第一章——综述
一、什么是因特网
(一)若干角度看互联网
1、具体构成角度:
因特网由主机、通信链路、分组交换机组成。
2、服务角度:
因特网由分布式应用和为分布式应用提供服务的基础设施组成。
3、从网络角度看因特网:
网络由节点和边组成,因特网的节点和边是什么呢?
(为了”维持“因特网,在节点和边的基础上,需要增加协议)
节点:
①主机(端系统)
②分组交换机
边:
①接入网链路:位于接入网的链路
②网络核心链路:位于网络核心的链路
协议:
控制网络信息传输的规则
4、从网络的网络的角度看因特网:
ISP是网络,因特网是ISP构成的网络,所以因特网是网络的网络。
(二)若干概念解释
主机:运行网络应用的设备,也称为端系统。
分组交换机:由入链路接收数据,向出链路发送数据的设备。
通信链路:传输数据的链路。
链路的传输速率:以比特/秒度量。
分组交换机包括路由器和链路交换机。
其区别是路由器位于网络核心,而链路交换机位于接入网。
路径:数据经过的一系列通信链路和分组交换机称为路径。
因特网服务提供商(ISP):由一个或多个分组交换机和多条通信链路构成的网络。
内容提供者:提供互联网的内容的人,如Web站点。
网络服务提供商为端系统和内容提供者提供接入服务。
接入服务分为不同种类型,之后详细介绍。
因特网将端系统彼此互联,因为将端系统接入网络的ISP也必须互联构成网络,因而因特网也称为网络的网络。
底层ISP通过高层ISP互联。
因特网工程组(IETF)通过发布请求评论(RFC)指定互联网协议。
分布式应用:运行在端系统上的应用,涉及多台端系统之间的数据交换。
注意,分布式应用运行在端系统上,不运行在分组交换机上;分组交换机只用于数据交换。
运行在一个端系统上的应用怎么向另一个端系统上的应用传输数据?
端系统提供了应用程序接口(API),该API规定了/运行在一个端系统上的应用/请求/因特网基础设施/向运行在另一个端系统上的特定应用/交付数据的方式。
协议定义了两个或多个通信实体交换的报文的格式、次序以及(交换报文时)应采取的动作。
凡是因特网之间的通信,都必须受协议的制约。
不同的协议用于完成不同的任务。
二、网络边缘
概括:
网络可以按照逻辑位置分为以下3部分,并给出其功能。
网络边缘:运行应用
接入网:将网络边缘接入网络核心
网络核心:将节点连接起来交换数据
