pwd命令是什么的缩写_AnyQ 是什么
Answer your Question
百度研发的一个QA框架,首个工业级基于语义计算的 FAQ 问答系统——AnyQ
是一个配置化、插件化框架, 各功能均通过插件形式加入
如何使用AnyQ 并运行Demo
git clone https://github.com/baidu/AnyQ.git到本地文件夹- windows或者Mac用户建议用docker的方式运行,因为很多包都是linux的环境下才可以用的,否则会遇到很多报错信息
- 下载docker, 并运行
- 下载paddlepaddle镜像
- paddle官方镜像
docker pull paddlepaddle/paddle:latest-dev - paddle国内镜像
docker pull docker.paddlepaddlehub.com/paddle:latest-dev
- 确保docker 引擎运行的swap和memory空间足够,否则在docker中编译cpp程序的时候,会报错,右键docker- preference - Advanced - 调高swap和memory配置。(不一定要按照我的配置设置)
- 在存放AnyQ的路径下, 运行以下指令
docker run -p 8999:8999 -p 8900:8900 -i -t -v $(PWD):/AnyQ/ paddlepaddle/paddle:latest-dev
- docker使用参考资料
- 命令分为:
docker run <相关参数> <镜像 ID> <初始命令> -p:表示可以指定要映射的端口,在一个指定端口上只可以绑定一个容器。支持的格式为hostPort:containerPort,这里表示将宿主机的8999和8900端口和docker容器中的8999和8900互通。因为这两个端口将在demo中用到。8999端口用于anyq服务的端口,8900则是Solr的服务端口。-i:表示以“交互模式”运行容器-t:表示容器启动后会进入其命令行-v:表示需要将本地哪个目录挂载到容器中,格式:-v <宿主机目录>:<容器目录>
- 进入docker并编

运行以下scripts,编译demo cpp程序
cd AnyQ
mkdir build && cd build && cmake .. & make
- 安装完所有的dependencies后,在docker中安装所需要的
jdk>=1.8,并倒入环境变量中
wget http://anyq.bj.bcebos.com/jdk-8u171-linux-x64.tar.gz
tar xzvf jdk-8u171-linux-x64.tar.gz
export PATH=`pwd`/jdk1.8.0_171/bin:$PATH
8.1 docker中配置环境变量,
之后不用每次启动docker都将jdk导入环境变量
- 首先,编辑.bashrc文件
vi ~/.bashrc - 然后,在该文件末尾添加如下配置:
export PATH=AnyQ/build/jdk1.8.0_171/bin:$PATH - 最后,需要使用source命令,让环境变量生效:
source ~/.bashrc
- 获取anyq定制solr,并将数据导入到Solr库中,启动solr
cp ../tools/anyq_deps.sh .sh anyq_deps.shcp ../tools/solr -rp solr_scriptsh solr_script/anyq_solr.sh solr_script/sample_docs
