第二周:自动驾驶 案例研究
第二周:自动驾驶 案例研究
本文是结构化机器学习的笔记。
2.0 重点
迁移学习、多任务学习(⚠️ 它不是用的SoftMax)、端到端
2.1 进行误差分析
- 误差分析:人工检查错误的结果
- 数一数有多少分错的例子,用来上限
- 性能上限
具体实现
以改善猫分类器为例子,假设我们目前有三个改善此分类器的想法:
- 改善其对于狗的识别能力
- 改善其对于其他猫科动物的识别能力
- 提升其对于模糊图片的识别能力
| 错误识别的图片编号 | 狗? | 其他猫科动物? | 模糊图片 | 备注 |
|---|---|---|---|---|
| 1 | X | - | - | 一张……狗的照片 |
| 2 | - | X | X | 雨天的一张老虎照片 |
| 3 | - | - | - | 不属于这三个问题 |
| 4 | - | - | - | - |
|
⋮ \vdots ⋮ |
- | - | - | - |
| n | - | - | - | - |
| 错误率: | - | - | - | - |
2.2 清除标注错误的数据
- 问题:如果发现Trainning Set数据里面有错误标注的样本,怎么办?
- Sol:
DL算法对于Trainning Set里面的随机错误比较鲁棒。
只要训练数据集合数量足够大
但是对于系统性错误(如,将白色的狗都标称了猫),则不太行
- 问题:如果发现Dev/Test Set数据里面有错误标注的样本,怎么办?
- Sol: Error Analysis中添加一列
| 错误识别的图片编号 | 狗? | 其他猫科动物? | 模糊图片 | 错误标注 | 备注 |
|---|---|---|---|---|---|
| 1 | X | - | - | - | 一张……狗的照片 |
| 2 | - | X | X | - | 雨天的一张老虎照片 |
| 3 | - | - | - | - | 不属于这三个问题 |
| 4 | - | - | - | X | - |
|
⋮ \vdots ⋮ |
- | - | - | X | - |
| n | - | - | - | - | - |
| % of total | 8% | 43% | 61% | 6% | - |
- 如果我们发现在Dev Set上的错误率为10%,则此时因为错误标注而引起的错误率为
10
%
∗
6
%
=
0.6
%
10\%*6\%=0.6\%
10%∗6%=0.6%,而因为其他原因导致的错误10
%
∗
94
%
=
9.4
%
10\%*94\%=9.4\%
10%∗94%=9.4%,因此此时最好还是把工作中心放在克服因为其他原因引起的错误。
其他的注意事项
如果决定需要更改一些错误的数据标签,则需要注意以下几点:
- 同时修改Dev和Test Set里面的错误标签。
- 对于分对的例子,也有可能是因为错误标签而蒙对的。
- Train集合中的数据可以不用修改,因为其数量太多,也因为DL算法比较鲁棒。我们只要要求Dev/Test来自于同一分布,并没有一定要求Train集合的数据和它们也同分布。
2.3 快速搭建你的第一个系统,并进行迭代
- Set up dev/test set and metric
- Build initial system quickly
- Use Bias / Variance analysis & Error analysis to prioritize next steps.
2.4 在不同的划分上进行训练并测试
目前我们Train和Dev/Test的数据分布不一样
猫咪识别例子:
-
数据来源:
- 来自网页 200,000
- 来自用户手机 10,000 (目标的分布)
-
想法一:
两者合并在一起,然后打乱,按照95%,2.5%,2.5%的分布分配数据- 这种想法的缺点为:在测试集合里面来自用户手机的图片比较少。因此此想法不推荐。
