ES读写原理详解和hive推送ES案例
一、ES使用场景
Elasticsearch是面向文档(document oriented)的分布式数据库,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
1.1 存储数据(基础)
es天然支持分布式,具备存储海量数据的能力,其搜索和数据分析的功能都建立在es存储的海量的数据之上。例如:围绕Elasticsearch构建的生态系统使其成为最容易实施和扩展日志记录解决方案之一。
1.2 搜索(核心能力)
es使用倒排索引,每个字段都被索引且可用于搜索,更是提供了丰富的搜索api,在海量数据下近实时实现近秒级的响应。例如:(1)电商网站,检索商品;(2)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
1.3 数据分析和可视化(核心能力)
除了对搜索的支持,es也提供了大量数据分析的api,为es提供了数据分析的能力 。凭借大量的图表选项,地理数据的平铺服务和时间序列数据的TimeLion,Kibana是一款功能强大且易于使用的可视化工具。对于上面的每个用例,Kibana都会处理一些可视化组件。
二、ES的原理
2.1 ES如何实现分布式?
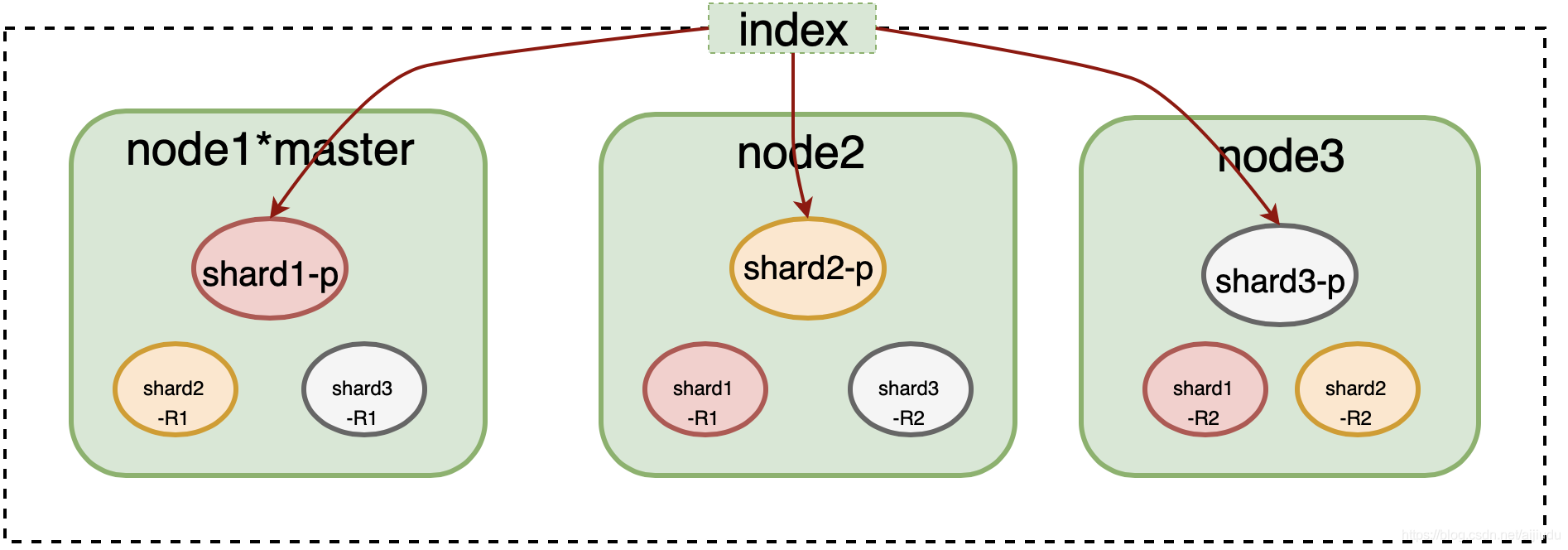
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。
master节点 (1)管理ES集群中的元数据:比如说索引的创建和索引的删除,维护索引元数据;节点的增加和移除,维护集群的元数据。
(2)默认情况下,会自动选择出一台节点作为master节点。
注意:master节点不承载所有的请求,所以不会是一个单点瓶颈。(这句话的意思是说并不是因为他是master节点,所以所有请求都由他来转发,而是每个节点都有可能被请求到。)
2.2 ES读写数据的原理
2.2.1 写入相关的几个问题
问题1:任务hive2es,多任务推送ES速度会快么?
