Adversarial Reinforcement Learning for Unsupervised Domain Adaptation
参考Adversarial Reinforcement Learning for Unsupervised Domain Adaptation - 云+社区 - 腾讯云
摘要
将知识从已有标签的域转移到新的域时,往往会发生域转移,由于域之间的差异导致性能下降。 域适配是缓解这一问题的一个突出方法。 目前已有许多预先训练好的神经网络用于特征提取。 然而,很少有工作讨论如何在源域和目标域的不同预训练模型中选择最佳特性实例。通过采用强化学习我们提出了一种新的方法来选择特征,再两个域上学习选择最相关的特征。具体地说,在这个框架中,我们使用Q-learning来学习agent的策略来进行特征选择, 通过逼近action-value来进行决策。 在选择最优特征后,我们提出一种对抗分布对齐学习来改进预测结果。 大量的实验证明,该方法优于目前最先进的方法。
1、介绍
对各类数据的自动分类要求很高。 然而,大量的标记训练数据是高质量机器学习模型的先决条件。 不幸地是,手工注释通常涉及巨大的人力成本。 因此,通常有必要将知识从已有的已标记领域转移到未标记的新域。 然而,由于域漂移现象,机器学习模型不能很好地从一个已有的领域泛化到一个新的未标记的领域。 域适配是一种有效的缓解域漂移问题的方法。基于深度学习和传统学习的模型都进行了探索。
传统方法依赖实例(如图像)的特征表示来执行域适配任务。 随着在大数据集上训练的不同深度神经网络的出现,传统方法的特征由低级特征转变为深层特征(Alexnet、ResNet-50、Xception、InceptionResNet等)。 分布对齐包括边缘分布对齐、条件分布对齐和联合分布。 子空间学习包括欧氏空间和黎曼空间中的方法。 然而,传统方法的性能受到提取特征的严重影响;一个更好的ImageNet模型比一个精度较低的ImageNet模型产生更好的特征。
近年来,深度学习方法在域适配方面取得了巨大的成功。 大多数深度域适配网络要么设计新的距离度量来度量两个域之间的差异,要么通过对抗训练的域不变特征。 基于距离的方法旨在最小化源域和目标域之间的差异。 受GAN的启发,基于对抗学习的方法由域分类器和鉴别器组成。 分类器的目的是区分源域和目标域,鉴别器的目的是欺骗分类器。 通过极小极大对策,可以使源域和目标域之间的距离最小化。 域对抗神经网络(DANN)考虑一个最小化损失集成梯度反转层来提高源域和目标域的分辨能力。 对抗判别域自适应(ADDA)方法使用倒置标签GAN损失来分割源域和目标域,可以分别学习特征。 张等人使用源域和目标域之间的混淆度对目标域样本重新加权。 目标样本被赋予较高的权值,会混淆域鉴别器。 域对称网络(SymNet)包含源域和目标域分类器的对称设计。 该方法通过学习两个域之间的不变特征来改善域级别损失。

在本文中,我们提出使用强化学习来选择源和目标域的最佳特征对,并与对抗分布对齐学习模块交互,这样我们可以学习域不变特征并进一步最小化域差异。 我们的贡献有三方面:
1、我们提出了一种新的无监督域适应(ARL)的对抗强化学习框架。 采用强化学习作为特征选择器来识别源和目标域之间最接近的特征对。
2、我们还开发了一个新的奖励源和目标领域。 在目标上提出的深度相关奖励可以指导agent学习最优策略,并为两个域选择最接近的特征对。
3、提出的对抗性学习方法和域分布对齐方法共同减小了源域和目标域之间的差异。