-
想法二:
Train里面有200,000网页数据,5,000用户数据,
Dev/Test 里面各2,500用户数据。
语音识别导航例子:
- Training数据来源:
- Purchased datas
- Smart speaker
- 500,000
- Dev / Test:
- Speech Activated Rearview mirror: 20,000数据
- 此数据集里面有很多地名信息,是我们的目的
所以真是训练集合为:500,000+10,000
Dev/Test 5,000/5,000
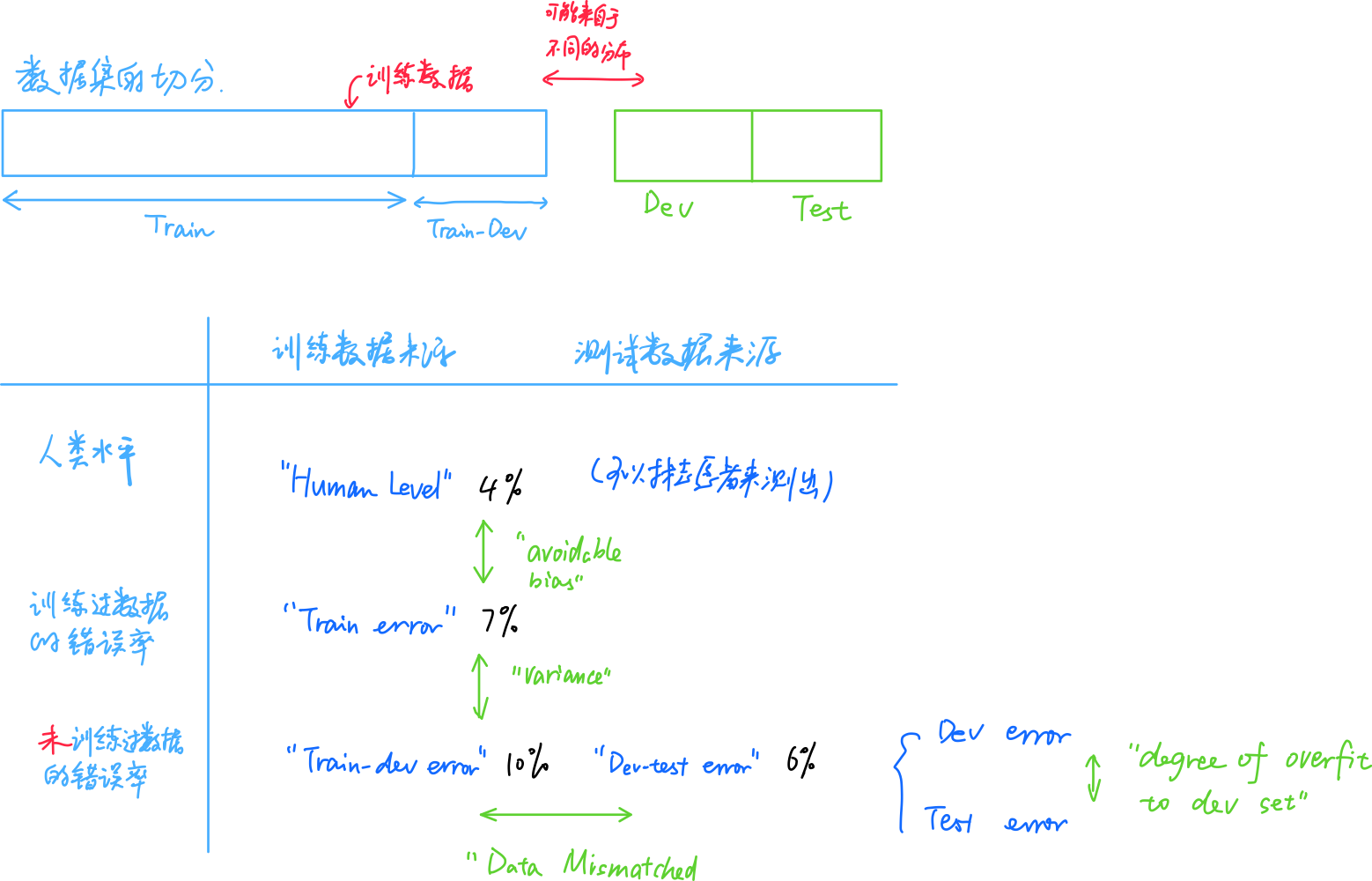
2.5 不匹配数据划分的偏差和方差
猫咪识别例子:
假设人的错误率为0%。
Train Error:1%
Dev Error:10%
Variance较大的两个原因:算法没看过Dev数据;数据分布不一样。
-
Training-dev Set:
从Train Set里面划分出一部分,作为Training-dev Set。它和Train Set有同样的分布。
此时如果 -
1)
Train Error:1%
Train-Dev Error:9%
Dev Error:10%
则此时我们确定有一个Variance的问题,因为Training-dev Set和Train Set有同样的分布。 -
2)
Train Error:1%
Train-Dev Error:1.5%
Dev Error:10%
则此时我们确定有一个Data mismatch(数据不匹配)的问题。 -
3)
Human Error 0%
Train Error:10%
Train-Dev Error:11%
Dev Error:20%
这里有Bias和DataMismatch的问题
具体计算方式
关键的几个概念:
Avoidable Bias,Variance,Data Mismatch,Degree of overfit to dev set
没有有效解决Data Mismatch的系统方法,但是我们有一些可能的解决办法。
2.6 解决数据不匹配的问题
- 观察Dev Set和Trainning Set的不同
- 想办法搜集一些数据,让训练数据与Dev/test Set更加类似。
- 例子:
在汽车语音导航的例子里面,对比测试数据我们的训练数据可能缺少背景汽车噪音,可能缺少一些导航词汇(如地名)。
人工合成数据
注意!我们人工生成的数据可能只是原来样本中的一些子集,有很大的过拟合的风险。
-
我们可以快速制造一些贴近于应用场景的数据。
-
在汽车语音导航的例子中,我们可以在原来的声音基础上叠加上汽车的噪声,但是有过拟合的风险。这种风险在图像领域更容易理解。
-
如果我们想通过渲染生成汽车图片从而构建一个汽车识别的网络,我们的确可以生成数据,例如100辆车。但是这100辆车的图片与现实生活中成千上万的车的集合相差甚远,因此具有过拟合的风险。在混上噪音的例子中,我们的模型可能对我们录好的噪音过拟合,所以将一小段噪音重复若干次可能不是一个好的想法。
2.7 迁移学习(Transfer Learning)
讲了预训练(Pre-Training)和微调(Fine Tuning)。
一个用来识别猫的网络可能可以迁移来看Xray的图像。
步骤:
-
把最后的一层给去掉,换成一个新的。(如果数据少,只改最后几层。如果数据比较多可以多改层。)当然也可以多加几层。
-
随机初始化权重
-
预训练(Pre-Training):
如果数据比较多的话,我们可以在原来的模型的权重的基础上训练。 -
微调(Fine Tuning):
用后来的数据来更新原来模型权重的过程
为什么能这么做?
因为在之前的网络中,网络可能已经学会看图像的一些基本特征。
什么时候这么做?
当我们在之前的问题有很多数据,但是现在的问题数据比较少。