答:不会,假如任务索引文档 id0 有三个字段 F1、F2、F3。
|
taskA一个任务推动 |
taskB、taskC俩任务推送 |
||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
taskA的id0包括:F1、F2、F3字段 insert doc_id为id0的数据到ES
|
taskB的id0包括:F1、F2字段先到,taskC的id0包含F3字段 后到。
taskC任务的id0到了,update id0(查找更新)
|
问题2:ES的doc_id是怎么产生的
答:手动指定和自动生成,自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突。
|
任务元数据 |
元数据(metadata) |
||||||||
|---|---|---|---|---|---|---|---|---|---|
|
doc_id 是手动指定的X_id
|
文档通过其_index、_type、_id唯一确定
|

问题3:如何提高hive2es推送的效率
答:ES采用多Shard方式,可以适当增加shard个数。
|
任务索引管理 |
ES索引 |
|---|---|
|
任务有14 shard,可以通过提高shard的个数来加快推送速度 ,单也需要平衡前端查询效率。 |
在Elasticsearch中存储数据的行为就叫做索引(indexing),在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中。
实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”。
在Elasticsearch中,每一个字段的数据都是默认被索引的。也就是说,每个字段专门有一个反向索引用于快速检索。而且,与其它数据库不同,它可以在同一个查询中利用所有的这些反向索引,以惊人的速度返回结果。 |
问题4:Shard设置多少合适?
shard大小和个数是影响Elasticsearch集群稳定性和性能的重要因素之一。Elasticsearch集群中任何一个索引都需要有一个合理的shard规划(默认为5个)。
适当的提升分片数量可以提升建立索引的速度(任务推送的速度);如果分片过少或者过多,都会降低检索的速度。分片数过多会导致:(1)会导致打开比较多的文件(2)分片是存储在不同机器上的,分片数越多,机器之间的交互也就越多;分片数太少导致:单个分片索引过大,降低整体的检索速率。