在基准数据集上的大量实验表明,与目前的技术水平相比,分类精度有了显著的提高。
2、相关工作
现有的领域自适应方法,包括传统方法和基于深度学习的方法,或多或少地依赖于预先训练好的模型进行特征提取。 在[50]之前的工作中,我们探讨了16个深度预训练ImageNet模型的模型选择对12种域适配的影响。 我们发现一个更高精度的ImageNet模型将产生更好的无监督DA特征。 然而,这项工作并没有探究来自同一预先训练模型的特征是否最优。
图1是使用不同特征提取器对一幅源图像和一幅目标图像的t-SNE视图。 之前的工作只评估了相同域的模型(例如,使用ResNet-50特征训练源数据,也使用ResNet-50特征测试目标数据)。 然而,这种策略可能不是最优的,因为不同的特征提取器可以缩减源域和目标域之间的距离。 在图1b)中,在投影的2D空间中,ShuffleNet和NasnetMobile的距离更近。 同样地,在原始空间中,这些特征之间的距离可能比其他特征更近,这表明这两个特征集之间的距离最小。 因此,识别两个域之间如此接近的特征是很重要的。
强化学习(RL)在与复杂环境交互学习复杂策略方面表现出了鲁棒性,被广泛应用于文本/图像识别和目标跟踪等任务中。 Feng等人使用RL作为实例选择器,过滤噪声数据,选择高质量的句子,提高关系分类精度。 Carr等人提出了一种使用RL初始化对抗性自编码网络的算法;他们使用随机策略将源域状态表示空间转移到目标域。 解纠缠表示学习代理(DARLA)模型采用去噪自编码器来学习视觉系统,将来自环境的观测数据编码为解纠缠表示,并学习零样本DA的源策略。
最近的工作是DARL (Domain Adversarial Reinforcement Learning),专注于从标签丰富的源域选择数据实例到标签稀缺的目标域,称为部分域适配,但它不推广到无监督域自适应,如果在源域中没有足够的标签。 DARL只使用RL选择相关源数据,然后使用对抗学习最小化源和目标域之间的距离。 但是,这个RL范例依赖于源域中的丰富标签,如果源域中的标签数量与目标域中的相同,则会失败。 因此,应进一步探讨无监督域适应的RL范式。
3、背景
在本节中,我们简要概述领域适应、强化学习和对抗学习的概念,这是我们模型的主要组成部分。
3.1、UDA
对于无监督域适配,给定![]() 类
类![]() 标记样本的源域
标记样本的源域![]() 和无任何标记的目标域
和无任何标记的目标域![]() (仅用于评价
(仅用于评价![]() )。 我们的最终目标是在特征提取器
)。 我们的最终目标是在特征提取器![]() 下学习分类器
下学习分类器![]()
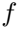 ,以确保目标域中更低的泛化误差。
,以确保目标域中更低的泛化误差。
我们提出了一种新的无监督域自适应框架,该框架能够从不同的预训练神经网络中选择最佳的特征对。
3.2、RL
RL范式旨在训练agent与未知环境进行交互,并使任务的累积报酬最大化。 agent从环境中获得观察和奖励,并对环境执行操作。 这个问题可以建模为一个马尔可夫决策过程(MDP),它被定义为一个元组![]() ,
,![]() 是一组,A是一组动作,
是一组,A是一组动作,![]() 是转换函数
是转换函数![]() ,它模拟了在状态
,它模拟了在状态![]() 中给定动作
中给定动作![]() 的下一个状态
的下一个状态![]() 的可能性。 R是奖励函数
的可能性。 R是奖励函数![]() ,从状态s得到奖励R,折扣因子γ为0≤γ≤1。 RL的目标是学习一个策略
