k-均值聚类简介
k-均值聚类:将训练集分成k个靠近彼此的不同样本聚类。因此我们可以认为该算法提供了k-维的one-hot编码向量h以表示输入x。当x属于聚类i时,有hi=1,h的其它项为零。k-均值聚类提供的one-hot编码也是一种稀疏表示,因为每个输入的表示中大部分元素为零。one-hot编码是稀疏表示的一个极端示例,丢失了很多分布式表示的优点。one-hot编码仍然有一些统计优点(自然地传达了相同聚类中的样本彼此相似的观点),也具有计算上的优势,因为整个表示可以用一个单独的整数表示。
k-均值聚类初始化k个不同的中心点{μ(1),…,μ(k)},然后迭代交换两个不同的步骤直到收敛。步骤一,每个训练样本分配到最近的中心点μ(i)所代表的聚类i。步骤二,每一个中心点μ(i)更新为聚类i中所有训练样本x(j)的均值。
关于聚类的一个问题是聚类问题本身是病态的。这是说没有单一的标准去度量聚类的数据在真实世界中效果如何。我们可以度量聚类的性质,例如类中元素到类中心点的欧几里得距离的均值。这使我们可以判断从聚类分配中重建训练数据的效果如何。然而我们不知道聚类的性质是否很好地对应到真实世界的性质。此外,可能有许多不同的聚类都能很好地对应到现实世界的某些属性。我们可能希望找到和一个特征相关的聚类,但是得到了一个和任务无关的,同样是合理的不同聚类。例如,假设我们在包含红色卡车图片、红色汽车图片、灰色卡车图片和灰色汽车图片的数据集上运行两个聚类算法。如果每个聚类算法聚两类,那么可能一个算法将汽车和卡车各聚一类,另一个根据红色和灰色各聚一类。假设我们还运行了第三个聚类算法,用来决定类别的数目。这有可能聚成了四类,红色卡车、红色汽车、灰色卡车和灰色汽车。现在这个新的聚类至少抓住了属性的信息,但是丢失了相似性信息。红色汽车和灰色汽车在不同的类中,正如红色汽车和灰色卡车也在不同的类中。该聚类算法没有告诉我们灰色汽车和红色汽车的相似度比灰色卡车和红色汽车的相似度更高。我们只知道它们是不同的。这些问题说明了一些我们可能更偏好于分布式表示(相对于one-hot表示而言)的原因。分布式表示可以对每个车辆赋予两个属性----一个表示它颜色,一个表示它是汽车还是卡车。目前仍然不清楚什么是最优的分布式表示(学习算法如何知道我们关心的两个属性是颜色和是否汽车或卡车,而不是制造商和年龄?),但是多个属性减少了算法去猜我们关心哪一个属性的负担,允许我们通过比较很多属性而非测试一个单一属性来细粒度地度量相似性。
k-均值算法源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-均值聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离它最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
k-均值聚类与k-近邻算法之间没有任何关系。
k-均值聚类算法描述:已知观测集(x1,x2,…,xn),其中每个观测都是一个d-维实向量,k-均值聚类要把这n观测划分到k个集合中(k≤n),使得组内平方和(WCSS within-cluster sum of squares)最小。换句话说,它的目标是找到使得下式满足的聚类Si:其中μi是Si中所有点的均值。
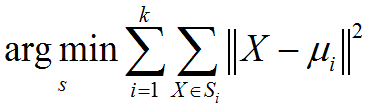
k-均值聚类标准算法:最常用的算法使用迭代优化的技术。它被称为k-均值算法而广为使用,有时也被称为Lloyd算法(尤其在计算机科学领域)。已知初始化的k个均值点m1(1),…,mk(1),算法按照下面两个步骤交替进行:
(1)、分配(Assignment):将每个观测分配到聚类中,使得组内平方和(WCSS)达到最小。因为这一平方和就是平方后的欧式距离,所以很直观地把观测分配到离它最近的均值点即可:
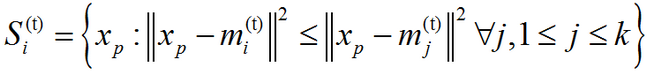
其中每个xp都只被分配到一个确定的聚类St中,尽管在理论上它可能被分配到2个或者更多的聚类。
(2)、更新(Update):对于上一步得到的每一个聚类,以聚类中观测值的质心(centroids)作为新的均值点:
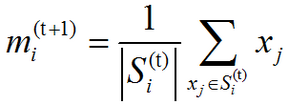
因为算术平均是最小二乘估计,所以这一步同样减少了目标函数组内平方和(WCSS)的值。这一算法将在对于观测的分配不再变化时收敛。由于交替进行的两个步骤都会减少目标函数WCSS的值,并且分配方案只有有限种,所以算法一定会收敛于某一(局部)最优解。注意:使用这一算法无法保证得到全局最优解。
这一算法经常被描述为”把观测按照距离分配到最近的聚类”。标准算法的目标函数是组内平方和(WCSS),而且按照”最小二乘和”来分配观测,确实是等价于按照最小欧氏距离来分配观测的。如果使用不同的距离函数来代替(平方)欧氏距离,可能使得算法无法收敛。然而,使用不同的距离函数,也能得到k-均值聚类的其他变体,如球体k-均值算法和k-中心点算法。
初始化方法:通常使用的初始化方法有Forgy和随机划分(Random Partition)方法。Forgy方法随机地从数据集中选择k个观测作为初始的均值点;而随机划分方法则随机地为每一观测指定聚类,然后运行”更新(Update)”步骤,即计算随机分配的各聚类的中心,作为初始的均值点。Forgy方法易于使得初始均值点散开,随机划分方法则把均值点都放到靠近数据集中心的地方。随机划分方法一般更适用于k-调和均值和模糊k-均值算法。对于期望-最大化(EM)算法和标准k-均值算法,Forgy方法作为初始化方法的表现会更好一些。
这是一个启发式算法,无法保证收敛到全局最优解,并且聚类的结果会依赖于初始的聚类。又因为算法的运行速度通常很快,所以一般都以不同的起始状态运行多次来得到更好的结果。不过,在最差的情况下,k-均值算法会收敛地特别慢。
注:把”分配”步骤视为”期望”步骤,把”更新”步骤视为”最大化步骤”,可以看到,这一算法实际上是广义期望--最大化算法(GEM)的一个变体。
使得k-均值算法效率很高的两个关键特征同时也被经常被视为它最大的缺陷:
(1)、聚类数目k是一个输入参数。选择不恰当的k值可能会导致糟糕的聚类结果。这也是为什么要进行特征检查来决定数据集的聚类数目了。
(2)、收敛到局部最优解,可能导致”反直观”的错误结果。
k-均值算法的一个重要的局限性即在于它的聚类模型。这一模型的基本思想在于:得到相互分离的球状聚类,在这些聚类中,均值点趋向收敛于聚类中心。 一般会希望得到的聚类大小大致相当,这样把每个观测都分配到离它最近的聚类中心(即均值点)就是比较正确的分配方案。k-均值聚类的结果也能理解为由均值点生成的Voronoi cells。
k-均值聚类(尤其是使用如Lloyd's算法的启发式方法的聚类)即使是在巨大的数据集上也非常容易部署实施。正因为如此,它在很多领域都得到的成功的应用,如市场划分、机器视觉、 地质统计学、天文学和农业等。它经常作为其他算法的预处理步骤,比如要找到一个初始设置。
在(半)监督学习或无监督学习中,k-均值聚类被用来进行特征学习(或字典学习)步骤。基本方法是,首先使用输入数据训练出一个k-均值聚类表示,然后把任意的输入数据投射到这一新的特征空间。 k-均值的这一应用能成功地与自然语言处理和计算机视觉中半监督学习的简单线性分类器结合起来。在对象识别任务中,它能展现出与其他复杂特征学习方法(如自动编码器、受限Boltzmann机等)相当的效果。然而,相比复杂方法,它需要更多的数据来达到相同的效果,因为每个数据点都只贡献了一个特征(而不是多重特征)。
K-Means算法概要:来自 酷 壳 – CoolShell ,因为表述的很形象,所以在这里引用下
