浙大学长分享,第二次打数据挖掘赛,雪浪算力开发者大赛总结
Datawhale干货
作者:滕飞,浙江大学,Datawhale成员
作者信息:滕飞,浙江大学20届本、23届硕,现为浙江大学智能系统安全实验室(USSLAB)成员,毕业后将于蚂蚁金服工作。
主要研究方向:数据安全、时序分类与预测、数据挖掘相关,本次分享的赛题为雪浪云主办的算法赛——阀体装配线产品合格检测挑战赛,这也是笔者第二次打数据挖掘相关比赛,经验尚有很多不足。
1. 赛题简介
本次阀体装配线产品合格检测挑战赛是一种经典的时序数据二分类/异常检测算法题,大致背景如下:
阀体装配线对于每个产品的测试过程数据以序列形式存储,最终通过检测台统一输出检测结果,包含了 13 个检测项,每个检测项中有多个传感器。参赛者需要根据历史检测结果,利用大数据分析、机器学习等方法,提取特征,建立合适的分类模型,对数据集中所有的产品样本进行分类,最终判定结果 0 为合格,1 为不合格,尤其是希望可以分类出机检合格但后续发现异常的不合格件,提高企业机检准确率,减少企业运营成本。
最终评分标准为F1 Score以及使用的原始传感器数据数量,越高的F1排名越高,同分情况下使用的原始数据越少,排名越高。
赛事地址:https://www.xuelangyun.com/#/cdc
2. 基本思路
下面介绍一下我对于这个赛题的思路:
思路1 — 关于对异常的理解
面向异常样本非常少,正常样本非常多的显著分布有偏数据集,会出现异常样本对异常的表征不足、异常类型覆盖面小、模型难学习、过拟合等问题,故希望通过更多对异常本身的刻画,而非令有监督模型学习到具体某个特征的具体数值,来提升表现。故考虑通过无监督模型来表现异常的程度。而赛题中提及的“尤其是希望可以分类出机检合格但后续发现异常的不合格件,提高企业机检准确率,减少企业运营成本。”,也让我更加坚定地尝试捕获异常,而非追求更精确的分类本身。
具体action:使用LOF、孤立森林对所有样本进行分布上异常的检测,但由于分布异常未必等同于业务异常,故将异常的分析结果汇入特征集合,还是使用有监督模型进行进一步的学习。
进一步解释:如果正常样本的分布是在一个球体空间内,这个球体外的一些零散样本可以被视为异常,异常样本可能自己有一个簇,也可能极为零散,但由于本赛题的异常其实是业务异常,受限于检测台的判定结果,可能被标记为NG的样本只是空间中的一个方向,其他的异常可能被标记为OK,所以还是得使用有监督来将最终判定拉齐到已经标记的空间。
思路2 — 特征表征与筛选
什么样的特征该被优先选择?有较强区分力的、正负样本有明显分布差异的。
思路3 — 缺失处理
这次比赛的数据缺失是由于检测台检测到异常后,提前终止检测引发的数据丢失,但并不能直接利用缺失来判定产品是否合格,合理的处理方法有助于保持与线上测试数据集相近的分布,提升表现。
思路4 — 特征衍生
由于一个检测台内有多个时序同步的sensor,sensor之间可能有关联,比如A传感器序列是一个方波,B也是,它们对齐了才能称之为正常,不对齐则为异常,这样的相关性可能需要特征或算法层面进行捕捉。但由于时间问题最后放弃深究。
思路5 — 模型融合
由于比赛最终使用公榜作为最终评分依据,这个bug可导致,类似于bagging思路,只需要获得多个公榜上评分高且有方差的弱模型,通过后续的major voting,理应提分或者维持分数不变,也就是只要多个存在方差的方案组合即可上分。
3. 数据探索性分析 EDA
首先对原始数据的时序特性进行检查:
-
一个检测台内多个sensor是等长的,或许是同步的,有相关意义。
-