,从状态s得到奖励R,折扣因子γ为0≤γ≤1。 RL的目标是学习一个策略![]() ,它使期望奖励的折扣最大化:
,它使期望奖励的折扣最大化:![]() 。
。![]() 是每一节结束的时间步长。
是每一节结束的时间步长。
在我们的工作中,我们使用一个Q学习代理保持一个惩罚![]() 来估计价值函数。 它将观察S和动作A作为输入,输出相应的报酬期望。
来估计价值函数。 它将观察S和动作A作为输入,输出相应的报酬期望。
3.3、对抗学习
对抗学习通过特征提取器和域鉴别器最小化域差异。 域鉴别器的目的是区分源域和目标域,而特征提取器的目的是学习域不变表示来欺骗域鉴别器。
已知特征提取器![]() 的特征表示,我们可以学习一个鉴别器D,它可以使用以下损失函数来区分这两个域:
的特征表示,我们可以学习一个鉴别器D,它可以使用以下损失函数来区分这两个域:
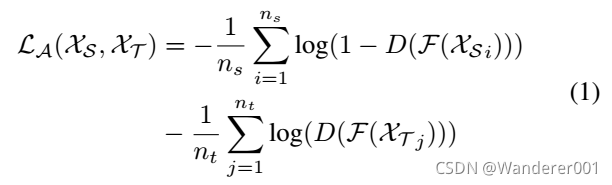
鉴别器![]() 通过固定
通过固定![]() ,使
,使![]() 最大化来学习域分布,特征提取器
最大化来学习域分布,特征提取器![]() 通过最优鉴别器
通过最优鉴别器![]() 使
使![]() 最小化来学习域不变表示。对于标记源域的任务,它使以下交叉熵损失最小化。
最小化来学习域不变表示。对于标记源域的任务,它使以下交叉熵损失最小化。
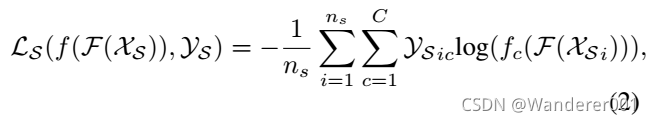
其中f为源域分类器,![]()
![]() 为各类在真实标签中每个类的概率,
为各类在真实标签中每个类的概率,![]() 为预测概率。
为预测概率。
4、方法
4.1、动机
在UDA中,以往的工作大多只考虑了一个预先训练的模型的特征提取器![]() ,而没有探索其他模型。 正如前面提到的,我们探索了不同的ImageNet模型如何影响域自适应问题,并发现高性能的ImageNet模型将为无监督域自适应提供更好的特性。 然而,确定UDA的最佳特性集(从任何来源)还没有探索过。 来自同一深度网络的特性是否能达到最佳性能? 我们通过从16个不同的预先训练的ImageNet模型中探索所有可能的特征配对,使用强化学习来探索这个问题。
,而没有探索其他模型。 正如前面提到的,我们探索了不同的ImageNet模型如何影响域自适应问题,并发现高性能的ImageNet模型将为无监督域自适应提供更好的特性。 然而,确定UDA的最佳特性集(从任何来源)还没有探索过。 来自同一深度网络的特性是否能达到最佳性能? 我们通过从16个不同的预先训练的ImageNet模型中探索所有可能的特征配对,使用强化学习来探索这个问题。
4.2、对抗强化学习
现在,我们通过考虑不同的预训练模型,在强化学习环境中形式化了无监督域适应场景。
由于我们有几个训练良好的ImageNet模型,我们使用第二个特征提取器![]() (我们称之为预训练的特征提取器)来使用预训练的模型表示源和目标图像。 对于给定的特征提取器,我们考虑最大平均偏差(MMD)作为非参数距离测度,通过将数据映射到再生核希尔伯特空间(RKHS)中来比较源域和目标域的分布。 设
(我们称之为预训练的特征提取器)来使用预训练的模型表示源和目标图像。 对于给定的特征提取器,我们考虑最大平均偏差(MMD)作为非参数距离测度,通过将数据映射到再生核希尔伯特空间(RKHS)中来比较源域和目标域的分布。 设![]() 和
和![]() 为源域和目标域的分布。 则
为源域和目标域的分布。 则 ![]() 和