为什么运行网络应用的设备叫做"端系统"?
因为他们位于网络的边缘,以端点的身份位于网络中。
端系统一般包含桌面计算机、移动计算机、服务器等等。
端系统也称为主机,因为他们运行程序。
主机分为客户和服务器。
三、接入网
接入网:将端系统连接到边缘路由器的物理链路
边缘路由器:端系统到另一个端系统路径上经过的第一台路由器
(一)家庭接入
①数字用户线(DSL)
②电缆
③光纤到户(FTTH)
④拨号和卫星
(二)企业(和家庭)接入
一个较大范围的用户通常使用局域网(LAN)将端用户接入互联网
①以太网
②Wifi(无线局域网)
(三)广域无线接入
①3G、4G
②LTE
(四)物理媒体
需要跨越物理媒体传播电磁波或者光脉冲发送比特
物理媒体的分类:
导引型媒体:数据沿着固体媒体前行,如光缆、双绞铜线、同轴电缆。
非导引型媒体:数据在空气或外层空间传播,如无线局域网、卫星。
区分:一个看得见摸得着;一个看不见摸不着。
注意,这里说的是传输数据的媒体“看得见摸得着”,而不是数据本身……
四、网络核心
网络核心:由分组交换机和链路构成的网络
网络核心的功能是将节点连接起来并交换数据,接下来介绍交换数据的两种主要方式——分组交换和电路交换。
(一)分组交换
端系统彼此交换报文;
报文中包含数据或者用于执行控制功能的数据;
源将长报文划分成较小的数据块,称为分组;
每个分组通过通信链路和分组交换机传输;
分组以链路的最大传输速率通过通信链路;
传输速率单位一般为比特/秒,注意单位换算。
正确理解传输速率与传播速率(这对电路交换同样适用):
传输速率也称为发送速率,不懂为什么书上偏要叫做链路的传输速率。
链路的传输速率是指主机、分组交换机推送数据出去的速率;所谓的“以链路的最大传输速率”本质上讲是“以主机、分组交换机的最大推送速率”;与主机、分组交换机有关而与链路距离无关。
而传播速率是指数据在链路上传播的速率;与链路之间的距离有关而与主机、分组交换机无关。
之后的时延讨论中,我们会有更多的讨论……
1、存储转发机制
存储转发机制:
分组交换机在链路的输入端采用存储转发机制——输入链路完整接收分组数据后再开始向输出链路传输数据。
基于存储转发机制,我们考虑N条传输速率均为R比特/秒的链路,从源主机向目的地发送1个长度为L比特的分组,传输所需要的传输时延。