同一个sensor中,不同样本的时长大多一样,少数不一样,但不宜作为分类依据。接着,由于赛题要求筛选原始传感器序列,从401个传感器中选出不超过50个,故检查序列相似性与大致分布情况:
-
部分传感器数据形式非常相似,信息有重叠,可基于相关性进行筛选去除。
-
内外传感器对齐后,发现同名内外传感器序列几乎无差别,可以丢掉其中一个。若有差别,可以对序列做差,然后提取特征,以表征产品异常。
-
仅有少量序列存在聚类中心,大多数数据不宜直接使用原始序列进行异常表征。
-
若有聚类中心:直接计算原始序列相似度:找到每个sensor的聚类中心,然后对比其他序列相较于该中心的距离,若如果有多个聚类中心也可以采用类似的操作。预测时,将新的样本放入聚类模型(如dbscan),可计算距离和分类结果作为特征。
-
若无聚类中心,或异常足够简单,可直接用Lof这种无监督的异常检测模型对整体提取特征后的数据集做异常检测,这样也容易处理一些序列长度不一致的问题,计算复杂度也更低。
-
-
异常类型大多比较简单,提取一些简单的特征理应可以表征。以下为几类典型的序列情况:
情形1:
部分sensor序列是可以聚类的,直接用序列本身作为分类基础即可,距离聚类中心的距离是一个很好的指标,也可以提取对应特征。比如下图中提取均值、方差,可以很显著地分开脱离正常区间的异常样本。
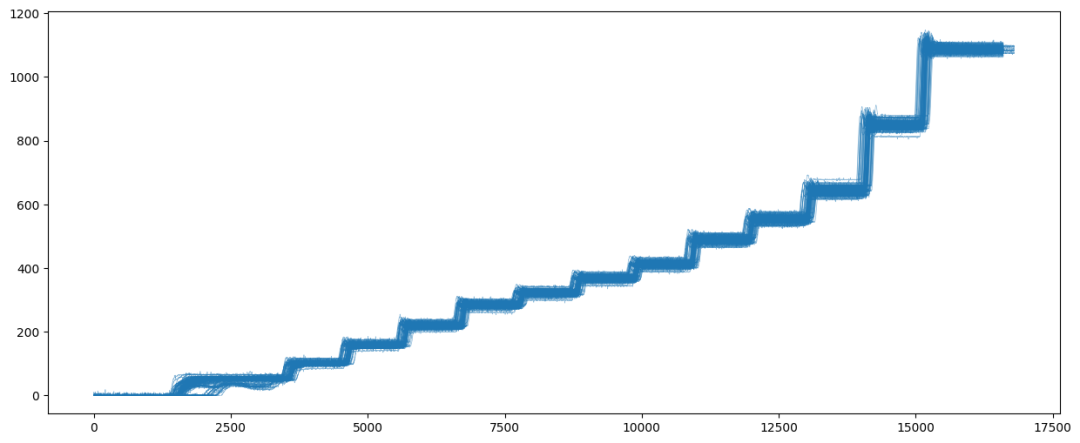
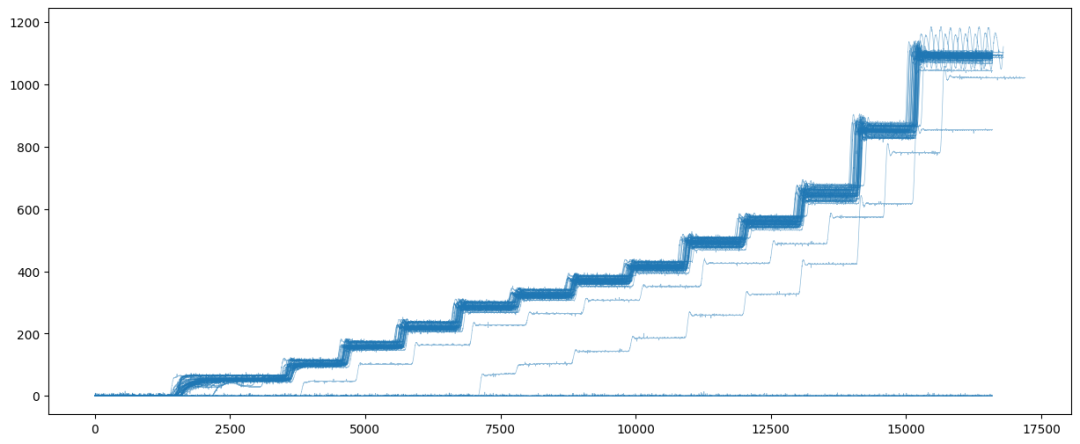
情形2:
存在一些大致形式相似,有特点的序列,但是宏观上难聚类。可能需要提取时域、频域特征等。不过最终发现频域意义一般,可以不提取。下面的三张图分别是局部放大(类似正弦波)、正常样本分布图、异常样本分布图,大致可以看出,明显剧烈抖动或贴近0的几条序列是异常的,通过均值、方差足以表征。
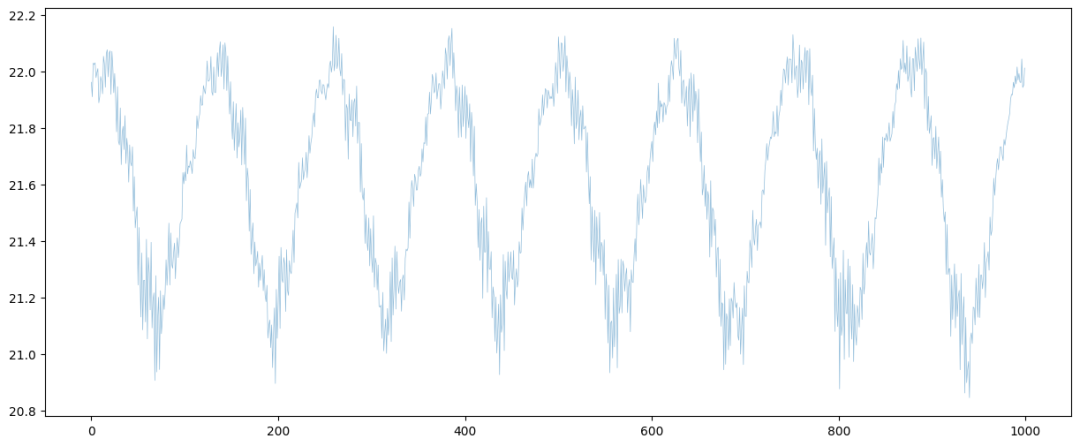
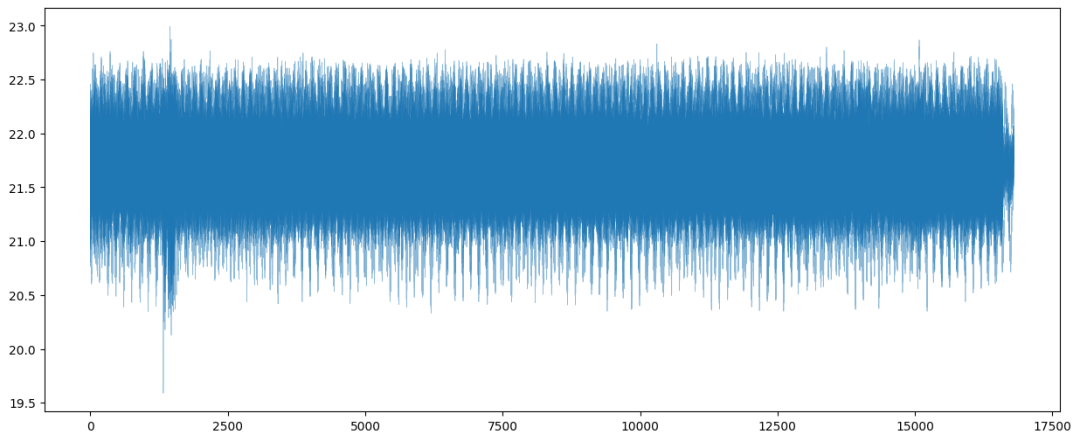
情形3:
正常样本为一条普通的抖动直线或者斜线,异常样本明显偏移或为0附近的线,而大多数传感器序列都属于这样的情形,这也导致了简单的mean、max、std特征就可以奏效,顺利进入前排。
情形4:
考虑到不同sensor之间可能存在联系,时序有相关性等特点,值得进一步探究,由于时间问题尚未尝试。
此外,EDA中还需要进一步对衍生特征进行分析等,由于时间问题尚未尝试。
4. 原始传感器序列特征提取
但由于赛题数据本身的异常较为明显,事实上仅提取均值作为特征也能起到很好的分类效果
主要为时域、频域的特征制作,未于此处直接制作与异常关联的强特征。具体代码示意如下:
# 时域
data_len = len(sample_onesensor_array) # 序列长度
max_v = sample_onesensor_array.max()
min_v = sample_onesensor_array.min()
skew_v = pd.Series(sample_onesensor_array.reshape(-1)).skew() # 偏度
kurt_v = pd.Series(sample_onesensor_array.reshape(-1)).kurt() # 峰度
rms = np.sqrt((np.mean(sample_onesensor_array**2))) # RMS均方根
xr = (np.mean(np.abs(sample_onesensor_array)))**2 # 方根幅值
mean_v = sample_onesensor_array.mean()