和![]() 为之间的距离可表示为:
为之间的距离可表示为:
![]()
其中![]() 为预训练模型的第
为预训练模型的第![]() 特征提取器(K = 16),
特征提取器(K = 16), ![]() 为通用RKHS,
为通用RKHS,![]() ,比例可以变化。 如图1所示,我们使用t-SNE视图显示来自源域和目标域的一张图像,它们属于同一类。 我们可以发现,这16个特征提取器都代表了相同的图像,但投影位置不同,这说明了不同的
,比例可以变化。 如图1所示,我们使用t-SNE视图显示来自源域和目标域的一张图像,它们属于同一类。 我们可以发现,这16个特征提取器都代表了相同的图像,但投影位置不同,这说明了不同的![]() 的差异。但是我们注意到同一个提取器中的源和目标特征可能不是源和目标之间最接近的特征。 因此,我们的目标是使式(3)中所有经过预先训练的特征提取器之间的距离最小。
的差异。但是我们注意到同一个提取器中的源和目标特征可能不是源和目标之间最接近的特征。 因此,我们的目标是使式(3)中所有经过预先训练的特征提取器之间的距离最小。
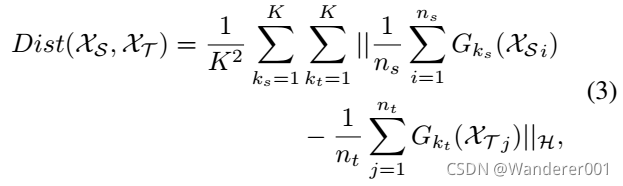
其中![]() 和
和![]() 为预先训练的特征提取器(
为预先训练的特征提取器(![]() )。 因此,对于两个域,我们有很多可能的特征实例,穷举搜索的复杂性为
)。 因此,对于两个域,我们有很多可能的特征实例,穷举搜索的复杂性为![]() 。 我们将RL范式视为特性选择器,它可以为两个领域选择最佳特性。 然而,挑战在于,提取的特征不可避免地有噪声,因为它们是从不同的神经网络中提取的,一些性能较低的预训练模型会导致负迁移,这意味着一些特征是“功能性的”,而不是“信息性的”。 如果选择信息较少的特性,将会影响目标域的性能。
。 我们将RL范式视为特性选择器,它可以为两个领域选择最佳特性。 然而,挑战在于,提取的特征不可避免地有噪声,因为它们是从不同的神经网络中提取的,一些性能较低的预训练模型会导致负迁移,这意味着一些特征是“功能性的”,而不是“信息性的”。 如果选择信息较少的特性,将会影响目标域的性能。
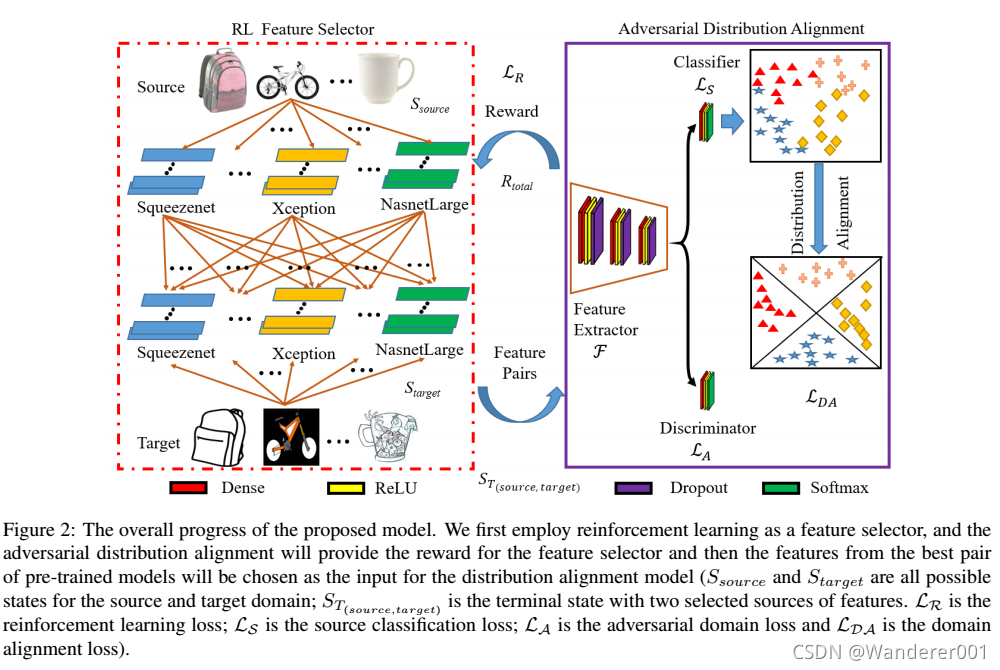
为了解决这个问题,ARL模型学习选择最合适的源-目标特征对,通过他们的能力来优化模型。 如图2所示,我们首先使用RL选择最佳的特征对,然后将它们输入到对抗性域对齐框架中。
我们使用Q-learning算法来选择这两个领域的特征集。Q-learning agent是一种基于价值的强化学习agent,它训练批评者估计回报或未来的回报。强化学习策略是一种映射,它根据对环境的观察选择要采取的行动。 在训练期间,代理调整其策略表示的参数,以最大化长期回报。 状态、行动、奖励和政策梯度的细节描述如下。
状态
状态S表示当前选定的特性。 如图2所示,对于一张图像,我们有K种可能的状态作为特征选择器。 状态![]() 是一个选定的源-目标对,包括两个提取的特征向量:源状态
是一个选定的源-目标对,包括两个提取的特征向量:源状态![]() 和目标状态
和目标状态![]() 。
。
源状态和目标状态表示来自不同的特征提取器:
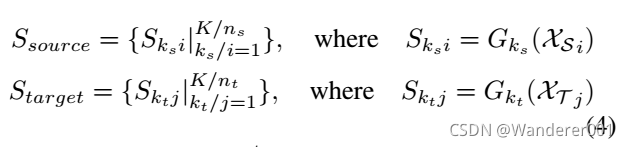
初始状态![]() ,每个特征对的终端状态定义为:
,每个特征对的终端状态定义为:
![]()
因此,我们可以将所有可能的状态定义为一个四分量集:![]() ,其中
,其中![]() ,