这一步中如果数据导入失败,可以在宿主机的AnyQ/build目录下(不要退出docker),尝试运行sh solr_script/anyq_solr.sh solr_script/sample_docs, 启动Solr服务,然后在docker中重复改步骤。 - 运行demo
./run_server
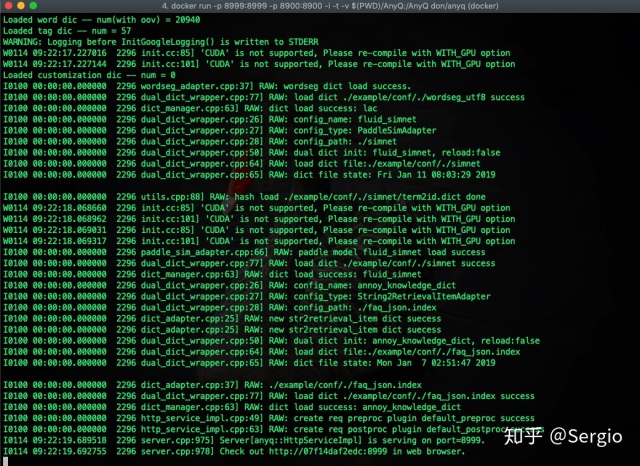
运行成功的截图:
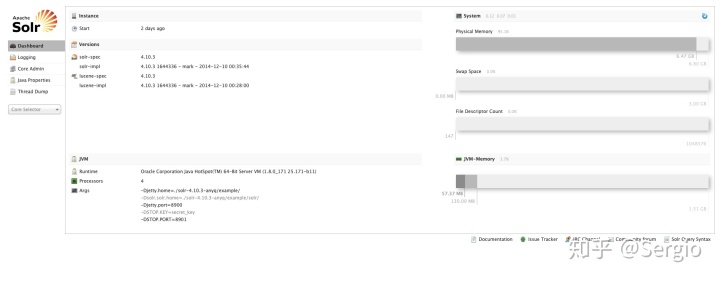
- 打开浏览器,
http://localhost:8900/solr/#/查看Solr搜索引擎的admin页面
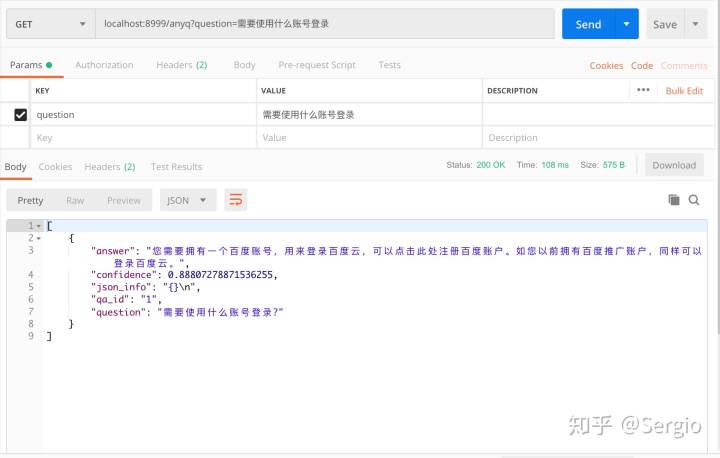
- 在浏览器或者Postman中,可以调用接口
localhost:8999/anyq?question=需要使用什么账号登录查看调用结果
- 退出docker
exit
然后在terminal中,输入docker ps
此时,您应该看不到任何正在运行的程序,因为刚才已经使用exit命令退出的容器,此时容器处于停止状态,可使用如下命令查看所有容器:docker ps -a
输出类似内容:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
57c312bbaad1 e934aafc2206 "/bin/bash" 2 minutes ago Exited (0) 19 seconds ago naughty_goldstine
记住以上CONTAINER ID(容器 ID),随后我们将通过该容器,创建一个可运行 AnyQ的镜像。 - 创建AnyQ镜像
docker commit $(YOUR_CONTAINER_ID) $(YOUR_CONTAINER_NAME)
例如:docker commit 57c312bbaad1 don/anyq是该容器的 ID 是“57c312bbaad1”,所创建的镜像名是“don/anyq”,随后可使用新镜像来启动 新的AnyQ容器。 - 之后跑镜像都可以运行:
在AnyQ工程的parent目录下,docker run -p 8999:8999 -p 8900:8900 -i -t -v $(PWD)/AnyQ:/AnyQ $(你的镜像名)
例如docker run -p 8999:8999 -p 8900:8900 -i -t -v $(PWD)/AnyQ:/AnyQ don/anyq
AnyQ解析
AnyQ 使用 SimNet模型 语义匹配模型构建文本语义相似度,克服了传统基于字面匹配方法的局限。
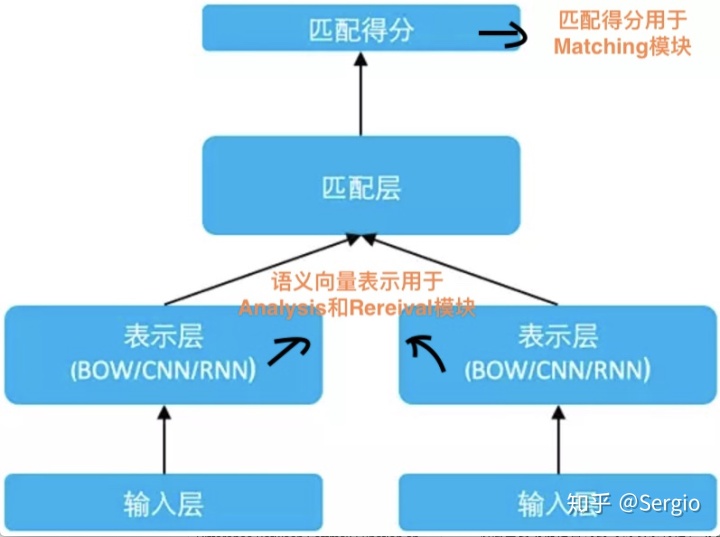
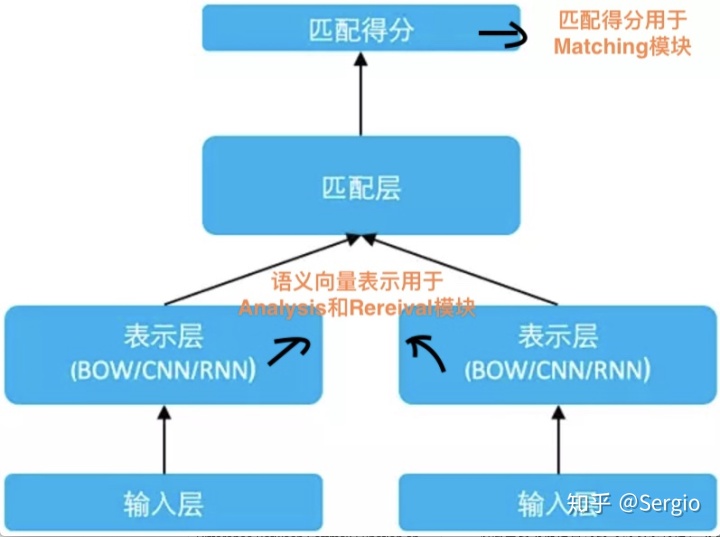
SimNet 框架
- 1.输入层
该层通过 look up table 将文本词序列转换为 word embedding 序列。 - 2.表示层
该层主要功能是由词到句的表示构建,或者说将序列的孤立的词语的 embedding 表示,转换为具有全局信息的一个或多个低维稠密的语义向量。最简单的是 Bag of Words(BOW)的累加方法,除此之外,我们还在 SimNet 框架下研发了对应的序列卷积网络(CNN)、循环神经网络(RNN)等多种表示技术。当然,在得到句子的表示向量后,也可以继续累加更多层全连接网络,进一步提升表示效果。
