文章阅读总结:OpenAI-Codex
https://openai.com/blog/openai-codex/ :Codex工作是一个标准的应用型文章,将训练好的GPT3应用于一个实际的工作之中,在网络结构上基本没有创新,主要工作难点在于收集数据、微调模型,但是其关注的问题非常大,涉及到代码书写这个敏感问题。
1. Abstract 关键点
- CodeX是基于GPT语言模型进行微调得到的一个专门用于代码生成/文档生成的模型
- 为了测试模型的精度,OpenAI制作了一个评估数据集
HumanEval - 使用原始的GPT-3进行写代码,其精度基本上为0%,进行
微调之后精度可以达到28.8% - 进行100次随机代码生成,至少有一个代码是正确的概率达到了70.2%
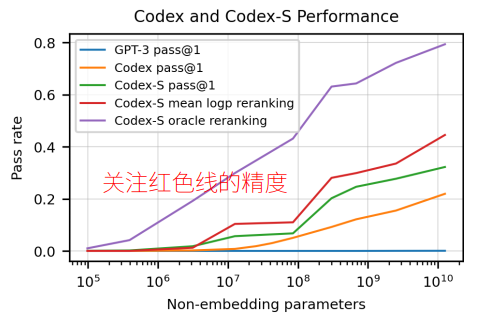
100次随机代码生成至少又一个是正确额的概率对我们实际工作意义不大,所以我们更多地关注红色线条表示的一个对数平均排序得到的准确率。这里说明了随着模型参数的增加,代码生成的精度增加,而且有一定的线性趋势。
2. 代码评估框架及其中的重点

-
对于传统的语言模型问题,我们可以使用BLUE score来进行模糊匹配评估,只要预测结果和真实结果的子序列的相似度够高,我们的BLUE socre就非常大;但是对于代码而言子序列相似度高不代表代码可以运行,所以这里提出了一种新的评估方法
pass@k- 其原理很简单,对于每个任务随机生成n种结果,其中有c种结果是正确的(即可以通过单元测试),从中随机抽取k种结果,如果一个正确结果都没有用
(
k
n
−
c
)
(_k^{n-c} )
(kn−c)表示,其概率用(
k
n
−
c
)
(
k
n
)
\frac{(_k^{n-c} )}{(_k^n)}
(kn)(kn−c)表示,我们需要至少有一个正确结果的概率,即用1减去即可。 - 为了数值的稳定(计算的时候是累乘,容易超过数值精度位数),所以可以用简单的形式表示,即
1
−
(
1
−
p
^
)
k
1 - (1-\hat{p})^k
1−(1−p^)k,上图右侧是使用python的简单实现!
- 其原理很简单,对于每个任务随机生成n种结果,其中有c种结果是正确的(即可以通过单元测试),从中随机抽取k种结果,如果一个正确结果都没有用
-
由于使用Github的代码进行训练,不可避免地会有很多的代码容易出现数据泄漏,所以这里测试使用人工手动书写的代码数据集