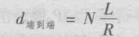
计算方式:
我们仍以发送速率的角度看待问题,N条链路,意味着有N-1台路由器,但是不要忘记源主机,因而总共有N台机器传输分组,每台机器的发送速率为R。在t=0时刻,源主机开始发送分组;在t=L/R时刻,第一台路由器完整接收分组并开始转发;在t=2L/R时刻,第二台路由器完整接受分组并开始转发……发现规律,即n台机器参与发送分组,传输时间总共为nL/R,即答案。
我们用一张图来理解这个题目,虽然有点大材小用,但是这对我们之后的理解很有帮助,之后的时延题目都可以用这样的模型解决。
模型构建:
图中的每一条实线都代表了数据的传输,以横轴表示数据传输的距离,以纵轴表示数据传输的时间。
(本题中不考虑传播时延,因而我们的距离会相对于时间产生突跃。
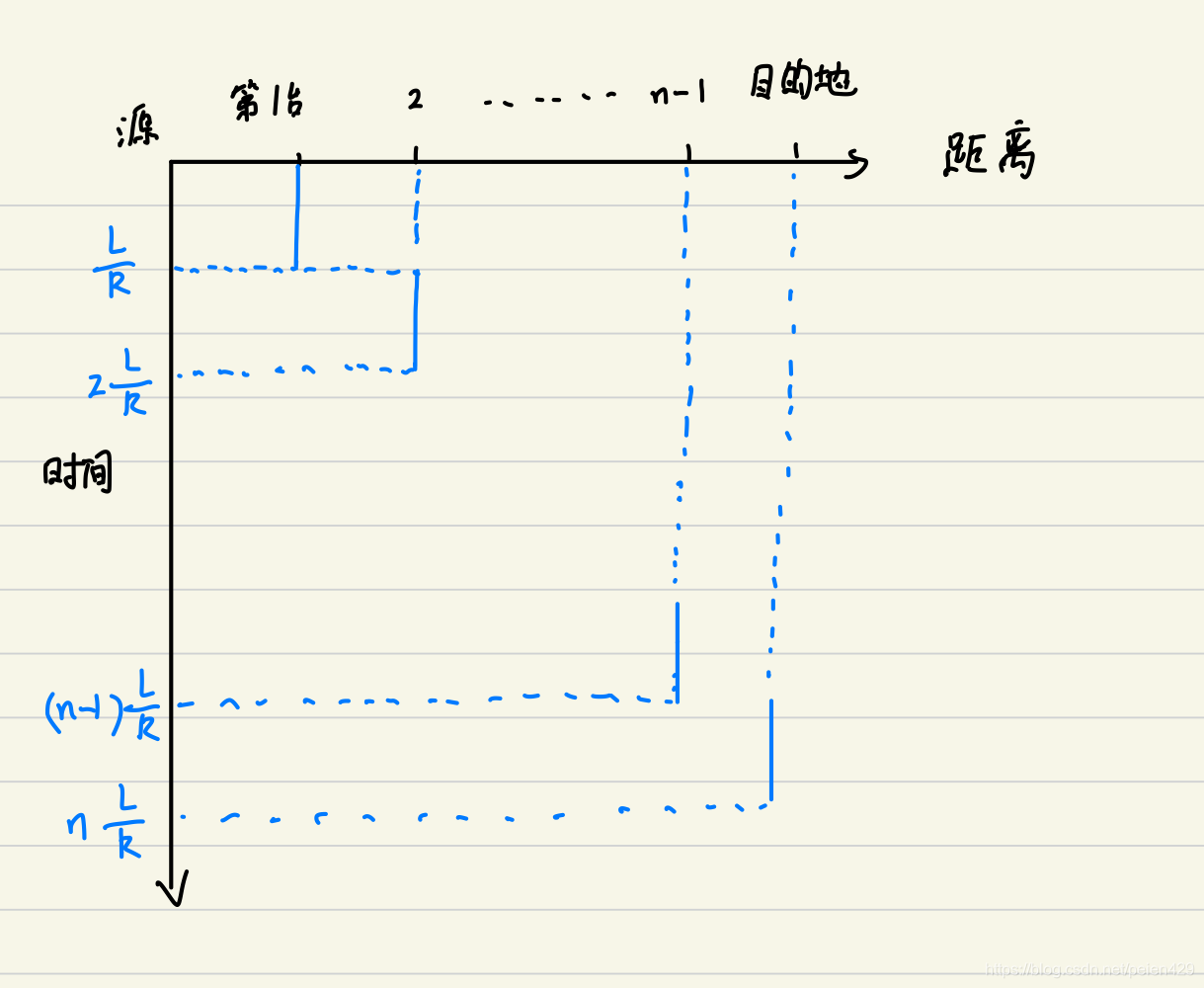
如果上述题目中不采用存储转发机制,所需传输时延为多少?
总传输时延永远为L/R,而与多少链路没有关系。因为第一台路由器接收数据就将其转发,其他路由器同理,在忽略其他时延的条件下,目的地接收的数据的时刻与源主机发送数据的时刻相同,因而只要源主机完整发送分组,目的地就会完整接收分组。
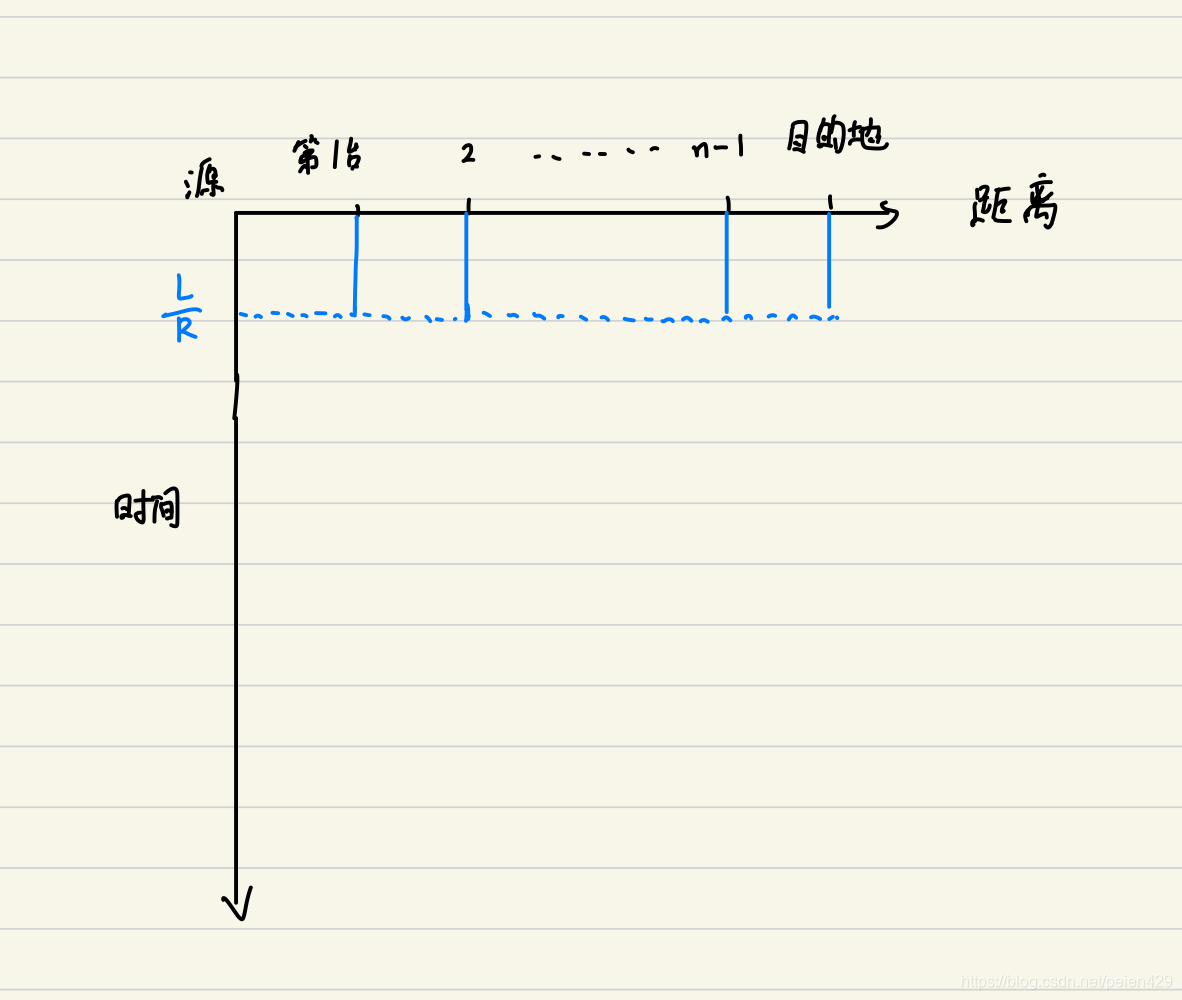
好的,我们来看一个稍微有点难度的问题:
仍然以存储转发机制,将上题目中的1个分组换成k个分组,所需的传输时延又是多少呢?
首先:源主机源源不断地发送分组,发送完某个分组后会立即发送之后的分组。
其次:多个分组的传输时间问题,转换为1个分组的传输时间问题 + 其余分组相对于第1个分组滞后时间的问题。
对于本题,第1个分组传输时间为NL/R,第2个分组相对于第1个分组滞后L/R,第3个分组相对于第2个分组滞后L/R……因为第k个分组相对于第1个分组滞后(k-1)L/R,所以总共的传输时延为NL/R+(k-1)L/R = (N+k-1)L/R。
2、排队时延和分组丢失
每个分组交换机与多条链路相连,对于每条链路,分组交换机有一个输出缓存(也成为输出队列),用于存放即将发往这条链路的分组,显然一个分组交换机有多个输出缓存。
输出缓存是有限的,当缓存被充满时,缓存中的分组或者新到的分组之一会被丢失,这就是分组丢失。