可以通过fetch 输出node获得该部分输出,节点名tanh.tmp。 - 3.匹配层
该层利用文本的表示向量进行交互计算。可以通过fetch 输出node获得该部分输出,节点名cos_sim_0.tmp
AnyQ 框架
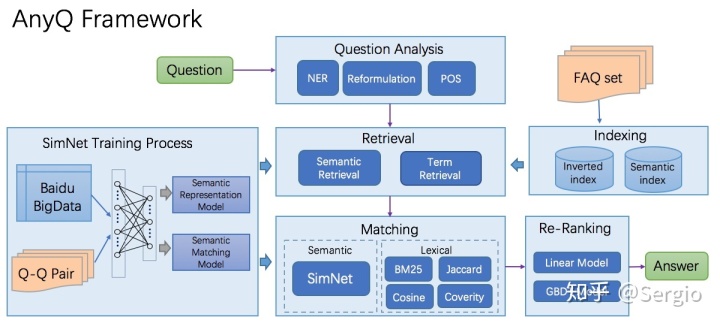
AnyQ主要有4个模块,Question Analysis(问题分析模块), Question Retrival(候选集获取模块),Question Matching(候选集相似度匹配模块),Ranking(候选集排序模块)
数据索引建立-Indexing
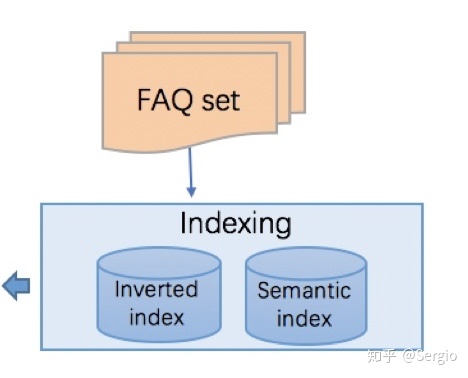
- Inverted Index - Solr (跟Elasticsearch 类似)
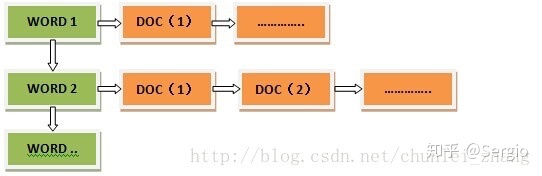
首先,我们有一个FAQ set,我们将它灌入Solr企业级搜索引擎,作为Solr的候选集。可视化链接, 所有的数据都存在Solr的collection1中, 倒排索引。
Solr先对文档进行分词,当文档数据来临时,solr会首先对文档数据进行分词,创建索引库和文档数据库。
正排索引从文档编号找词,
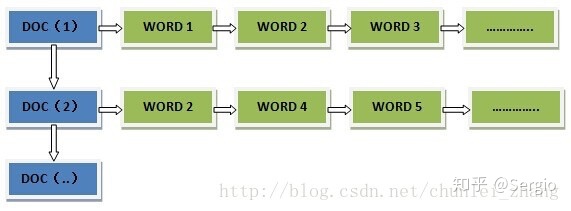
倒排索引是从词找文档编号:
cp ../tools/anyq_deps.sh . sh anyq_deps.sh cp ../tools/solr -rp solr_script sh solr_script/anyq_solr.sh solr_script/sample_docs
- Semantic Index - Annoy
添加语意索引的tutorial
annoy(Approximate Nearest Neighbors Oh Yeah) 超平面多维近似向量查找工具./annoy_index_build_tool example/conf/ example/conf/analysis.conf faq/faq_json.index 128 10 semantic.annoy 1>std 2>err- 市面上几乎最快的算法
- 调用SimNet模型,将所有的问答话术都先进行分词向量表示,转化为 word embedding 序列然后输出语义向量表示,然后将这些向量存入AnnoyIndex,默认余弦相似度可以选择多种进行Index,创建二叉树集合的索引,Annoy可以快速获得语义临近点
- 保存的结果为
build/example/conf/semantic.annoy,之后可以使用这个快速查询的结果会返回指定数目的id的list,其对应的字典为:build/example/conf/faq_json.index
u = AnnoyIndex(dimension) # 语义向量维度
u.load('semantic.annoy') # super fast, will just mmap the file
print(u.get_nns_by_item(0, 10)) # will find the 1000 nearest neighbors
SimNet 框架
Analysis
中文词法分析(LAC)
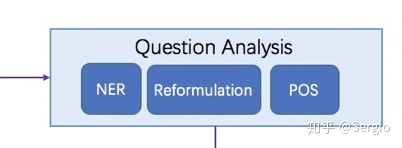