Shard数量如何预估:
1、每个数据节点上都尽量分配某个索引的一个分片,使数据足够均匀。(shard的个数(包括副本)要尽可能匹配数据节点数,等于数据节点数,或者是节点数的整数倍,比如集群单中心的数据节点有10个,那么分片最佳分片数建议为10,保证每个节点上都均分一个分片。)
2、每个索引分片不要超过30G
3、单节点数据控制再2T以内
4、单索引size小于1g的,主分片数量不得大于5
5、单集群索引数量不得大于3k
6、单集群(总)分片数量不得大于10w
2.2.2 写入过程
每个Index由多个Shard组成,每个Shard有一个主节点和多个副本节点,副本个数可配。Elasticsearch文档写入主要是写主分片和写副本分片。所以副本分片的个数就直接决定了写入的性能。合理配置副本数,在性能和安全之间取得平衡。
-
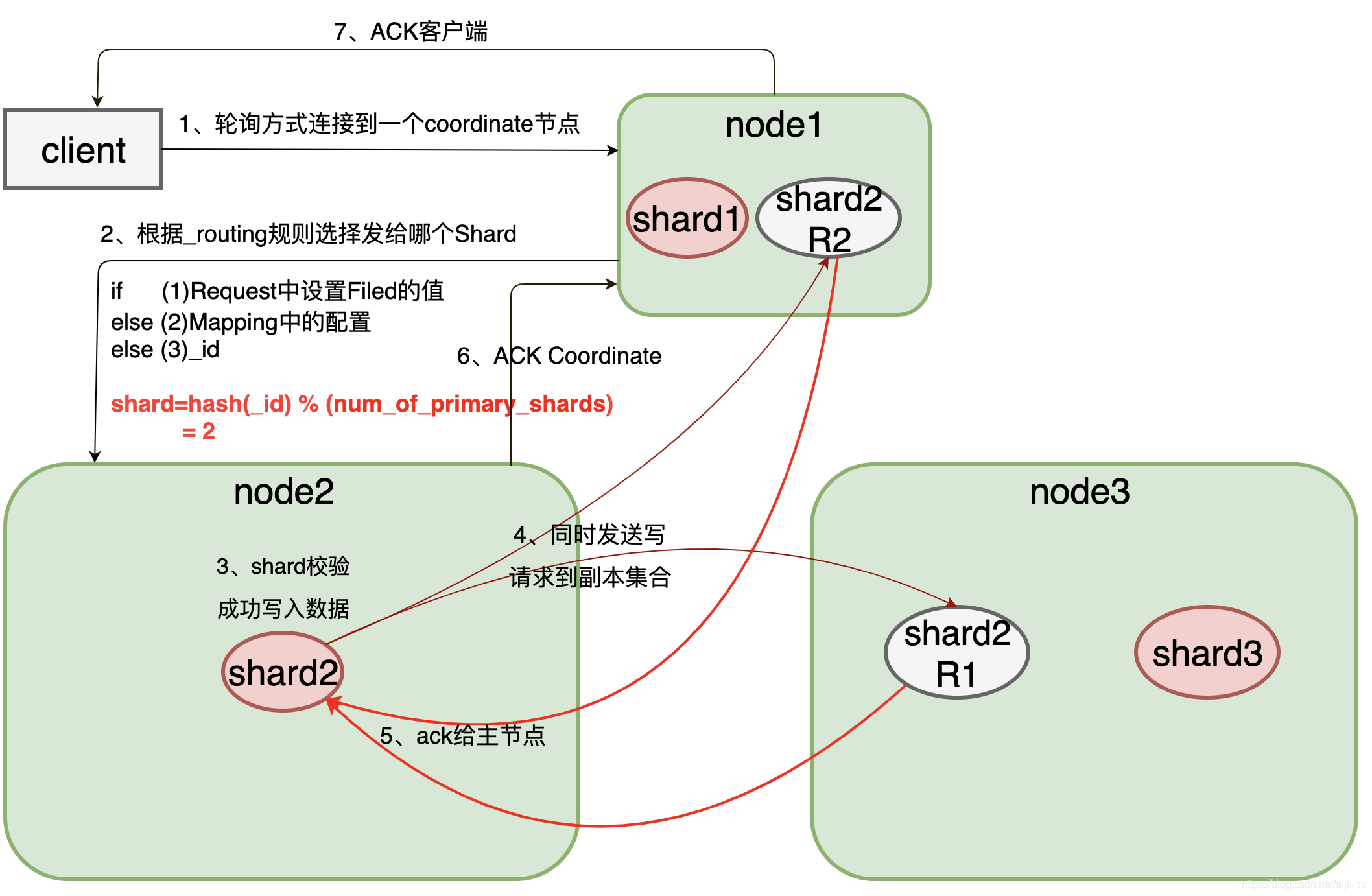
首先客户端根据配置的连接节点,通过轮询方式连接到一个coordinate节点(协调节点)发送请求过去。(coordinate节点不是master/client/data节点一个维度的描述,它就是指处理客户端请求的节点,集群中所有的节点都可以是coordinate节点。)
-
每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard(在OperationRouting类中),如图所示通过hash算法计算出数据在shard2上shard = hash(_id) % (num_of_primary_shards),然后从集群的Meta中找出出该Shard的Primary节点,将请求发送到node2上。
-
Node2节点的Primary Shard上执行成功后(写失败如何处理:写入是不支持事务的,推荐使用自定义文档 id 的方式,这样当某个操作失败时,重新执行这整个操作即可,ES 会根据 ID 进行自动覆盖,不会出现数据重复),再从Primary Shard上将请求同时发送给多个Replica Shard,将数据并行发送到副本集节点Node1上shard2的副本2和Node3上shard2的副本1。(副本不可达如何处理:写请求到达主分片的时候,集群会通过元数据信息获取到所有副本分片的位置,然后并行转发请求,若是某些原因导致,某个分片副本不可达,主分片就会通知master让master将这个分片从同步副本组中删除,然后返回客户端一个确认操作,就表示数据已经成功,然后master会指导另一个节点建立一个新的同步分片,以保证分片副本个数的一致性。 )