如果一条链路正在传输分组,那么输出缓存中的其他分组必须等待,等待传输的时延称为排队时延。
排队时延是变化的,取决于网络的拥塞程度。
为什么要设计输出缓存,因为一般而言,到达分组交换机的分组速率比离开分组交换机的分组速率更快。
3、转发表和路由选择协议
IP地址指明了数据的目的地,IP地址具有等级结构。
每台路由器都有转发表用于将IP地址映射为输出链路。
路由选择协议会计算源主机到目的地的最短路径,并根据最短路径自动设置路由器的转发表。
(二)电路交换
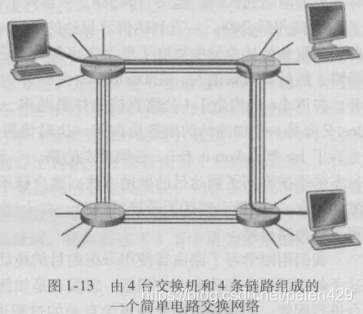
两个端系统通信期间,电路交换网络预留了该通信沿路径所需的资源,这些资源被该通信独享,后果是必须其他用户等待接入通信线路。
所谓的“预留”,实际上是指在两个端系统之间建立了一条连接,路径上的所有交换机都要维持这条连接。
电路交换网络为连接预留了恒定的传输速率(每条链路的一部分),并且能确保这个速率。
静默期:建立连接但是没有使用。
因为静默期,电路交换资源利用率低
电路(连接) 是独享的,但是链路是共享的;链路通过时分复用、频分复用被多条电路共享。
链路支持的连接最大数目是固定的,当链路的传输速率固定时,单个连接的传输速率固定不变,而与当前连接数目无关。
例如(在连接平均分配链路速率的条件下)链路速率1Mbps,链路最多支持4条连接,那么每条连接的速率都是250kbps。
需要注意的是,不管当前建立了1条连接还是4条连接,连接的速率都是250kbps,不会因为现有连接数目的变化而变化。
换言之,连接的速率只与链路的速率和链路支持的最大连接数目有关。
1、电路交换中的复用
频分复用(FDM)
链路的频谱由所有连接共享,每个连接专用一个频段。
时分复用(TDM)
时间被划为固定区间的帧(可以理解为周期),每帧划分为固定数量的时隙,每个连接专用一个时隙。
传输速率 = 帧速率 * 一个时隙传输的比特数

对于FDM,每个用户连续地得到部分带宽;
对于TDM,每个用户间断地得到全部带宽;
从这个角度上看,TDM和分组交换有一点点类似,都是间断地得到全部带宽。
2、电路交换和分组交换对比
分组交换无需建立连接,使用存储转发机制,端到端时延不可预测,不适用于实时通信,更容易实现,共享链路资源,按需分配,利用率高;
