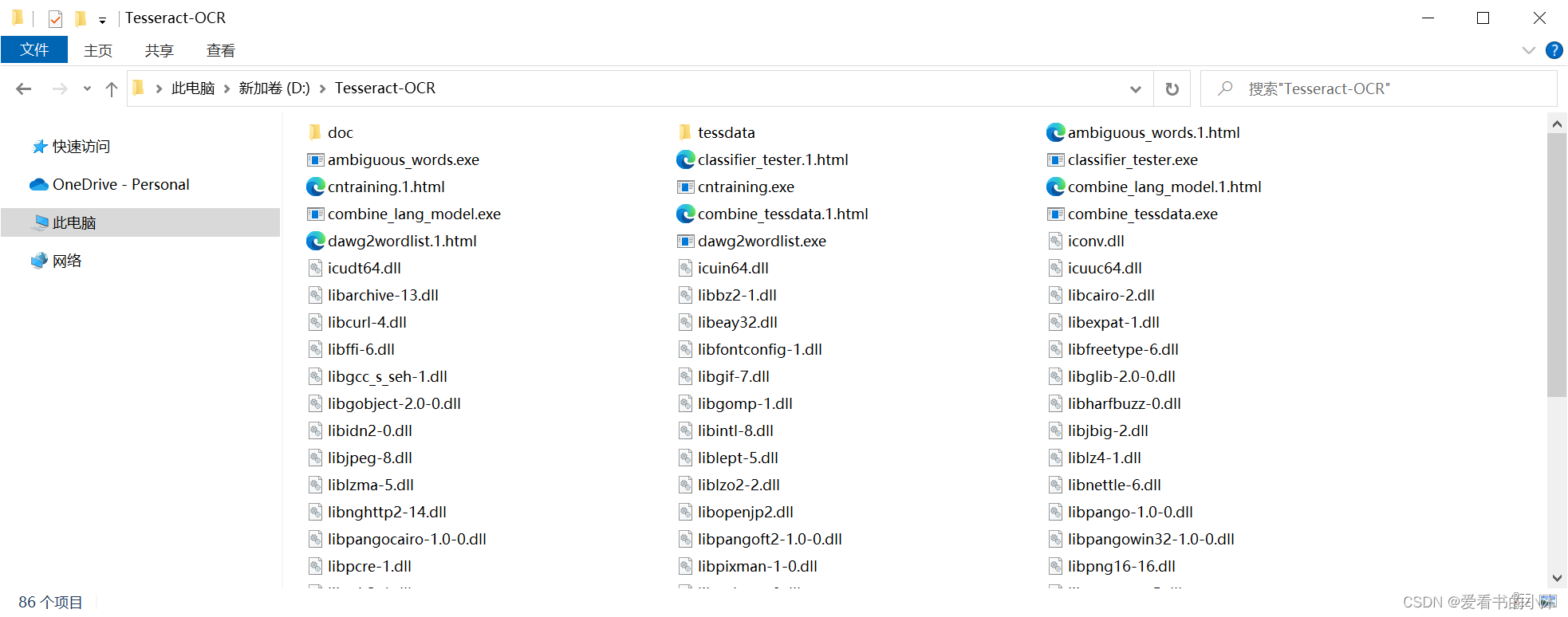
安装Tesseract后,文件夹如下:
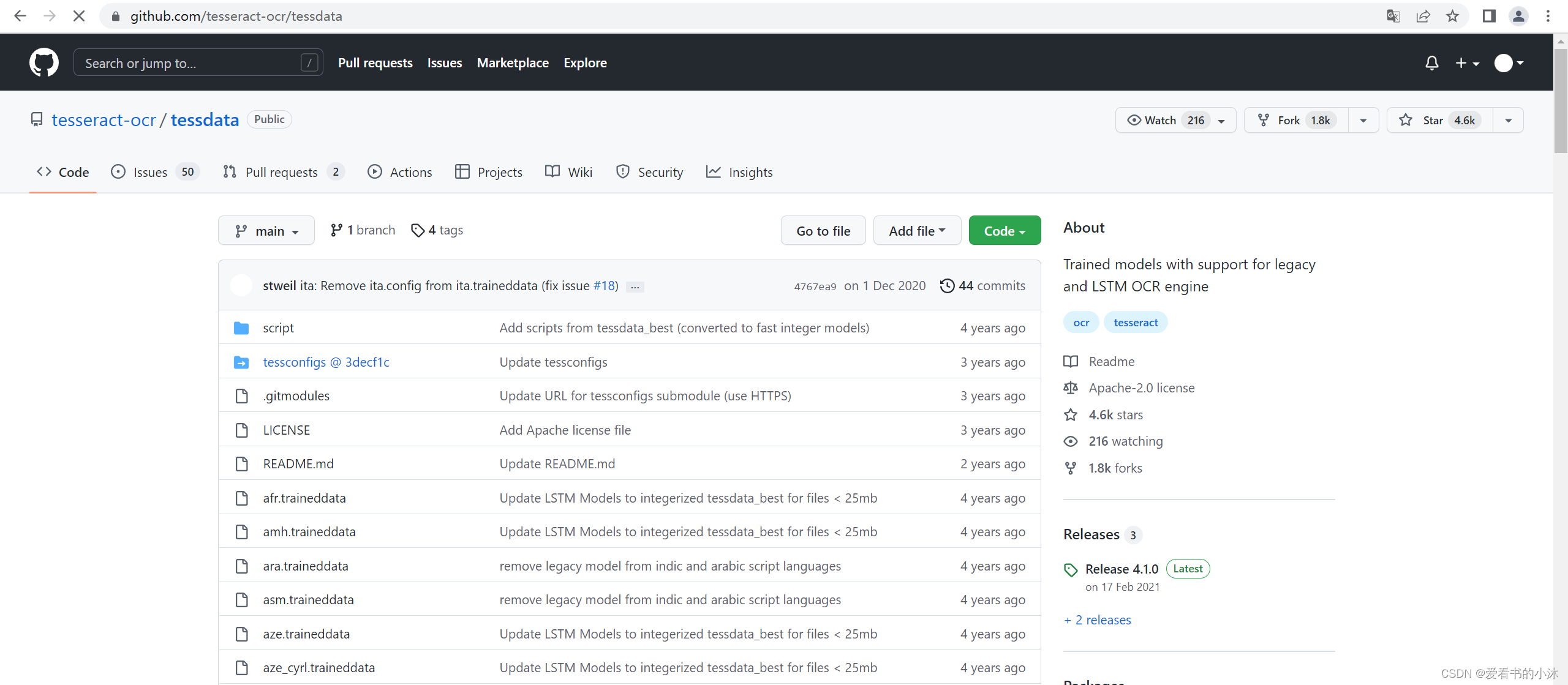
下载中英文语言包:
https://github.com/tesseract-ocr/tessdata
1.2 命令行
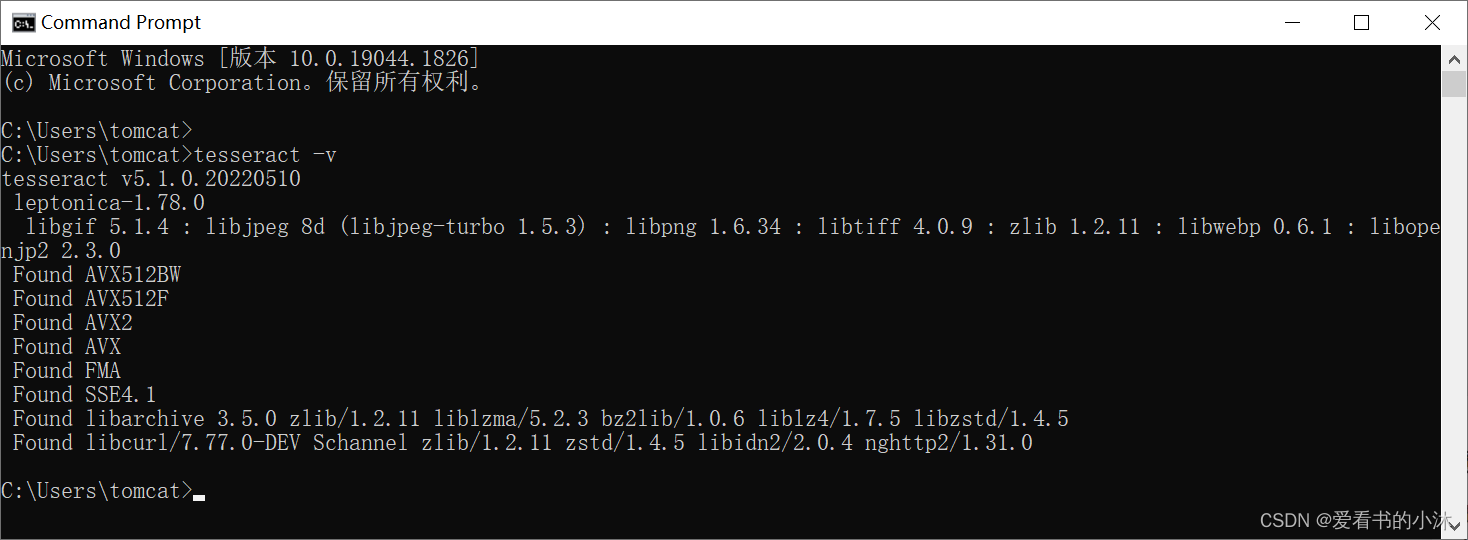
- (1)安装测试
tesseract -v
- (2)识别图片中文字
tesseract imagename outputbase [-l lang] [–psm pagesegmode] [configfile…]
解释:tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
tesseract d:\20190219162542304.png result

- 测试的图片d:\20190219162542304.png:
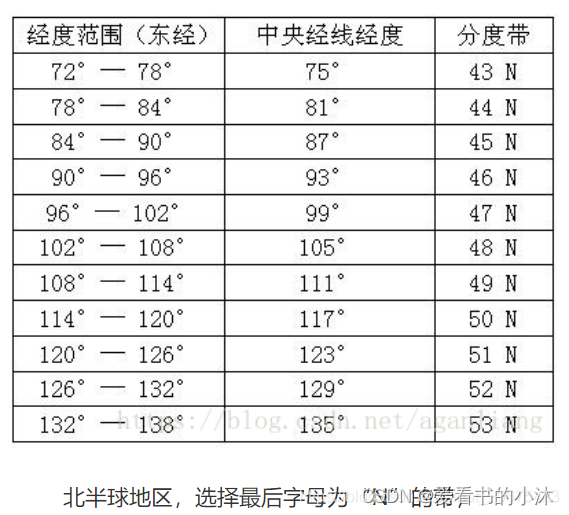
- 测试的结果文件如下:
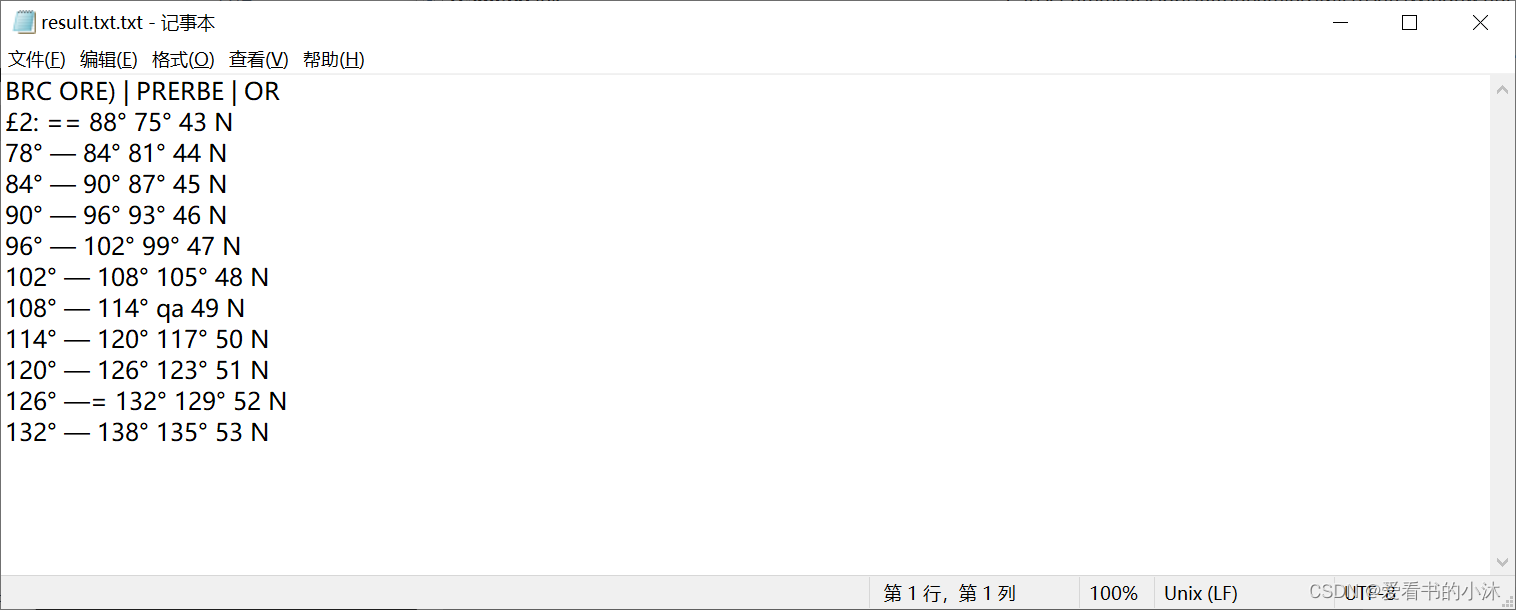
使用中文语言包再次进行识别:
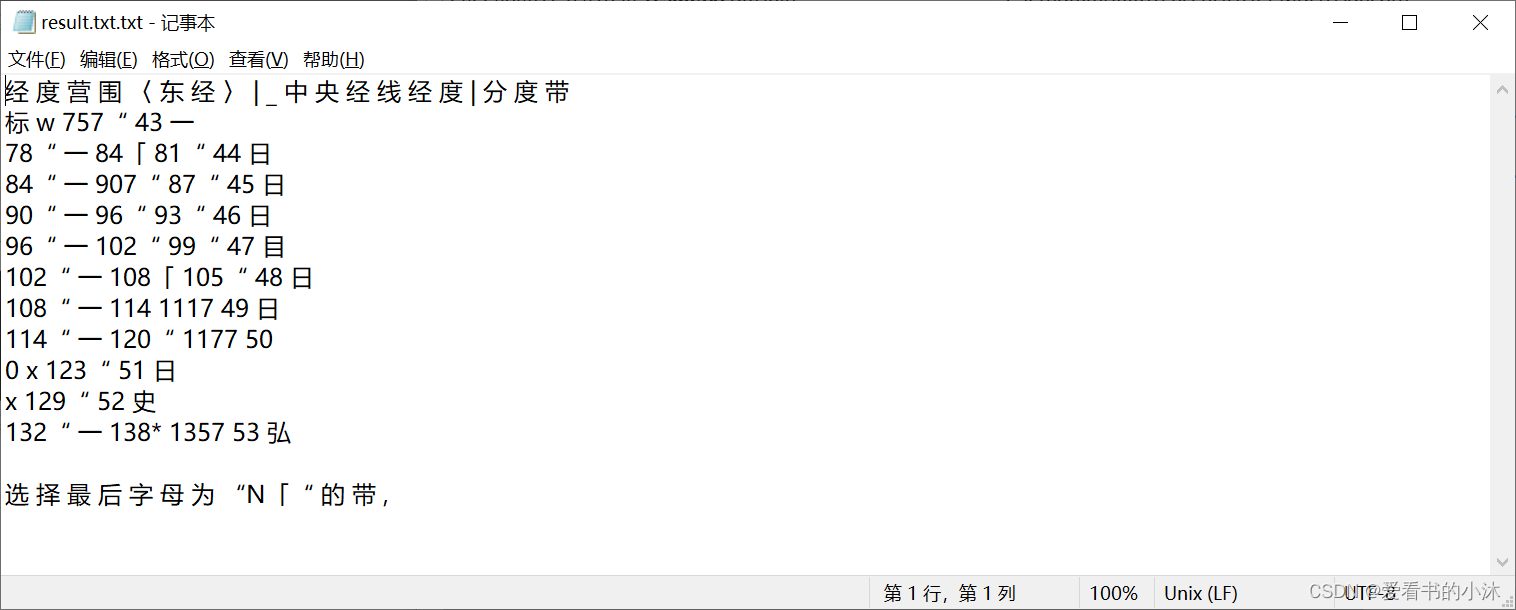
tesseract d:\20190219162542304.png result -l chi_sim

- 测试的结果文件如下:
此外还有一个参数psm:比如tesseract test.jpg result -l eng --psm 7 nobatch
psm 参数说明:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
1.3 python接口
- 安装库:
pip install pytesseract
pip install pillow
- 测试代码:
import pytesseract
from PIL import Image
# 读取图片
im = Image.open('sentence.jpg')
# 识别文字
string = pytesseract.image_to_string(im)
print(string)
import pytesseract
from PIL import Image