, 。 在不失一般性的前提下,对抗性域比对的输入是所有源和目标对的终端状态(
![]() )。
)。
动作
我们定义一个动作![]() 来表示是否选择源特征或目标特征作为对抗性域比对的输入。 行动的数量与状态的数量相同。 agent在时间步长t时所采取的最优行动计算为:
来表示是否选择源特征或目标特征作为对抗性域比对的输入。 行动的数量与状态的数量相同。 agent在时间步长t时所采取的最优行动计算为:
![]()
其中,![]() 是时间步长t中的状态,惩罚
是时间步长t中的状态,惩罚![]() 是采取行动a的累积回报。
是采取行动a的累积回报。
奖赏
奖励功能是一个指示功能,如果功能被选择。 当前模型的难点在于如何为源域和目标域定义适当的奖励。 对于源域,可以考虑训练精度来定义奖励。 对于目标域,我们需要定义一个无监督的奖励;然后我们提出一种深度相关奖励。
深度相关奖赏
我们的特征是从一个训练有素的模型中提取出来的;我们假设两个高度相关的例子应该属于同一个类,如下所示,
![]()
其中![]() 是余弦相似度。 然后对所有相似度评分进行排序,计算目标域的top-1余弦相似度矩阵。 因此,我们可以使用源分类器将相关标签与预测标签进行比较。 目标域中的奖励可以定义为:
是余弦相似度。 然后对所有相似度评分进行排序,计算目标域的top-1余弦相似度矩阵。 因此,我们可以使用源分类器将相关标签与预测标签进行比较。 目标域中的奖励可以定义为:
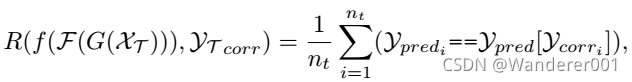
其中![]() 为来自源分类器
为来自源分类器的预测,
![]() 为大小
为大小![]() 的相关标签;它显示了top-1索引,该索引与应该在同一类中的实例高度相关。 因此,奖励衡量的是预测的标签与其最近的邻居有多大的不同。 然后,我们将每一对选中的奖励定义为:
的相关标签;它显示了top-1索引,该索引与应该在同一类中的实例高度相关。 因此,奖励衡量的是预测的标签与其最近的邻居有多大的不同。 然后,我们将每一对选中的奖励定义为:
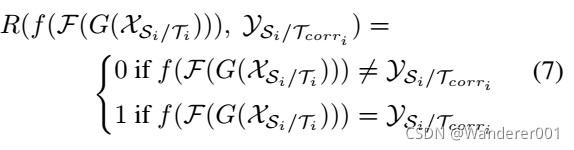
然后我们在式(8)中定义源域和目标域的总奖励。
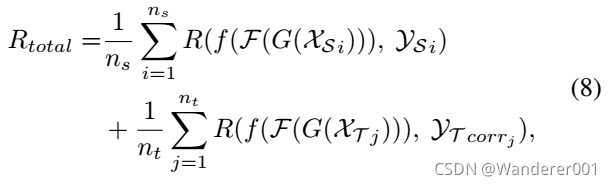
其中![]() 为一个源数据的奖励,一个目标数据的奖励记为
为一个源数据的奖励,一个目标数据的奖励记为![]() 。
。
RL范式的损失函数记为:
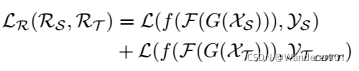
策略梯度:
我们使用标准的策略梯度对状态和行动网络的训练进行奖励。 在所有的![]() 步骤中,它首先计算每个T步骤的累计奖励RT:
步骤中,它首先计算每个T步骤的累计奖励RT:![]() ,其中
,其中![]() 是折中因子。
是折中因子。
我们使用下面的标准策略梯度优化状态和动作的参数。 我们使用下面的标准策略梯度优化状态和动作的参数。

其中![]() 为更新后的目标值,
为更新后的目标值,![]() 为学习率。
为学习率。
4.3、对抗分布对齐学习
在选择每个特征对后,我们首先应用对抗性学习,通过最小化等式1-2中的损失函数来识别区域分布。 然后,我们将两个域的边际分布和条件分布对齐如下。
由Wang等人提出的Manifold Embedded Distribution Alignment (MEDA),将流形学习中的特征对齐。 原始MEDA采用GFK模型学习流形特征,GFK模型是基于SGF模型的。 然而,Zhang等人指出,SGF模型存在缺陷,无法估计子源域和子目标域的测地线。 我们对域对齐损失进行了如下修改:
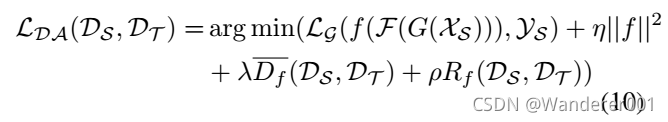
式2中![]() 为源分类器,
为源分类器,![]() 为损失平方和;
为损失平方和;![]() 是f的平方模;而前两项则最大限度地降低了源头的结构性风险。
是f的平方模;而前两项则最大限度地降低了源头的结构性风险。 ![]() 表示动态分布对齐;
表示动态分布对齐; ![]() 是拉普拉斯正则化; η, λ, ρ是正则化参数。 特别地,
是拉普拉斯正则化; η, λ, ρ是正则化参数。 特别地,![]()
![]() ,μ是一种自适应因子平衡的边际分布
,μ是一种自适应因子平衡的边际分布![]() 和条件分布
和条件分布![]() 和
和![]()
![]() 类指标。
类指标。
4.4、整个目标函数
所提出的ARL模型的整体优化问题如式11所示。
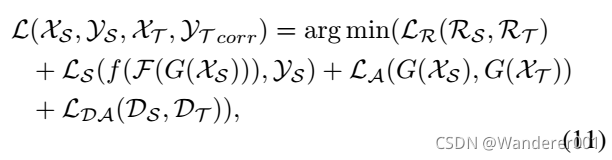
其中![]() 和
和![]() 来自式(1)和式(2),除了输入是从预先训练的模型
来自式(1)和式(2),除了输入是从预先训练的模型![]() 和
和![]() 中提取的特征,而不是原始图像。 我们的ARL模型的详细步骤如算法1所示。
中提取的特征,而不是原始图像。 我们的ARL模型的详细步骤如算法1所示。

5、实验
5.1、数据集
我们使用两个在UDA中广泛使用的基准数据集来评估我们的ARL模型。 我们遵循预先工作[50]协议,从16个预先训练的神经网络(Squeezenet, Alexnet, Googlenet, Shufflenet, Resnet18, Vgg16, Vgg19, Mobilenetv2, Nasnetmobile, Resnet50, Resnet101, Densenet201, Inceptionv3, Xception, Inceptionresnetv2, Nasnetlarge)。 所有提取的特征均来自最后一层全连接层[46],每幅图像的特征大小为1000。
Office + Caltech-10是一个域适配的标准基准,包含Office 10和Caltech 10的数据集。 它由2533张照片在四个领域:Amazon(A),Webcam(W),DSLR(D)和Caltech(C)。C到A表示从C领域学习知识,并应用到A领域。在Office + Caltech-10数据集中有12个迁移任务。
Office-31由来自三个域的31个类的4110张图片组成:Amazon (A),其中包含从amazon.com下载的图片,Webcam (W)和DSLR (D),它们分别包含由网络相机或数码单反相机拍摄的不同设置的图片。 我们评估所有六个转移任务的方法。
Office-Home包含来自四个域的15588张图片,它有65个类别。 具体来说,Art (Ar)表示目标图像的艺术描述,Clipart (Cl)描述剪贴画的图片集合,Product (Pr)显示带有清晰背景的目标图像,类似于Office-31中的Amazon类别,Real-World (Rw)表示用普通相机收集的目标图像。 在这个数据集中也有12个任务。 因此,我们在实验中总共有30个任务。
5.2、实现细节
预训练的骨干网络数量固定(即K = 16)。 我们对Q学习采用![]() -greedy策略,当