std_v = sample_onesensor_array.std()
pk_1_v = sample_onesensor_array.max() - sample_onesensor_array.min() # 峰峰值
pk_2_v = (sample_onesensor_array.max() - sample_onesensor_array.min()) / (abs(sample_onesensor_array.mean()) + 0.01)
pk_max = max(max_v, -min_v)
quan_25_v = np.quantile(sample_onesensor_array, 0.25) # 分位数
quan_50_v = np.quantile(sample_onesensor_array, 0.50)
quan_75_v = np.quantile(sample_onesensor_array, 0.75)
cf = (pk_max / rms) if rms != 0 else 0 # 峰值因子
pf = pk_max/xr if xr != 0 else 0 # 脉冲因子
non_zero_ratio = (np.count_nonzero(sample_onesensor_array)) / data_len # 数值非0数量
# 数字出现次数最高的3个,以及比例
counter = collections.Counter(list(sample_onesensor_array.reshape(-1)))
most_common = counter.most_common(3)
nums_count = len(most_common)
top_1_num = most_common[0][0]
top_2_num = most_common[1][0] if nums_count >= 2 else -1
top_3_num = most_common[2][0] if nums_count >= 3 else -1
top_1_ratio = (most_common[0][1] / data_len)
top_2_ratio = (most_common[1][1] / data_len) if nums_count >= 2 else 0
top_3_ratio = (most_common[2][1] / data_len) if nums_count >= 3 else 0
# 防止序列出现平移异常,取中段数据算均值
if data_len <= 10:
middle_mean = sample_onesensor_array.mean()
else:
middle_mean = sample_onesensor_array[int(0.4 * data_len): int(0.6 * data_len)].mean()
# 频域
window_size = min(len(sample_onesensor_array), 1000) # 裁剪,减少运算时间,可以不裁剪
L = window_size
PL = abs(np.fft.fft(sample_onesensor_array[:window_size] / L))[: int(L // 2)]
if L < 2: PL = np.array([0])
PL[0] = 0
Fs = 100 # 采样率,这里是随便设置的
f = np.fft.fftfreq(L, 1 / Fs)[: int(L / 2)]
if L < 2: f = np.array([0])
x = f