- 百度的LAC是一个联合的词法分析模型,整体性地完成中文分词(SEG)、词性标注(POS)、专名识别(NER)任务。LAC既可以认为是Lexical Analysis of Chinese的首字母缩写,也可以认为是LAC Analyzes Chinese的递归缩写。
- LAC基于一个堆叠的双向GRU结构bi-GRU-CRF结构
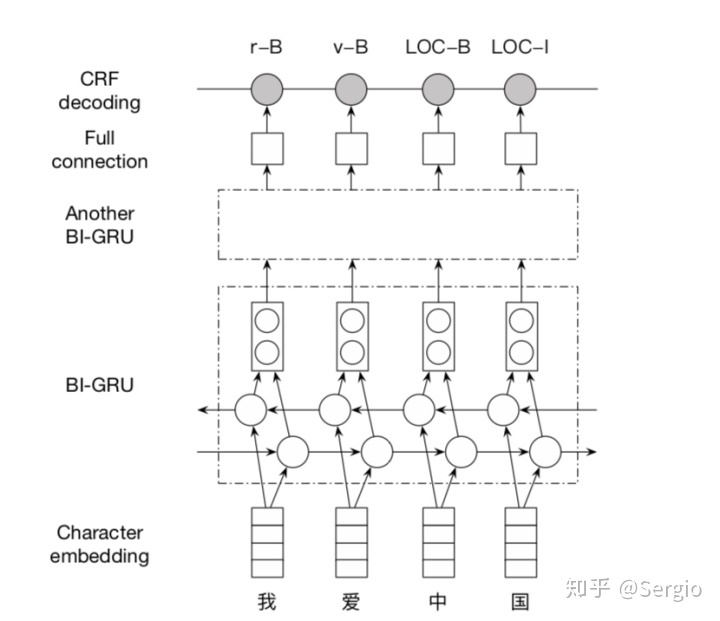
输入
2003年10月15日北京时间9时,杨利伟乘由长征二号F火箭运载的神舟V号飞船首次进入太空输出
2003年10月15日 TIME 0 17 北京 LOC 17 6 时间 n 23 6 9时 TIME 29 4 , w 33 1 杨利伟 PER 34 9 乘 v 43 3 由 p 46 3 长征二号F nz 49 13 火箭 n 62 6 运载 v 68 6 的 u 74 3 神舟V号 nz 77 10 飞船 n 87 6 首次 m 93 6 进入 v 99 6 太空 s 105 6
- 调用的是baidu的LAC库
Reformulation
- 使用的是百度的SimNet模型的,将分词结果,通过字典映射,然后padding 后得到指定dimension的向量作为模型输入,然后获取每个query的词向量word embedding表示,之后fetch模型的语义向量表示。
Retrival
从问题分析获得分析结果会传到Retrival中,获得Retrival结果。
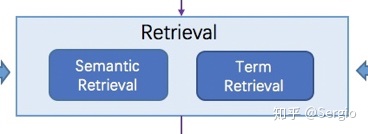
Term检索
从Solr搜索引擎中获取候选集,有不同的Solr查询插件,例如
* EqualSolrQBuilder:字段等于
* BoostSolrQBuilder:字段term加权
* ContainSolrQBuilder:字段包含关键词
* SynonymSolrQBuilder:字段term同义词
* DateCompareSolrQBuilder:日期字段比较
语义检索
语义检索从Aanalysis的分析结果中的语义向量表示字段,然后在根据Annoy 获取其最近的k个问题的id列表,通过id列表字典对应到Retrival的结果列表。
强制干预
人工干预的检索结果优先级最高,query如果命中干预字典,将anyq_end设置为true, 跳过其他的检索和rank
Matching 匹配
首先需要对候选集RetrivalResults进行分词,然后进行语义或者词法匹配,每一种匹配方法都会输出一个分值,作为匹配结果Candidates的一个feature。可以配置多种匹配方法,获取不同的features特征。
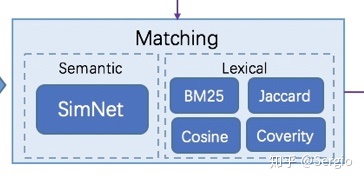
Semantic Matching 语义匹配
百度SimNet 模型可以输出语义匹配相似度。
Lexical Matching 词法匹配
分词的结果进行不同的相似度计算
- BM25: query与候选的BM25相似度
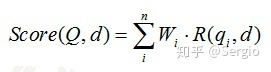
Q表示查询Query,qi表示查询被解析得到的分词qi,d表示搜索结果文档d,Wi表示分词qi的权重,R(qi,d)表示分词qi与文档d的相关性得分。定义一个词与文档相关性的权重方法有很多,较常用的有IDF。
- Jaccard:交集/并集
- ContainSimilarity:该特征表示query与候选之间是否存在包含关系