-
Node1,Node3上的副本写入数据成功后,发送ack信号给shard2主节点Node2。
-
Node2发送ack给coordinate node
-
coordinate node发送ack给客户端。
2.2.3 写入shard
-
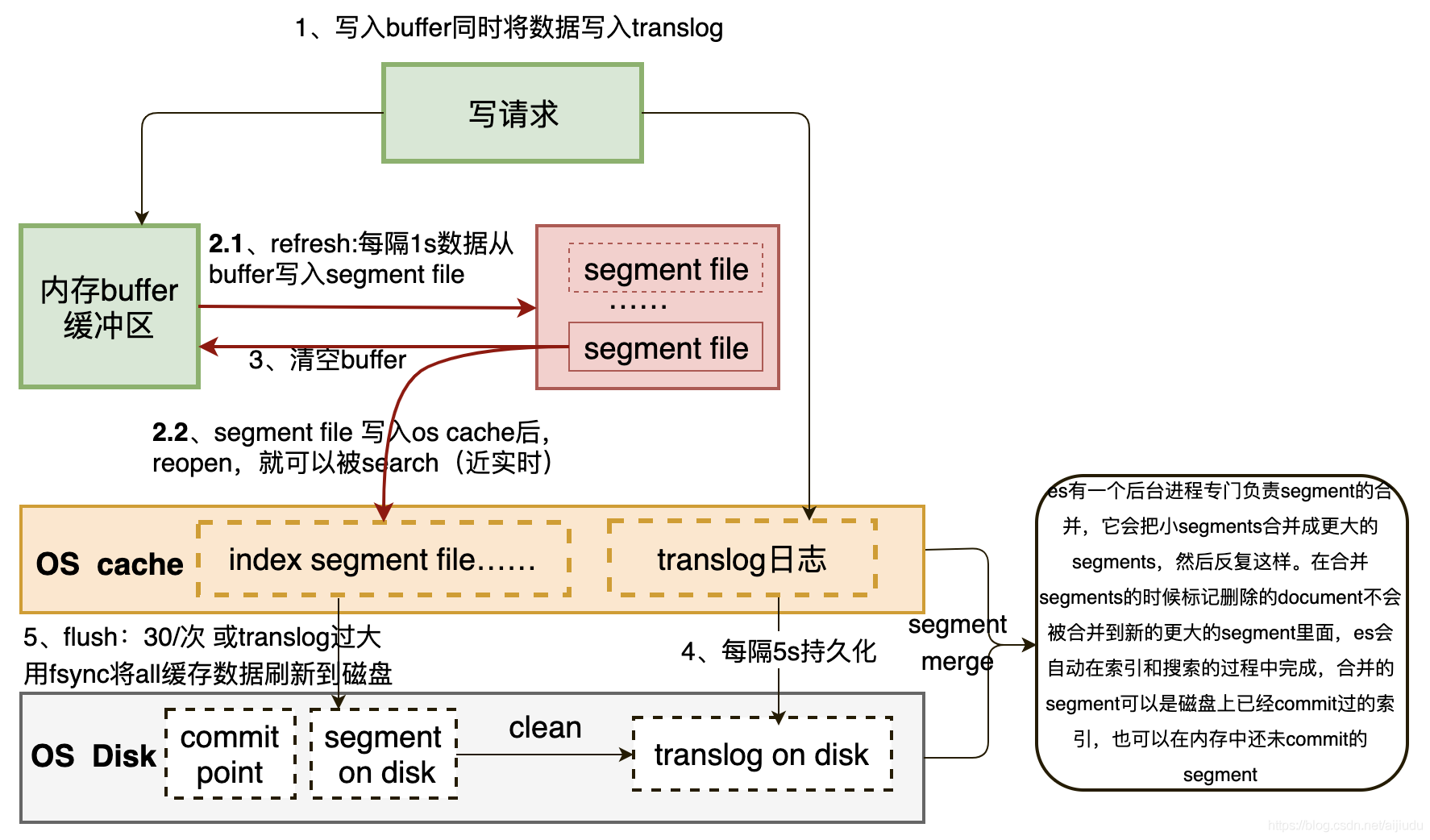
先写入buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件(translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中)
-
每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,这个过程就是refresh。此时segment被打开并供search使用,search请求就可以搜索在os cache 中的index segment file。(segment file: 存储逆向索引的文件,每个segment本质上就是一个逆向索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除。)
-
buffer被清空
-
重复1~3步骤,新的数据不断进入buffer和translog,不断将buffer数据写入一个又一个新的segment file中去,每次refresh完buffer清空,translog保留。随着这个过程推进,translog会变得越来越大。
-
默认每隔30分钟会自动执行一次commit,但是如果translog过大,也会触发commit。commit操作:1、写commit point;2、将os cache数据fsync强刷到磁盘上去;3、清空translog日志文件(整个commit的过程,叫做flush操作。我们可以手动执行flush操作,就是将os cache中的数据fsync强刷到磁盘上去,记录一个commit point,清空translog日志文件。)
(1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使
(2)buffer被清空