HumanEval -
直接测试各种代码存在很多的风险(例如数据泄漏、不可中断循环、攻击行为等),所以对代码的正确性进行测试的时候在
沙盒环境种进行
3. 微调训练
- 首先,CodeX直接使用GPT3预训练模型进行测试发现基本没有效果
- 使用GPT3预训练模型,然后加上微调发现预训练对精度的提高没有明显的效果,但是会加快模型收敛
- 由于代码(特比是python)中使用了大量的不同长度的空格和换行等特殊字符,所以需要进行特别的处理(加入训练),这样可以大大减小模型第一和最后一一层的参数量
- 结果展示
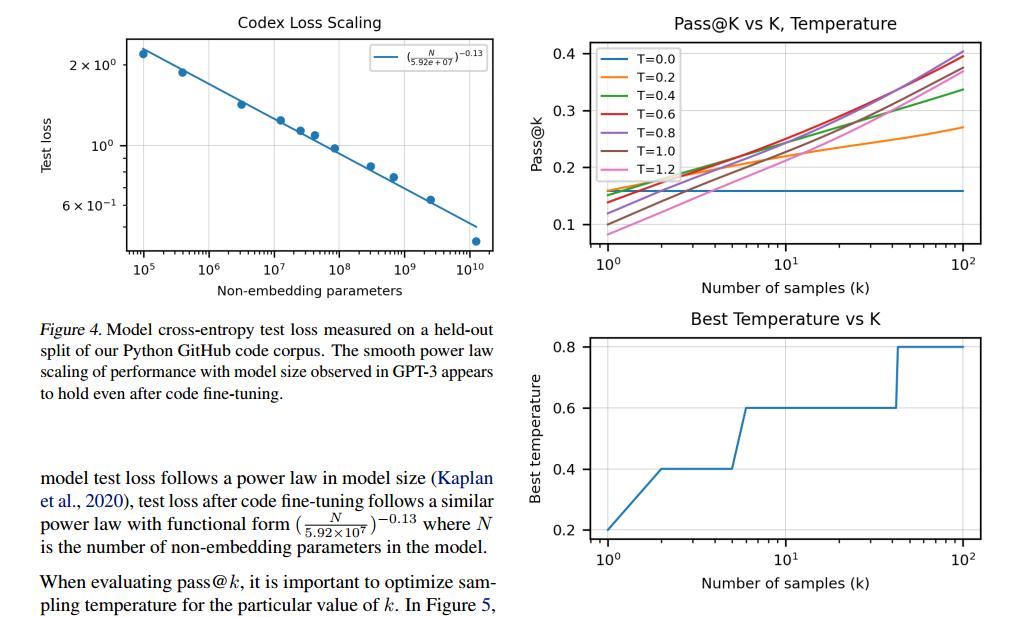
- 图4展示了随着参数量的增加,测试误差下降(但是误差线性下降,参数量指数增加)
- 图5展示的是由于
Pass@k指标种有一个超参数k,这个k和我们的温度参数有关(比如k=1的时候我们希望选择概率最大的值,但是随着k越多了,我们希望也可以选择一些概率大但并非最大的值)
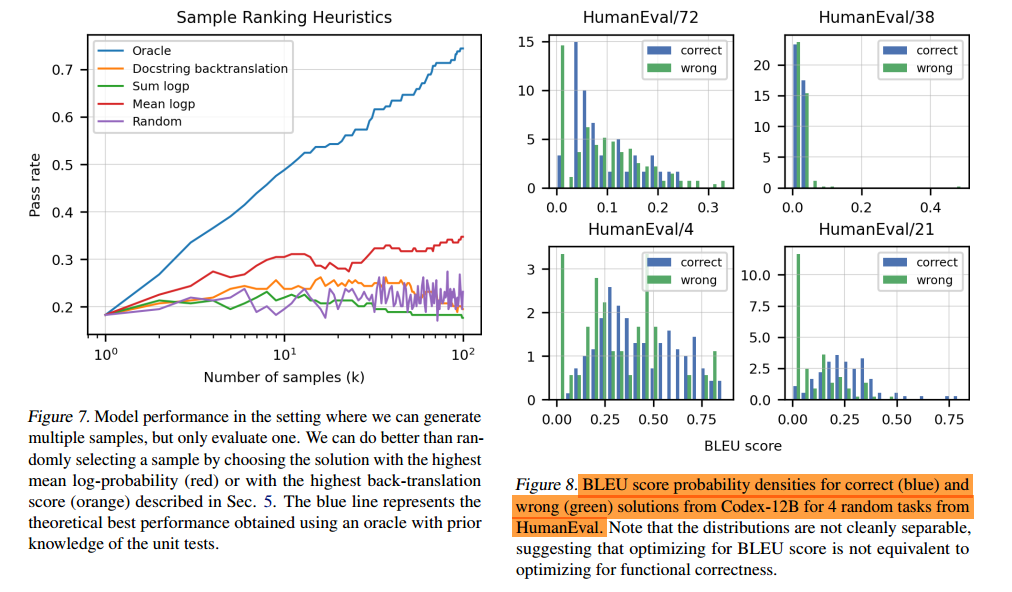
- 图7展示了不同刻度的精确度,我们仍然最关心的是红色曲线表示的对数平均精度,蓝色线条表示的是k次采样,有一次正确就正确的概率。红蓝两条线有一定的线性趋势,而其他几条线表示的没有明显的变化。
- 图8说明了使用BLEU socre进行评判,正确和错误的内容基本无法取分,也就是不能作为评判精度的指标!
4. 有监督微调
这里的监督是相对于前面的微调(传统的GPT3微调,给很多没有标签的数据进行专门化训练),OpenAI团队从竞赛级别的代码中收集了40000个代码数据进行专门的监督微调(即这里的代码是有标准答案的)

- 可以看到,实线表示的监督训练的精度变化曲线比没有监督训练的结果高了很多,效果非常明显
- 图10的橙色线表示的平均对数精度变化也非常明显!
5. 限制
- 样本数量太少(训练和测试的样本都太少了)
- 对于一个人而言,不同的注释只要描述的是同一个事情其书写的代码是相同的,但是对于网络而言只要注释变化其代码就发生了变化,其没有理解到注释的核心内容
- 注释的长度越长,给出的代码的精度越低,网络对于长注释/描述的效果不是很好
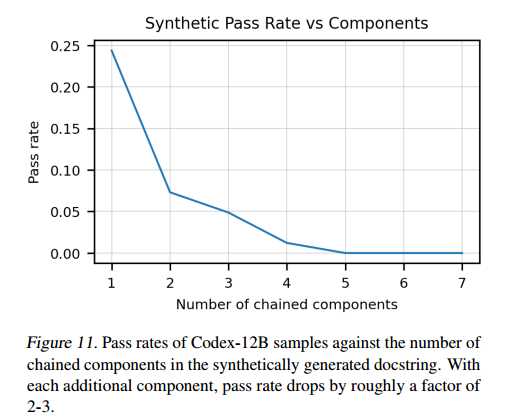
- 网络对数学语言描述这种比较精确的描述不能充分理解