- EditDistance: 表示query与候选编辑距离相似度
- Cosine Similarity: 表示query与候选在字面上的余弦相似度
Rank 排序
排序模型,排序模型将会对Candidates的文档进行评分,并给出一个最终得分ltr_score。
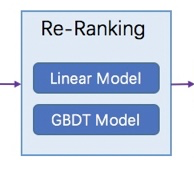
线性排序模型
给定给个feature一个权重,加权获得最终得分
特征选择预测模型
选定一个feature最为最终得分
非线性- XGBoost 模型
排序模型
Answer
排序 -> 删除分数低于阈值的项 -> 删除重复 -> 输出结果
AnyQ系统配置教程
在AnyQ系统中,词典和策略都以插件的形式封装。开发者可以根据实际的业务需要配置Analysis、Retrieval、Matching和Ranking策略及相关的词典。Anyq的配置文件需按照Protobuf格式。
四个模块可以进行插拔化设置,除此之外,还需要设置字典的配置。
load词典
在策略插件中使用的词典,需在dict.conf中配置。当前系统的词典插件主要包括以下几种:
- 哈希词典:HashAdapter<TYPE1, TYPE2>
- 干预词典:String2RetrievalItemAdapter
- 切词词典: WordsegAdapter
- Paddle SimNet匹配模型词典: PaddleSimAdapter
- Tensorflow模型词典: TFModelAdapter
配置的格式, 举例如下
# Paddle SimNet匹配模型词典: PaddleSimAdapter
dict_config {
name: "fluid_simnet"
type: "PaddleSimAdapter"
path: "./simnet"
}
# Tensorflow模型词典: TFModelAdapter
dict_config {
name: "tf_qq_match"
type: "TFModelAdapter"
path: "./tf_model"
}
策略类型的插件如果要使用词典,需给策略插件的using_dict_name与词典的name配置相同的值。
Analysis
在analysis.conf中可以增添query分析策略插件。当前系统的analysis插件主要包括以下几种:
- 切词:AnalysisWordseg
- query语义向量表示:AnalysisSimNetEmb
- query替换: AnalysisQueryIntervene
配置的格式如下
analysis_method {
name: "method_simnet_emb"
type: "AnalysisSimNetEmb"
using_dict_name: "fluid_simnet"
dim: 128
query_feed_name: "left"
cand_feed_name: "right"
embedding_fetch_name: "tanh.tmp"
}
Retrieval配置
在retrieval.conf中可以增添检索策略插件。当前系统的retrieval插件主要包括以下几种:
- Term检索:TermRetrievalPlugin
- 语义检索:SemanticRetrievalPlugin
- 人工干预:ManualRetrievalPlugin
配置的格式如下
retrieval_plugin {
