爬取课件资源的爬虫
闲来无事,爬一爬现在学生的课件ppt资源,做一做数据分析,看看孩子们都在学一些什么。
一、开始分析下载的流程:
1、一级页面

2、二级页面
http://www.1ppt.com/kejian/5769.html

根据标题来看,这个还是一个汇总,要下载详细的ppt内容还要往下看。

往下翻看到了正主,这个就是我们所需要的ppt课件
3、三级页面

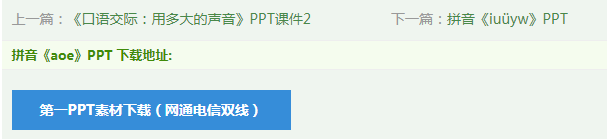
进入了单节课程的页面,往下翻可以看到下载地址。
二、开始考虑爬虫的编写:
- 我使用的是scrapy框架。
- 由于首先进入的是首页,所以我使用的是crawl spider编写rule规则来获取各个出版社资源的子页面url。
- 进入二级页面之后,还要获取所有课程的名称和三级页面url。
- 进入三级页面,获取到ppt下载链接。
- 改写为scrapy-redis爬虫。
开始编写爬虫:
1、创建爬虫项目:
# 打开anaconda prompt 切换环境,输入
scrapy startproject ppt
# 进入 ./ppt,输入
scrapy genspider -t crawl downloadppt 1ppt.com # 创建crawl spider
2、导入爬虫项目,我用的是Sublime Text

3、开始一级页面
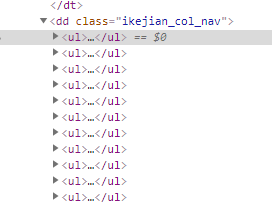
发现二级页面的a标签都在 class='ikejian_col_nav'的dd标签中,并且二级页面的url是/kejian/\d+.html的样式。
基于分析开始写规则:
rules = (
Rule(LinkExtractor(allow=r'.+/\d+\.html', restrict_xpaths='//dd[@class="ikejian_col_nav"]'), callback='parse_detail', follow=False),
)
# restrict_xpaths:捕获该标签下的所有/\d+.html的url并发送请求4、分析二级页面
![]()
首先获得二级页面的标题
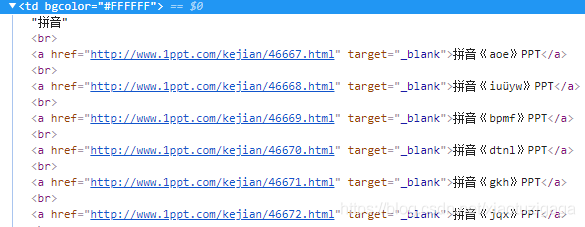
其次获得下面三级页面的url和标题,然后根据url发送请求得到三级页面
def parse_detail(self, response):
textbook_name = response.xpath('//*[@class="ppt_info clearfix"]/h1/text()').get()
# replace主要是后面用于数据分析方便先做一次清洗
textbook_name = textbook_name.replace('【目录】', '').replace('PPT课件', '')
lesson_name = response.xpath('//td[@bgcolor="#FFFFFF"]/a/text()').getall()
url_to_ppt = response.xpath('//td[@bgcolor="#FFFFFF"]/a/@href').getall()
for name, url in zip(lesson_name, url_to_ppt):
request = scrapy.Request(url=url, callback=self.get_download_url, dont_filter=True)
# 这里对获取的信息不做处理,将二级目录的信息传到下一个函数处理
request.meta['lesson_name'] = name
request.meta['url_to_ppt'] = url
request.meta['textbook_name'] = textbook_name
yield request3、分析三级页面
进入三级页面获得下载url并保存在item中