y = PL
K = len(y)
f_12 = np.mean(y)
f_13 = np.var(y)
f_14 = (np.sum((y - f_12)**3))/(K * ((np.sqrt(f_13))**3))
f_15 = (np.sum((y - f_12)**4))/(K * ((f_13)**2))
f_16 = (np.sum(x * y))/(np.sum(y))
f_17 = np.sqrt((np.mean(((x- f_16)**2)*(y))))
f_18 = np.sqrt((np.sum((x**2)*y))/(np.sum(y)))
f_19 = np.sqrt((np.sum((x**4)*y))/(np.sum((x**2)*y)))
f_20 = (np.sum((x**2)*y))/(np.sqrt((np.sum(y))*(np.sum((x**4)*y))))
f_21 = f_17 / f_16
f_22 = (np.sum(((x - f_16)**3)*y))/(K * (f_17**3))
f_23 = (np.sum(((x - f_16)**4)*y))/(K * (f_17**4))5. 缺失处理
由于异常样本存在较多缺失,且比赛方为了避免参赛者直接利用缺失进行分类,线上数据集进行了正常样本的缺失处理,故线下也需要对数据进行修正与处理。
-
假设特征分布为正态分布,通过记录正常样本的分布情况,使用均值方差进行异常样本的缺失进行插补,效果较差。
-
使用正常样本的特征集合,随机抽取特征数值对异常样本进行填补,效果较好。
-
对正常样本也进行缺失处理,模拟线上测试集处理方式,未尝试,据说效果好。
-
使用KNN来搜索距离缺失样本最近的样本,然后用于填补,几乎最大程度的还原。比如使用KNN 搜寻补齐缺失样本,基于全体OK+NG样本来补齐,找最近邻的3个样本再平均化处理,用于填充缺失,这样处理的优势在于还原精度高,对于模式复杂的情形有更好的填充效果,若随机填充,可能有逻辑问题。
-
使用GAN捕捉模式并还原:开发难度过于费时费力,未尝试
6. 特征筛选
首先,需要计算不同特征的相似度,过于相似的特征需要check,通过相关系数表示,过于相似的特征可以丢弃其中一个。随后,可以通过对正负样本的均值、标准差等进行对比,选取差异大的指标,比如方差太小的特征也可以不使用。最后,使用xgboost特征重要性,random forest重要性,shap分析等方法获得特征重要性排序,筛选靠前的特征进行使用。
值得注意的一点在于,仅通过上述方案,仍会受到模型过拟合、缺失填充不合理等因素带来的影响,必要时需要逐个特征做EDA分析,并反向推动特征衍生的设计,这里的思考不足也导致了最终没能冲进最前排。
7. 无监督特征衍生
对已经提取过时序特征的数据集,可进行如下操作,获取样本异常程度的刻画。值得注意的一点在于,使用此类基于距离度量的无监督方法时需注意,需要提前对特征进行归一化,确保不同维度的特征都处于相同的尺度范围。
from sklearn.neighbors import LocalOutlierFactor
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
import pickle
# 标准化,方便距离度量
zscore_scaler = StandardScaler()
zscore_scaler.fit(samples)
samples = zscore_scaler.transform(samples)
samples = pd.DataFrame(samples)