电路交换需要建立连接,不使用存储转发,端到端时延可预测,适用于实时通信,不容易实现,(单个连接)独享连接资源,预先分配,利用率低。
大趋势是电路交换—>分组交换。
关于端到端时延的对比:
电路交换有建立连接所需的时间,而没有存储转发机制带来的时延,因为电路交换的时延与链路数目无关。
(三)网络的网络
端系统通过ISP连入因特网,为实现端系统互联,ISP自身必须互联。
设想:每个ISP直接与其他所有ISP互联。
但是不可行,因为复杂度太高并且可扩展性差。
于是慢慢引出了之后的5种网络结构……
演化的规律:
①提供服务可以挣钱,请求服务需要花钱
②提供服务需要准备各种设施等等,需要成本
③有合作也有竞争
④体量太大的可以自己单干
1、网络结构1
用单一的全球承载ISP连接接入ISP
2、网络结构2
用多个全球承载ISP连接接入ISP;
两层结构——全球承载ISP互联,位于顶层;接入ISP位于底层。
3、网络结构3
多层次的网络结构
相比于网络结构2,增加了区域ISP。
多个底层ISP可以形成区域ISP,多个区域ISP可能形成更大的区域ISP
区域ISP可以连入顶层ISP或者更大的区域ISP
4、网络结构4
相比于3,增加了存在点、多宿、对等、因特网交换点。
存在点:高层的ISP,为低层ISP提供接入服务(所以存在点不包含接入ISP)
多宿:一个低层ISP可以接入多个高层ISP
对等:两个ISP层次相同时,互相接入,彼此不收费
因特网交换点:多个对等ISP的汇合之处
5、网络结构5
相比于4,在网络顶部增加了内容提供商网络,如谷歌数据中心
其特点是,提供商不用向顶层ISP付费;用户的网速更快。
五、分组交换中的时延、丢包和吞吐量
(一)单个节点的时延
节点总时延= 节点处理时延 + 排队时延 + 传输时延 + 传播时延
1、节点处理时延
①检查分组首部并决定将分组导向哪条链路
②检查比特级的错误
路由器的最大吞吐量:一台路由器能够转发分组的最大速率。
节点处理时延影响了路由器的最大吞吐量
2、排队时延
分组等待传输所需要的时延
详解见下
3、传输时延
将所有分组的比特推向链路所需要的时间。
传输时延取决于传输速率和比特数目
4、传播时延
分组在两地传播所需要的时间。
传播时延取决于两地距离
(二)排队时延和丢包
1、排队时延的表示
相同的路径,相同的分组仅排队时延可能不同,其它的时延必定相同。
那么我们用什么物理量来表示排队时延呢?