class PptItem(scrapy.Item):
textbook_name = scrapy.Field() # 二级目录名
lesson_name = scrapy.Field() # 三级目录名
url_to_ppt = scrapy.Field() # 通往三级目录的url
ppt_download_url = scrapy.Field() # 三级目录文件下载urldef get_download_url(self, response):
lesson_name = response.meta['lesson_name']
url_to_ppt = response.meta['url_to_ppt']
textbook_name = response.meta['textbook_name']
download_url = response.xpath('//ul[@class="downurllist"]/li/a/@href').get()
item = PptItem(ppt_download_url=download_url, textbook_name=textbook_name, lesson_name=lesson_name, url_to_ppt = url_to_ppt)
yield item4、写一些配置文件:
首先进入settings.py
# 以下是要设置的
ROBOTSTXT_OBEY = False
MY_USER_AGENT = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
]
# 之后更改为scrapy-redis时,出现301,所以这边写上允许301
HTTPERROR_ALLOWED_CODES = [301]
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
'ppt.middlewares.MyUserAgentMiddleware': 400,
}其次进入middlewares.py
# 以下是增加的
# 用来配合settings中的user-agent随机切换
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
class MyUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent = crawler.settings.get('MY_USER_AGENT')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent最后运行爬虫
# 以下是在anaconda prompt中运行的
# 进入ppt项目文件夹
scrapy crawl downloadppt
# 看见信息了ok,ctrl+c停掉他,我们还要改写为scrapy-redis三、改写为redis-scrapy
1、进入settings.py
# 以下是加入的内容
# 1.(必须加)。使用scrapy_redis.duperfilter.REPDupeFilter的去重组件,在redis数据库里做去重。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 2.(必须加)。使用了scrapy_redis的调度器,在redis里面分配请求。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 3.(必须加)。在redis queues 允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 4.(必须加)。通过RedisPipeline将item写入key为 spider.name: items的redis的list中,供后面的分布式处理item。
# 这个已经由scrapy-redis实现了,不需要我们自己手动写代码,直接使用即可。
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100
}
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 63792.进入./spider/downloadppt.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
import re
from ppt.items import PptItem
# 新加入1
# 继承时,使用上面引入的RedisCrawlSpider代替之前的CrawlSpider
class DownloadpptSpider(RedisCrawlSpider):
name = 'downloadppt'
allowed_domains = ['1ppt.com']
# 新加入2,这个是用来在redis客户端输入的
redis_key = 'ppt:start_urls'
# 新删除1,start_urls,以前这里有一个start_urls现在不需要了
rules = (
Rule(LinkExtractor(allow=r'.+/\d+\.html', restrict_xpaths='//dd[@class="ikejian_col_nav"]'), callback='parse_detail', follow=False),
)
def parse_detail(self, response):
textbook_name = response.xpath('//*[@class="ppt_info clearfix"]/h1/text()').get()
textbook_name = textbook_name.replace('【目录】', '').replace('PPT课件', '')
lesson_name = response.xpath('//td[@bgcolor="#FFFFFF"]/a/text()').getall()
url_to_ppt = response.xpath('//td[@bgcolor="#FFFFFF"]/a/@href').getall()
for name, url in zip(lesson_name, url_to_ppt):
request = scrapy.Request(url=url, callback=self.get_download_url, dont_filter=True)
request.meta['lesson_name'] = name
request.meta['url_to_ppt'] = url
request.meta['textbook_name'] = textbook_name
yield request
def get_download_url(self, response):
lesson_name = response.meta['lesson_name']
url_to_ppt = response.meta['url_to_ppt']
textbook_name = response.meta['textbook_name']
download_url = response.xpath('//ul[@class="downurllist"]/li/a/@href').get()
item = PptItem(ppt_download_url=download_url, textbook_name=textbook_name, lesson_name=lesson_name, url_to_ppt = url_to_ppt)
yield item
3、执行爬虫
# 以下是在conda prompt中执行的
# 可以多开几个,一起执行
scrapy crawl downloadppt4、进入redis的bin目录,开启服务器和客户端,输入
# 以下是在redis客户端中输入的
lpush ppt:start_urls http://www.1ppt.com/kejian5、开始爬取信息,爬虫成功!
版权声明:本文为xiaotuzigaga原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。