-greedy策略,当![]() = 0.9,折扣因子γ = 0.99, numEpochs = 1000,学习率α为1e-3。 稠密层的单位数分别为512、256和128。 Dropout层的速率是0.5。 它以一个密集层结束(单元的数量是每个数据集中的类的数量(在我们的实验中是10和65)。 域分布对准参数η = 0.1, λ = 10, ρ = 10,这些参数是根据前人的研究确定的。
= 0.9,折扣因子γ = 0.99, numEpochs = 1000,学习率α为1e-3。 稠密层的单位数分别为512、256和128。 Dropout层的速率是0.5。 它以一个密集层结束(单元的数量是每个数据集中的类的数量(在我们的实验中是10和65)。 域分布对准参数η = 0.1, λ = 10, ρ = 10,这些参数是根据前人的研究确定的。 ![]() 、γ、α和numEpochs由源畴的性能决定。 利用ARL模型选择特征后,利用对抗性域对齐学习在目标域上生成最终的类预测,并报告其准确性。
、γ、α和numEpochs由源畴的性能决定。 利用ARL模型选择特征后,利用对抗性域对齐学习在目标域上生成最终的类预测,并报告其准确性。
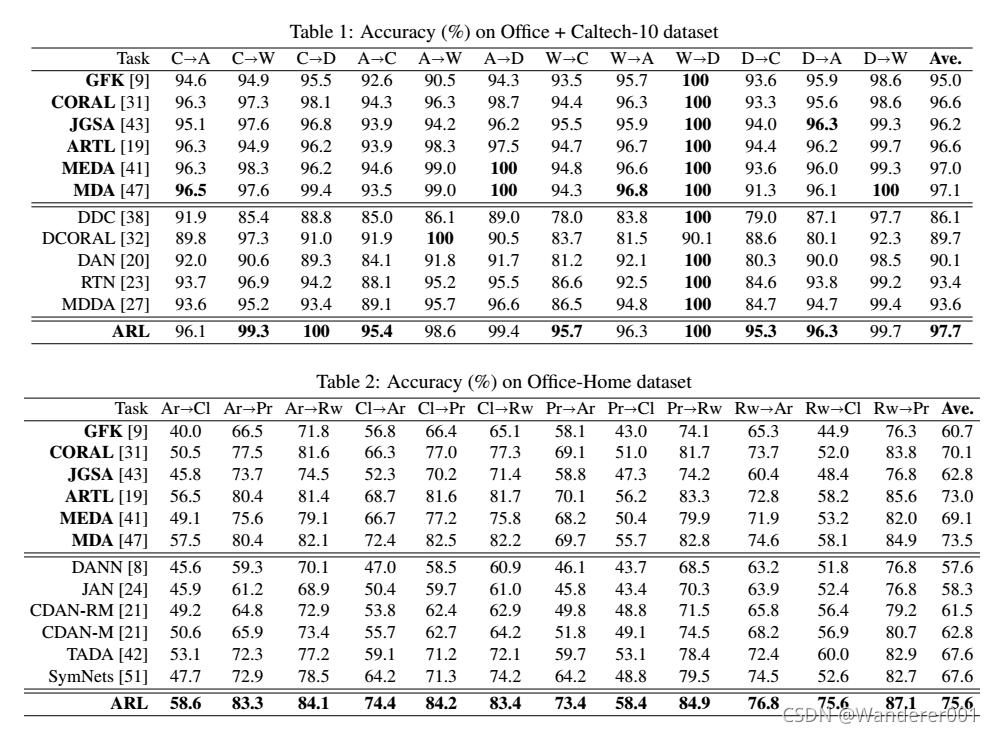
5.3、评估结果
我们还将我们的结果与最先进的方法(包括传统方法和深度神经网络)进行了比较。 Office + Caltech-10、Office-31和Office- home的性能如表1-3所示。 为了进行公平的比较,我们用粗体突出了那些使用我们提取的特征重新实现的方法(我们连接了所有16个深度神经网络特征),其他方法直接从他们的原始论文中报告。 我们注意到,在某些任务中,分类性能可能很低(例如,在Office-31数据集中的WD)。 一个潜在的原因是,与其他方法相比,SymNets和CAN更有可能减少域W和域D之间的差异。 然而,ARL模型比其他模型赢得了更多的任务,并且在平均精度方面优于所有最先进的方法(特别是在Office-Home数据集)。 这证明了RL在UDA的源域和目标域之间选择相似特性的好处。 值得注意的是,我们的ARL模型大大提高了不同数据集的分类精度。

5.4、消融研究
为了更好地展示我们模型的性能,我们在表4中报告了不同损失函数对分类精度的影响。 请注意,我们至少应该维护源分类器(即![]() )来训练源域并在目标域上进行测试。 “
)来训练源域并在目标域上进行测试。 “![]() ”的实现没有强化学习、对抗域损失和分布对齐损失。 它是一个简单的模型,只训练源域而不使域差异最小化。 这也是最糟糕的基线,因为它没有考虑其他损失函数。 “
”的实现没有强化学习、对抗域损失和分布对齐损失。 它是一个简单的模型,只训练源域而不使域差异最小化。 这也是最糟糕的基线,因为它没有考虑其他损失函数。 “![]() ”报告结果不执行额外的对抗域损失和域分布对齐。
”报告结果不执行额外的对抗域损失和域分布对齐。 ![]() 忽略了基于强化学习的特征选择器,减少了基于对抗学习和分布对齐的域差异。 在表4中,所有带有“
忽略了基于强化学习的特征选择器,减少了基于对抗学习和分布对齐的域差异。 在表4中,所有带有“![]() ”的变量都省略了用于特征选择的强化学习,模型使用从预训练的Nasnetlarge模型中提取的最优特征进行训练。 我们观察到,随着附加的损失函数的加入,我们的模型的稳健性不断提高。 此外,包含强化学习的模型的性能优于不包含强化学习的模型。 例如,“