(3)将一个commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file(commit point: 记录当前所有可用的segment,每个commit point都会维护一个.del文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉)
(4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
(5)现有的translog被清空,创建一个新的translog
注意:缓存中的数据默认1秒之后才生成segment文件,即使是生成了segment文件,这个segment是写到页面缓存中的,并不是实时的写到磁盘,只有达到一定时间或者达到一定的量才会强制flush磁盘。如果这期间机器宕掉,内存中的数据就丢了。如果发生这种情况,内存中的数据是可以从TransLog中进行恢复的,TransLog默认是每5秒都会刷新一次磁盘。但这依然不能保证数据安全,因为仍然有可能最多丢失TransLog中5秒的数据。这里可以通过配置增加TransLog刷磁盘的频率来增加数据可靠性,最小可配置100ms,但不建议这么做,因为这会对性能有非常大的影响。一般情况下,Elasticsearch是通过副本机制来解决这一问题的。即使主分片所在节点宕机,丢失了5秒数据,依然是可以通过副本来进行恢复的。
2.2.4 merge策略
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
index.merge.policy.floor_segment 默认 2MB,小于这个大小的 segment,优先被归并。
index.merge.policy.max_merge_at_once 默认一次最多归并 10 个 segment
index.merge.policy.max_merge_at_once_explicit 默认 forcemerge 时一次最多归并 30 个 segment。
index.merge.policy.max_merged_segment 默认 5 GB,大于这个大小的
segment,不用参与归并。forcemerge 除外。
2.2.5 写入索引配置建议
-
bulk写入,但是要控制写入的量,一次性不能过多,尽量先压测,建议每批提交5-15M的数据
-
尽量使用es自动生成的document id,
-
增加refresh间隔,如果在写入期间对实时性要求不高,可以增加refresh的间隔