name : "term_recall_1"
type : "TermRetrievalPlugin"
search_host : "127.0.0.1"
search_port : 8900
engine_name : "collection1"
solr_result_fl : "id,question,answer"
solr_q : {
type : "EqualSolrQBuilder"
name : "equal_solr_q_1"
solr_field : "question"
source_name : "question"
}
num_result : 15
}
- Solr查询插件
其中"solr_q"是solr查询的插件,当前可配置的solr查询插件包括:- EqualSolrQBuilder:字段等于
- BoostSolrQBuilder:字段term加权
- ContainSolrQBuilder:字段包含关键词
- SynonymSolrQBuilder:字段term同义词
- DateCompareSolrQBuilder:日期字段比较
Matching
在rank.conf中可以增添匹配策略插件。当前系统的matching插件主要包括以下几种:
- 编辑距离相似度:EditDistanceSimilarity
- Cosine相似度:CosineSimilarity
- Jaccard相似度: JaccardSimilarity
- BM25相似度: BM25Similarity
- Paddle SimNet匹配模型相似度: PaddleSimilarity
- Tensorflow匹配模型相似度: TFSimilarity
- 对候选切词:WordsegProcessor
配置的格式如下
# Paddle SimNet匹配模型相似度: PaddleSimilarity
matching_config {
name: "fluid_simnet_similarity"
type: "PaddleSimilarity"
using_dict_name: "fluid_simnet"
output_num : 1
rough : false
query_feed_name: "left"
cand_feed_name: "right"
score_fetch_name: "cos_sim.tmp"
}
# Tensorflow匹配模型相似度: TFSimilarity
matching_config {
name : "tf_qq_match"
type : "TFSimilarity"
using_dict_name: "tf_qq_match"
output_num : 1
rough : false
tfconf : {
pad_id : 0
sen_len: 32
left_input_name: "left"
right_input_name: "right"
output_name: "output_prob"
}
}
其中output_num表示该插件输出的相似度值个数,对于不输出相似度的插件(如WordsegProcessor),output_num应配置为0; rough配置为true表示该相似度用于粗排,反之则用于精排。
计算相似度需要先对候选切词,因此WordsegProcessor插件应该配置在其他matching_config之前。
Ranking