”的变量都省略了用于特征选择的强化学习,模型使用从预训练的Nasnetlarge模型中提取的最优特征进行训练。 我们观察到,随着附加的损失函数的加入,我们的模型的稳健性不断提高。 此外,包含强化学习的模型的性能优于不包含强化学习的模型。 例如,“![]() ”比“
”比“![]() ”和“
”和“![]() ”差。 这意味着使用强化学习的特征选择器对于识别源和目标域最相似的配对特征是强大而重要的。 对抗性学习和领域对齐也进一步提高了分类精度。 因此,我们可以得出结论,这些损失函数中的每一个都是重要的最小化目标域风险。
”差。 这意味着使用强化学习的特征选择器对于识别源和目标域最相似的配对特征是强大而重要的。 对抗性学习和领域对齐也进一步提高了分类精度。 因此,我们可以得出结论,这些损失函数中的每一个都是重要的最小化目标域风险。
6、讨论
在这些广泛的实验中,我们的方法达到了最高的平均精度。 因此,我们的模型的质量超过了最先进的方法。 这一成功有两个突出的原因。 首先,RL从特征空间中发现源和目标之间最接近的特征,从而使两个域之间的差异最小。 其次,本文提出的对抗性学习方法进一步减小了域差异,域分布对齐方法联合对两个域进行对齐。 两个域的条件分布和边际分布,保证了标签空间的一致性。 尽管Office+caltech-10数据集的绝对改善并不大,但它比最佳基线方法减少了20%以上的平均误差。
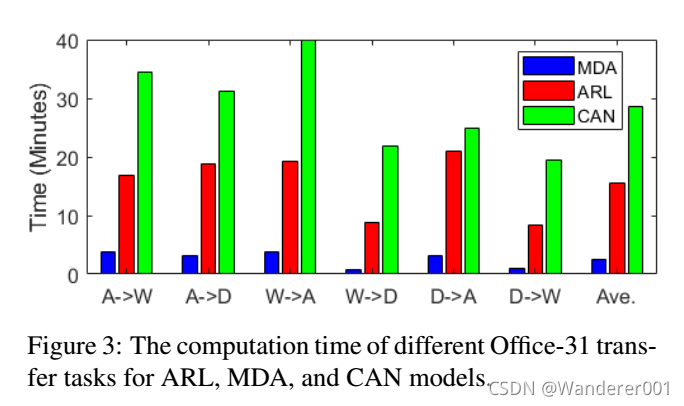
我们的模型的一个挑战是,目标域的奖励不是直接基于真实标签计算的,因为我们没有目标域的基础事实。 一个更好的目标领域的无监督奖励功能可能会提高性能。 虽然我们从16个不同的预先训练的ImageNet模型中提取特征,但这些特征一旦被提取出来就固定了,在模型训练期间不需要重新提取,这意味着特征提取的成本是固定的。 在我们的模型中,RL范式消耗了主要的计算时间。 如图3所示,我们将Office-31数据集上6个迁移任务的计算时间与最优传统方法MDA和最优基于深度学习的方法CAN进行比较。 由于MDA模型不需要寻找最佳特征对,因此ARL模型比MDA模型使用了更多的计算时间。 同时,由于CAN模型需要更多的时间对所有原始图像进行重新训练,所以我们的模型比CAN模型所需的时间更少,并且达到了最高的精度。 因此,我们的模型可以在合理的计算时间下获得更高的性能。

What can we learn from the ARL model?
ARL模型采用强化学习范式,从16个预先训练的ImageNet模型中探索所有可能的特征配对。 大量的实验表明,RL在寻找源域和目标域之间的最佳特征对方面是有效的,并且优于所有其他基线方法。 如第4.1节所述,来自相同深度网络的特性是否能获得最佳性能? 答案是“不”。 令人惊讶的是,我们发现来自同一深度网络的特性并没有在UDA中产生最佳性能。 在大多数任务中,最佳配对是“Xception?” Nasnetlarge的意思是用Xception特征训练模型,然后将模型应用到Nasnetlarge特征中得到最好的结果。 一个可能的原因是,Xception和Nasnetlarge特性之间的差异比其他组合要小。 因此,在排除复杂RL框架的情况下,我们建议源域使用Xception模型作为特征提取器,目标域使用Nasnetlarge模型来提高分类精度。
7、结论
本文通过强化学习选择特征。 在确定源和目标域最相似的特征集之后,我们利用对抗学习进一步减少源和目标的差异。 此外,我们对两个领域的联合分布进行对齐,以获得最高的分类精度。 大量的实验表明,所提出的ARL模型优于目前最先进的域适配方法。