如一个语音识别模型(输出听写文本),可能有100000h的数据,但是wakeword/trigger word的数据比较少,可能只有1h。
但如果是相反的情况,则不一定会有增益。
⚠️ 总结
是否能对任务B进行迁移学习?
- 任务A和任务B有同样的输入,如图像、语音。
- 任务A的数据量比任务B的数据量更多。
- 任务A中学习的一些基本结构对于任务B有用。(如,视觉领域就是图片中的一些基本特征的提取)
2.8 ⚠️多任务学习(MultiTasking Learning)
同时开始学习,让单个网络学习多件任务。其实就是多标签。
实际上没有Transfer Learning常用
- 例子:
自动驾驶中,我们需要识别行人、汽车、标示牌、信号灯等等。
此时第i个样本的输出可能有如下的形式:
y
(
i
)
=
[
行
人
汽
车
标
示
牌
信
号
灯
]
=
[
0
1
1
0
]
y^{(i)}=\begin{bmatrix} 行人 \\ 汽车 \\ 标示牌 \\ 信号灯 \end{bmatrix}=\begin{bmatrix} 0 \\ 1 \\ 1 \\ 0 \end{bmatrix}
y(i)=⎣⎢⎢⎡行人汽车标示牌信号灯⎦⎥⎥⎤=⎣⎢⎢⎡0110⎦⎥⎥⎤
Y
=
[
y
(
1
)
,
.
.
.
,
y
(
m
)
]
∈
R
4
×
m
Y=[y^{(1)},...,y^{(m)}] \in \mathbb{R}_{4\times m}
Y=[y(1),...,y(m)]∈R4×m
损失函数
-
C
=
C
l
a
s
s
e
s
=
4
C=Classes=4
C=Classes=4:多分类任务的种类数目
J
=
1
m
∑
i
=
1
m
[
∑
j
=
1
C
L
(
y
^
j
(
i
)
,
y
j
(
i
)
)
]
J=\frac{1}{m}\sum_{i=1}^m[\sum_{j=1}^C L(\hat{y}^{(i)}_j,y_j^{(i)})]
J=m1i=1∑m[j=1∑CL(y^j(i),yj(i))]
其中
L
(
y
^
j
(
i
)
,
y
j
(
i
)
)
=
−
[
y
j
(
i
)
l
o
g
(
y
j
^
(
i
)
)
+
(
1
−
y
j
(
i
)
)
l
o
g
(
1
−
y
j
^
(
i
)
)
]
L(\hat{y}^{(i)}_j,y_j^{(i)})=-[y_j^{(i)}log(\hat{y_j}^{(i)})+(1-y_j^{(i)})log(1-\hat{y_j}^{(i)})]
L(y^j(i),yj(i))=−[yj(i)log(yj^(i))+(1−yj(i))log(1−yj^(i))]相当于对于每一个特征j计算其交叉熵损失。
所以第i个样本的损失函数为
L
(
y
^
(
i
)
,
y
(
i
)
)
=
∑
j
=
1
C
L
(
y
^
j
(
i
)
,
y
j
(
i
)
)
=
−
∑
j
=
1
C
[
y
j
(
i
)
l
o
g
(
y
j
^
(
i
)
)
+
(
1
−
y
j
(
i
)
)
l
o
g
(
1
−
y
j
^
(
i
)
)
]
L(\hat{y}^{(i)},y^{(i)})=\sum_{j=1}^{C}L(\hat{y}^{(i)}_j,y_j^{(i)})=-\sum_{j=1}^{C}[y_j^{(i)}log(\hat{y_j}^{(i)})+(1-y_j^{(i)})log(1-\hat{y_j}^{(i)})]
L(y^(i),y(i))=j=1∑CL(y^j(i),yj(i))=−j=1∑C[yj(i)log(yj^(i))+(1−yj(i))log(1−yj^(i))]
Rq:
- 及时有一些图像只有部分标签,我们也可以进行多任务学习:
对于y
(
i
)
=
[
0
1
?