在rank.conf中配置predictorc插件,用于根据多个相似度对候选计算得分。当前系统的rank插件主要包括以下几种:
- 线性预测模型: PredictLinearModel
- XGBoost预测模型: PredictXGBoostModel
- 特征选择预测模型:PredictSelectModel
配置的格式如下
rank_predictor {
type: "PredictLinearModel"
using_dict_name: "rank_weights"
}
添加插件
添加插件
- 头文件定义,继承相对应的接口
- DictInterface
- AnalysisMethodInterface
- RetrivalPluginInterface
- MatchingInterface
- RankPredictInterface
- 注册插件
- 功能实现
- 编译
以BM25Similarity插件为实例,说明如何添加用户自定义插件。
头文件定义
- BM25Similarity是Matching插件,需继承MatchingInterface接口,并重写相关的虚函数.
include/matching/lexical/bm25_sim.h
...
class BM25Similarity : public MatchingInterface {
public:
BM25Similarity();
virtual ~BM25Similarity() override;
virtual int init(DualDictWrapper* dict, const MatchingConfig& matching_config) override;
virtual int destroy() override;
virtual int compute_similarity(const AnalysisResult& analysis_res,
RankResult& candidates) override;
...
}; - 注册BM25Similarity插件.
include/common/plugin_header.h
...
#include "matching/lexical/bm25_sim.h"
...
REGISTER_PLUGIN(BM25Similarity);
...
功能实现
- 实现构造、析构、init、destroy、compute_similarity等函数。
src/matching/lexical/bm25_sim.cpp
...
BM25Similarity::BM25Similarity(){
...
}
...
BM25Similarity::~BM25Similarity(){
...
}
...
int BM25Similarity::init(DualDictWrapper* dict, const MatchingConfig& matching_config) {
...
}
...
int BM25Similarity::destroy() {
...
}
...
如何编译
mkdir build && cd build && cmake .. && make
AnyQ的用途
- FAQ 问答技术作为智能客服系统最核心技术之一,在智能客服系统中发挥重要作用。通过该技术,可实现在知识库中快速找到与用户问题相匹配的问答,为用户提供满意的答案,从而极大提升客服人员效率,改善客服人员服务化水平,降低企业客服成本。
- 闲聊系统
- 辅助销售