# 读取图片
im = Image.open('sentence.png')
# 识别文字,并指定语言
string = pytesseract.image_to_string(im, lang='chi_sim')
print(string)
import os
import pytesseract
# 文字图片的路径
path = 'text_img/'
# 获取图片路径列表
imgs = [path + i for i in os.listdir(path)]
# 打开文件
f = open('text.txt', 'w+', encoding='utf-8')
# 将各个图片的路径写入text.txt文件当中
for img in imgs:
f.write(img + '\n')
# 关闭文件
f.close()
# 文字识别
string = pytesseract.image_to_string('text.txt', lang='chi_sim')
print(string)
2、EasyOCR
2.1 简介
EasyOCR 实际上是一个 Python 包,它将 PyTorch 作为后端处理程序。
EasyOCR 像任何其他 OCR(Google 的 tesseract 或任何其他)一样检测图像中的文本,但我在使用它时,我发现它是从图像中检测文本的最直接的方法,而且它将 PyTorch 作为后端处理程序,准确性更可靠。
EasyOCR 支持 42 多种语言进行检测。EasyOCR 是由 Jaided AI 公司创建的。
2.2 安装
Ready-to-use OCR with 80+ supported languages and all popular writing scripts including: Latin, Chinese, Arabic, Devanagari, Cyrillic, etc.
https://pypi.org/project/easyocr/
pip install easyocr
在线测试如下:
https://www.jaided.ai/easyocr/
- 测试图片如下:
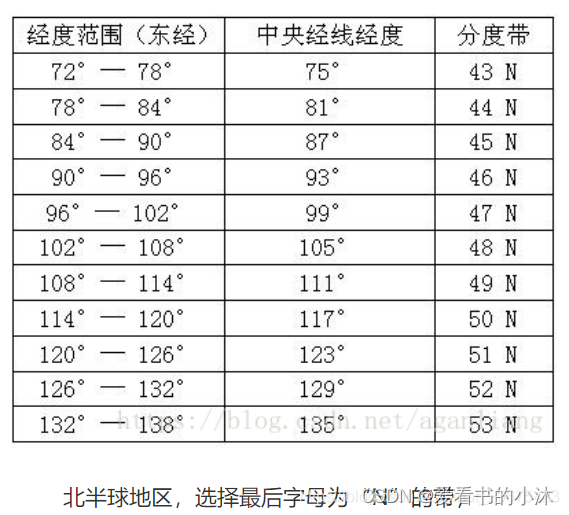
- 识别结果如下:
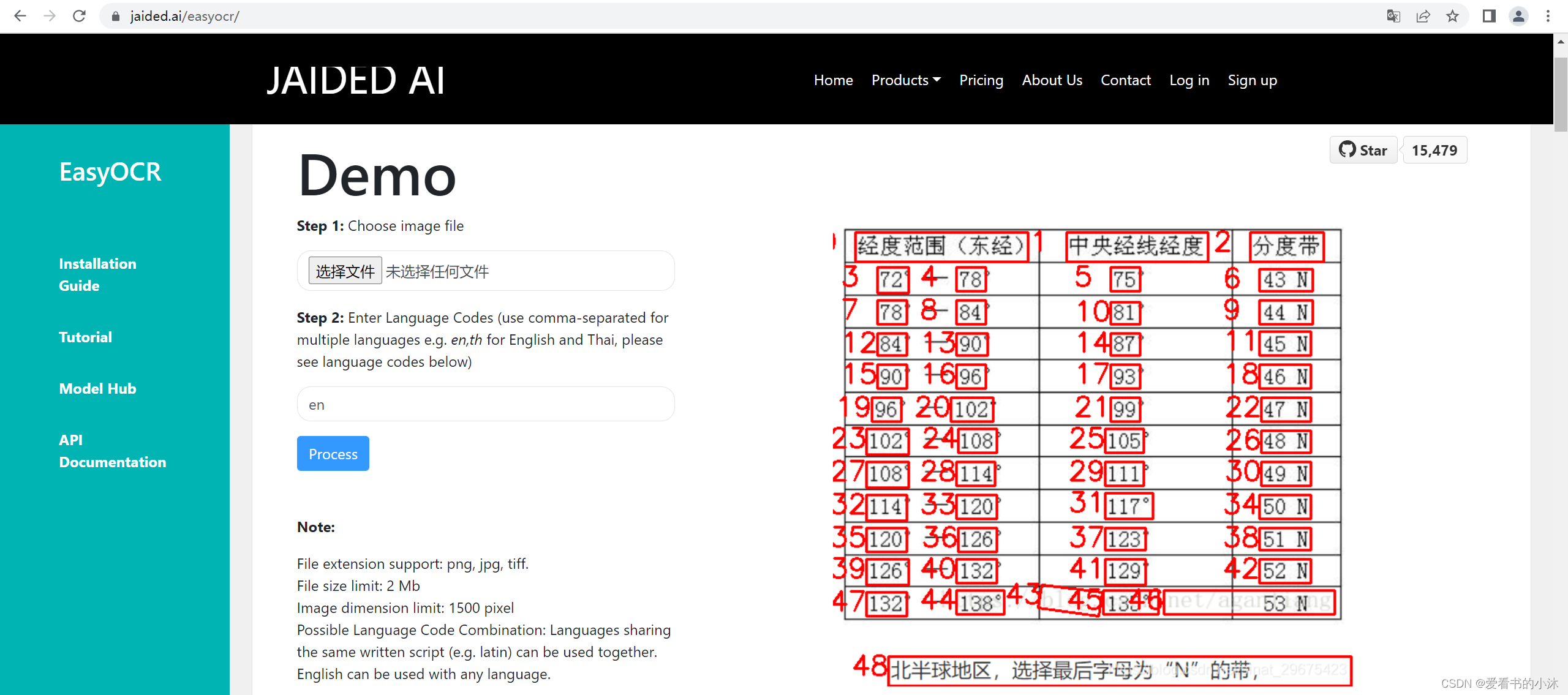

2.3 测试代码
import os
import easyocr
import cv2
from matplotlib import pyplot as plt
import numpy as np
IMAGE_PATH = 'test.jpg'
reader = easyocr.Reader(['en'])
result = reader.readtext(IMAGE_PATH,paragraph="False")
print(result)
import os
import easyocr
import cv2
reader = easyocr.Reader(['ch_sim'])
result = reader.readtext(r'd:\test_chs.png', detail = 0, paragraph=True)
print(result)
3、PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR
支持多语言识别,目前能够支持 80 多种语言;
除了能对中文、英语、数字识别之外,还能应对字体倾斜、文本中含有小数点字符等复杂情况
提供有丰富的 OCR 领域相关工具供我们使用,方便我们制作自己的数据集、用于训练。
PaddleOCR 需在 PaddlePaddle2.0 下才可以正常运行,开始之前请确保 PaddlePaddle2.0 已经安装。
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
git clone https://github.com/PaddlePaddle/PaddleOCR
cd PaddleOCR
pip3 install -r requirements.txt
- 使用 gpu,识别单张图片
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
- 使用 gpu ,识别多张图片
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
- 不使用gpu,识别单张图片
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False

结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!