通常使用平均排队时延,排队时延方差,排队时延超过某特定值的概率来表征排队时延。
2、排队时延的影响因素
①分组到达该队列的速率
②链路的传输速率
③达到流量的性质(周期性到达还是突发式到达)
定义流量强度:
假设分组长度都为L比特,链路速率R bps,分组到达队列的平均速率a(单位分组/秒),排队队列无限大;那么流量强度为La/R,即每秒到达的比特与每秒离开的比特的比值。
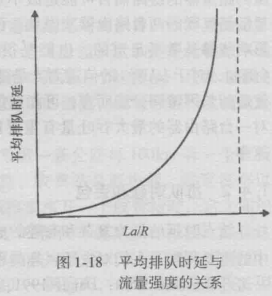
如果流量强度大于1,那么排队队列将趋近无穷,排队时延也将趋近无穷。
所以流量强度必须小于等于1,当然可以看到即使是接近1也不行。
考虑流量的性质:
假设初始排队队列为空,分组一个一个地周期性到达,每L/R秒到达一个分组,显然平均排队时延为0。
假设初始排队队列为空,分组突发式一组一组地周期性到达,每(L/R)N秒到达N个分组,求平均排队时延?
第一个分组排队时延为0,第二个分组的排队时延为L/R,以此类推……
t = (0+1+2+…+N-1) * (L/R) / N = [(N-1)/2] * (L/R)
所以,越是突发式到达分组,排队时延越长。
注意,实际中分组都是随机到达的。
3、丢包
实际中的排队队列是有限长的,因而随着流量强度趋近于1,排队时延不会趋近于无限大。
当分组到达一个满的队列时,路由器将会丢弃该分组,该分组将会丢失。
丢失包的数量随着流量强度的增加而增加。
丢失的包绝不会被传输到目的地。
为了数据的传输,丢失的包的数据,可能会形成新的包再次从端系统向端系统传输。
(三)端到端时延
假设有N条链路,忽略排队时延:
1个包的端到端时延 = N * 单个节点时延。
单个节点时延即(一)所说的3部分(去掉了排队时延)。
n个相同大小的包的端到端时延 = 1个包的端到端时延 + (n-1) * 单个节点的传输时延
具体见之前的题目。
(四)端到端吞吐量
1、定义
端到端吞吐量是指接收方的接收速率,包括瞬时吞吐量和平均吞吐量。
端到端吞吐量有时简称为吞吐量。
与路由器吞吐量对比,路由器吞吐量指路由器转发分组的最大速率。
2、影响因素
(端到端)吞吐量取决于数据流过链路的速率,根据木桶效应取最小。
情况一:当干扰流量很少(路径经过的网络核心的链路有很少的人用)或者网络核心链路速率很快时,吞吐量取决于接入网的速率,并取接入网中的最小链路速率。
情况二:当干扰流量多或者网络核心链路速率较慢时,吞吐量既取决于网络核心速率又取决于接入网速率,综合考虑取最小。
实际中,以情况一居多。
示例一:
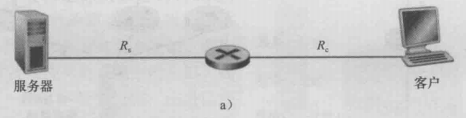
吞吐量 = min{Rs,Rc}
示例二:
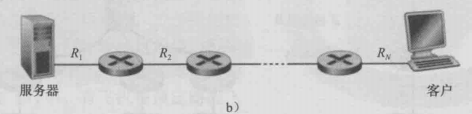
吞吐量 = min{R1,R2,R3,…,Rn}
示例三、四: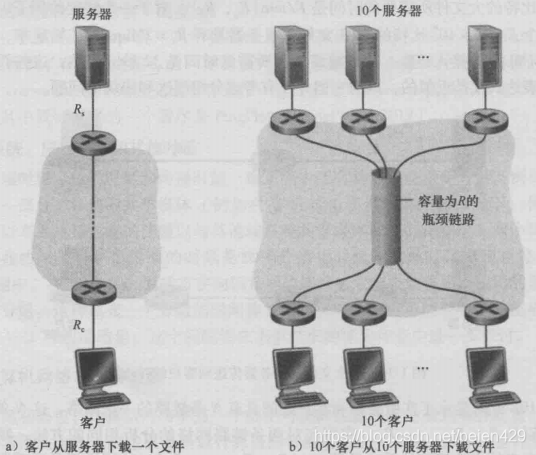
吞吐量a = min{Rs,Rc}
吞吐量b = R/10
我并不明白,为什么网络核心的速率要“均分”……
六、协议层次及服务模型
(一)层次化模型
1、含义
将复杂的网络功能分为若干层次,本层通过调用下层的服务以及执行本层的协议动作实现本层的功能,并向上层提供服务。
(功能比服务覆盖面更广)
一个层次可以由软件、硬件、或者两者的结合实现;
第n层协议的不同部分常常位于网络组件的各部分中;
网络组件的某一部分可能实现了若干层;
例如路由器实现了物理层、链路层、网络层;
链路交换机实现了物理层、链路层;
主机实现了5个层次;
将各层的所有协议称为协议栈;
因特网协议栈包含5个层次:应用层、运输层、网络层、链路层、物理层;
计算机网络分为7个层次(OSI模型):应用层、表示层、会话层、运输层、网络层、链路层、物理层;
2、优点
①概念化,结构清晰,便于描述网络之间的关系
②模块化,易于维护和系统升级(改变某层的实现时,其他层可以保持不变)
区分改变服务的实现和改变服务:
改变k层服务的实现,对k-1、k+1(乃至于任何层次)层没有影响;
改变k层服务,对k-1及其之下的层次没有影响,对k+1及之上的层次有影响,因为他们不能再调用k层的服务,所以它们必须重写代码以实现功能。
3、缺点
①某层可能冗余较低层的功能
②某层的功能可能需要仅在其他某层才出现的信息,这违背了层次分离的目标
4、因特网协议栈的5个层次
①应用层:实现网络应用,传输报文
如FTP、HTTP、DNS
②运输层:细化为进程到进程,传输报文段,可以选择将不可靠变为可靠
如TCP、UDP
③网络层:端到端,传输数据报(节点可以不相邻),不可靠
如IP
④链路层:相邻节点,传输帧,可靠或不可靠
如PPP
⑤物理层:相邻节点,传输比特
5、计算机网络的7个层次
表示层:使得通信的应用能够解释传输的数据的含义。如数据压缩、数据加密、数据描述(解决数据存储格式不同的问题)
对话层:提供了数据交换、检查和同步功能
其他层次的功能和上面相同
7个层次相当于把5个层次中的应用层细分为应用层、表示层、对话层;
5个层次中的应用层中的应用程序开发者决定一个服务是否重要,如果重要就在应用层实现表示层和对话层的功能;
5个层次——因特网/互联网协议栈
7个层次——计算机网络协议栈
(二)封装
每层的分组由两部分组成:
①首部字段:该层添加的字段
②有效负荷字段:上层的分组
分组从上层进入下层会增加字段;从下层进入上层会减少字段;