pickle.dump(zscore_scaler, open('./components/zscore_scaler.pkl','wb'))
# 无监督异常检测模型
left_sample_nums = 200 # 从正常样本(OK)中留出一部分用于训练无监督模型
outlier_clf = LocalOutlierFactor(n_neighbors=20, novelty=True) # 基于密度的Lof模型
outlier_clf.fit(samples.iloc[:left_sample_nums, :])
pickle.dump(outlier_clf, open('./components/lof_model.pkl', 'wb'))
outlier_iof = IsolationForest() # 基于树的孤立森林模型,与Lof取其一即可
outlier_iof.fit(samples.iloc[:left_sample_nums, :])
pickle.dump(outlier_iof, open('./components/iof_model.pkl', 'wb'))
# 用于后续训练有监督模型的样本集合
samples_supervised = samples.iloc[left_sample_nums:, :].reset_index(drop=True)
lof_predict_res = outlier_clf.predict(samples.iloc[left_sample_nums:, :]) # 判断是否异常
lof_predict_score = outlier_clf.score_samples(samples.iloc[left_sample_nums:, :]) # 异常程度得分
samples_supervised['lof_predict_res'] = lof_predict_res
samples_supervised['lof_predict_score'] = lof_predict_score
iof_predict_res = outlier_iof.predict(samples.iloc[left_sample_nums:, :])
iof_predict_score = outlier_iof.score_samples(samples.iloc[left_sample_nums:, :])
samples_supervised['iof_predict_res'] = iof_predict_res
samples_supervised['iof_predict_score'] = iof_predict_score
samples = samples_supervised
labels = labels[left_sample_nums:]更多异常检测算法可参考:14种异常检测方法汇总(附代码)!
8. 有监督模型训练
使用pycaret框架可以快速得到多个模型的表现对比:
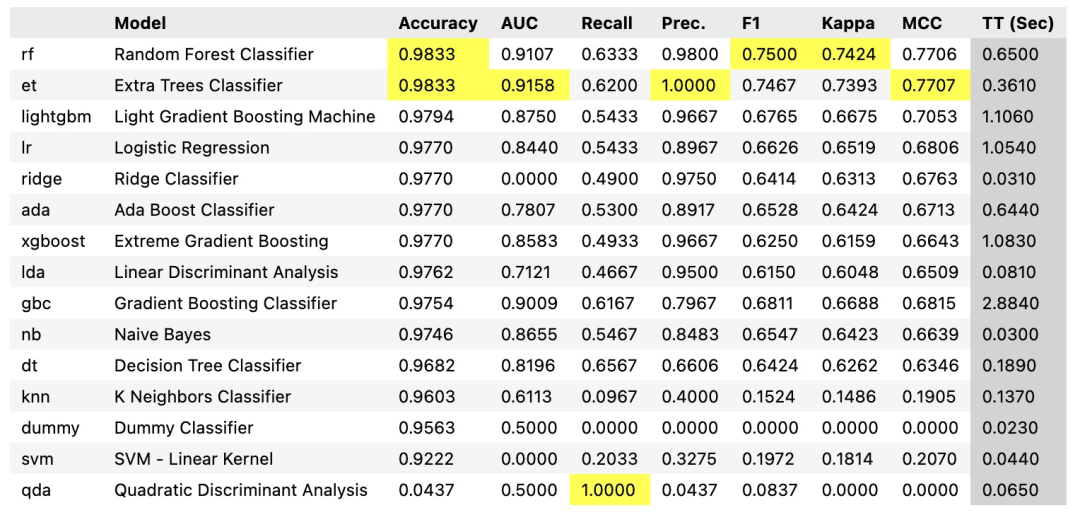
但是由于本地的缺失处理与线上处理方式有差别,且填充方式未必最为合理,故上表所示的模型表现并不一定符合线上表现。此外,序列模型也值得尝试,对于此类的多维时序数据,TCN似乎格外适合,受限于数据本身异常的复杂程度,以及精力问题,尚未尝试。
对于已经训练得到的多个模型,可以采取预测值直接major voting,或预测分数平均化融合,stacking等方法进行多个模型的融合。由于比赛方的最终评分基于公榜评分,可以在保证原始特征不超过限定值的情况下,使用多个高分方案进行融合,也可以进一步提分。