0
]
y^{(i)}=\begin{bmatrix} 0 \\ 1 \\ ? \\ 0 \end{bmatrix}
y(i)=⎣⎢⎢⎡01?0⎦⎥⎥⎤这种样本中的问号在求和中就直接忽略就可以了。
⚠️⚠️与SoftMax的区别
- SoftMax中的
y
(
i
)
y^{(i)}
y(i)列向量里面只有一个1,而多任务学习中的y
(
i
)
y^{(i)}
y(i)可以有多个1 - SoftMax中的损失函数为
L
(
y
^
(
i
)
,
y
(
i
)
)
=
−
∑
j
=
1
C
y
j
(
i
)
l
o
g
(
y
^
j
(
i
)
)
L(\hat{y}^{(i)},y^{(i)})=-\sum_{j=1}^C y_j^{(i)}log(\hat{y}_j^{(i)})
L(y^(i),y(i))=−j=1∑Cyj(i)log(y^j(i))
而多任务学习的损失函数是对每个输出j于交叉熵损失函数:
L
(
y
^
(
i
)
,
y
(
i
)
)
=
∑
j
=
1
C
L
(
y
^
j
(
i
)
,
y
j
(
i
)
)
=
−
∑
j
=
1
C
[
y
j
(
i
)
l
o
g
(
y
j
^
(
i
)
)
+
(
1
−
y
j
(
i
)
)
l
o
g
(
1
−
y
j
^
(
i
)
)
]
L(\hat{y}^{(i)},y^{(i)})=\sum_{j=1}^{C}L(\hat{y}^{(i)}_j,y_j^{(i)})=-\sum_{j=1}^{C}[y_j^{(i)}log(\hat{y_j}^{(i)})+(1-y_j^{(i)})log(1-\hat{y_j}^{(i)})]
L(y^(i),y(i))=j=1∑CL(y^j(i),yj(i))=−j=1∑C[yj(i)log(yj^(i))+(1−yj(i))log(1−yj^(i))]
什么时候可以用多任务学习?
- 可以共享一些低维的特征
- 每个任务的数据量相近(因为多标签的样本数据比较少,而鉴于它们共享一些特征,所以其他数据可以帮助提升性能。)
- 可以训练一个比单一任务还更大的网络来做这些任务
2.9 什么是端到端学习(end-to-end DL)
例子:(流水线(pipe line)VS端到端(end-to-end))
- 语音识别系统
- 传统的流水线(pipe line)模式:
人工设置一些“环节”
- 端到端(end-to-end)模式:
当数据量比较大的时候端到端学习比较好用,否则流水线更适合。
例子:(门禁)
- 人脸识别的一般步骤:
- 框出人脸
- 对框出的人脸进行人脸识别
研究表明分成两步效果更好,而非直接从照片识别人的身份,因为:
- 两个任务都有很多数据,而直接从照片识别人的身份的数据不够多,所以端到端学习不太好用。
2.10 是否要使用端到端深度学习
端到端学习的利与弊:
- 好处:
- 从数据中得到规律,而非认为强制解决问题的方法
- 不需要手动设置很多的步骤
- 坏处:
- 需要很多的数据
- 排除了很多手动设计的组件。
如何判断是否使用端到端的深度学习?
判断是否有足够数据来构建x到y的映射。若足够,则可以。
第二周测试中的重点
- 只要合成的雾对人眼来说是真实的,你就可以确信合成的数据和真实的雾天图像差不多,因为人类的视觉对于你正在解决的问题是非常准确的。
- 关于先解决哪一部分误差