9. 一些不足与反思
-
线上线下分数相关性差:未保持线上一致的缺失处理,影响模型表现。
-
线下5折抖的太厉害,导致无法调参和实验。
-
赛程的最后无限提交环节未进一步利用,对于一些思考和尝试浅尝辄止。
-
闭门造车,与他人的交流太少,未能形成团队合力。
10. 尝试记录与效果简记
以下OK代表正常样本(负样本),NG代表异常样本(正样本)
-
原始时序特征提取:
-
时域11维度特征:均值、方差、分位数一类,事实上仅需要均值即可完全较高的识别准确率
-
时域20维度特征:增加了一些数值出现频次等特征,本地分数略降,线上81分
-
频域特征:本地分数几乎不变,线上再测一次,线上75分
-
时域25维度特征:仍然为80分特征
-
统计意义上的异常点:如3Σ,或者10-90分位点、箱线图等(未做,这里做强特征的机会丢失了)
-
-
缺失填充:
-
统计OK样本的统计值,并使用正态填充:部分传感器的特征并非正态分布,不符合事实,分数较低
-
使用OK样本随机抽取填充:填充的未必合理,且容易让NG样本长的更像OK样本
-
KNN搜索填充,确保缺失填充的尽可能合理精准,避免一些逻辑错误。(未做)
-
OK样本也进行小概率丢弃重填,试试看(未做)
-
由于主办方线上数据集的特殊处理,事实上也需要对正常样本进行一定程度的缺失处理。
-
-
数据增强:
-
手动造出来一些NG样本:分布未必与真实的NG一致(交叉NG样本,生成新的异常样本,未做)
-
-
特征筛选:
-
无区分性:正负样本某些提取的特征统计值几乎一样
-
共线性相关:删除过于相近的sensor,比如同名的report和measure
-
feature importance:随机森林模型:以上三个叠加,81.48分
-
xgboost模型特征重要性:仍81.48分
-
shap特征重要性:似乎应该最为合理,目前使用xgb+shap筛选预筛选后的特征。分值不变
-
基于线上分数再找找看最优配置,先删除5个feature试试看,然后再加上5个试试。(未做,工作量大且不符合业务实际,仅为了提分)
-
更好别的特征再试,10个一批,叠加到60feature,冲84分以上,然后再删除某些feature试试看。(未做,工作量大且不符合业务实际,仅为了提分)
-
特征筛选后续成为本赛题的提分关键。
-
-
无监督特征衍生:(主要创新方向)
-
标准化:距离度量模型,务必需要这一步骤
-
无监督,Lof模型,整体异常检测,异常判定结果和判定分入模,强特征
-
无监督,孤立森林,整体异常检测,https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html#sklearn.ensemble.IsolationForesthttps://zhuanlan.zhihu.com/p/492469453与LOF重合,不提分
-
-
模型选择:
-
xgboost:未精调,降低estimator数量和max depth会稍微好点
-
随机森林:本地效果好,但是线上降分,比xgb略低2分
-
lightgbm:未调参,效果不佳
-
融合:voting(对结果融合或预测分融合均可,最后放弃尝试)
-
-
badcase分析
-
看看NG里的漏判,比较耗时,可以不管(未做,感觉没意义)
-
希望大家可以多多交流,互相学习!
以下为可用于参考的代码,由于数据情况较为复杂,debug难度较大,代码下载地址:
https://datawhaler.feishu.cn/file/boxcnlE1pakks2xyGdx0KGMfACg

干货学习,点赞三连↓