PUT /twitter/_settings { "index" : { "refresh_interval" : "1s" } } -
写入期间将副本数设置为0,写完后再修改副数可以提高写入效率
-
适当增加index buffer的值,如上图,写入期间,数据会先缓存在index buffer中,然后再定期flush到磁盘,所以适当增加这个buffer得值,也能提高写入效率,indices.memory.index_buffer_size:15%,该值在elasticsearch.yml中设置
-
副本数量不建议太大,因为写入数据后,主分片要同步数据至副本会消耗大量IO,影响写的性能。
-
trnslog改成异步:translog的作用是用于恢复数据,数据在被索引之前会被先加入至translog中,默认情况下translog是每写一次就刷盘一次,可以改成异步刷新。
PUT /my_index/_settings { "index.translog.durability": "async", "index.translog.sync_interval": "5s" }
2.2.6 存储目录结构
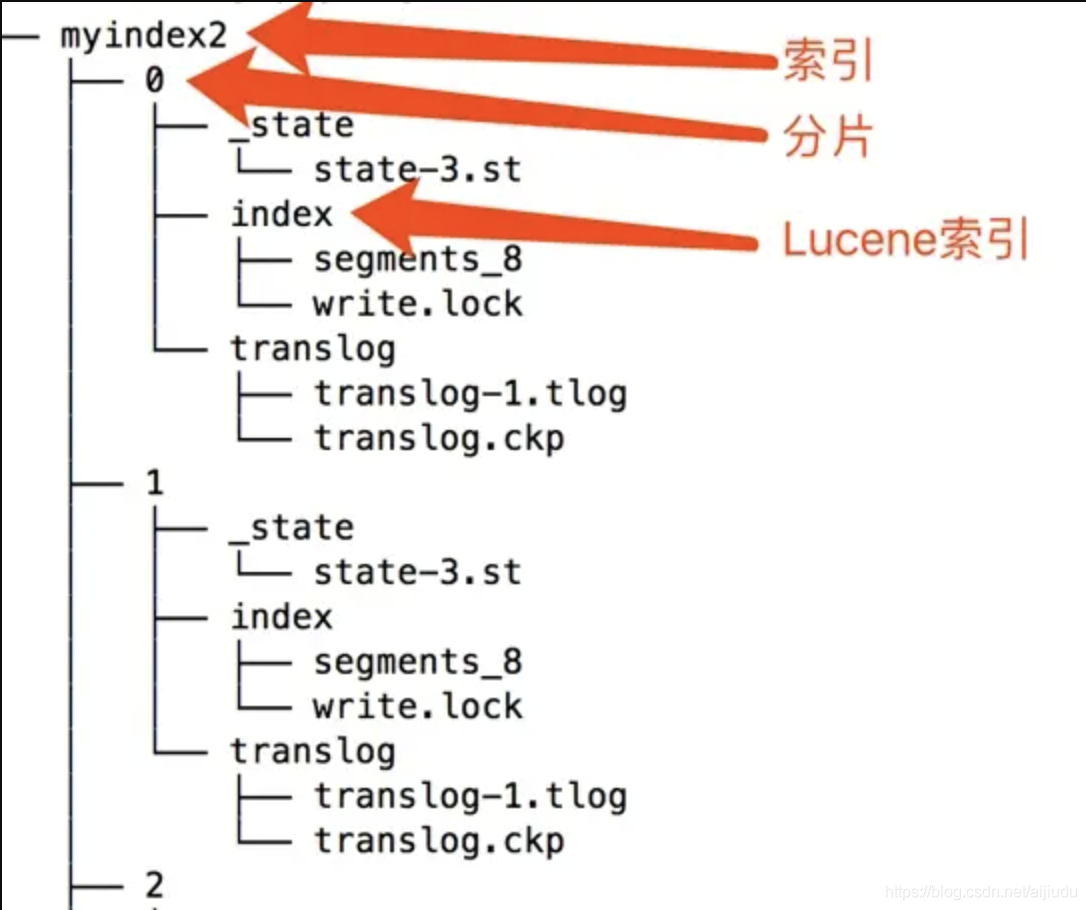
 2.2.7 Elasticsearch的写入流程主要可分为几大特性
2.2.7 Elasticsearch的写入流程主要可分为几大特性
-
可靠性,通过Replica和TransLog两套机制保证数据的可靠性
-
一致性,Lucene中的Flush锁只保证Update接口里面Delete和Add中间不会Flush,但无法保证主分片与副本分片一致。因为如果add之后立即flush,这个时候segment是主分片可见的,但副本分片要落后于主分片。不过最终都会一致。
-
原子性,Add和Delete具有原子性。当部分更新时,使用Version和锁保证更新是原子的
-
实时性,Flush之后的segment对用户可见,最快可配置100ms,可实现near-real-time。特定的查询,直接查TransLog,可实现real-time。
-
隔离性:仍然采用Version和局部锁来保证更新的是特定版本的数据。
-
性能,在很多地方的设计都考虑到了性能
-
不需要所有Replica都返回后才能返回给用户,只需要返回特定数目的就行.
-
生成的Segment现在内存中提供服务,等一段时间后才刷新到磁盘,Segment在内存这段时间的可靠性由TransLog保证.
-
TransLog可以配置为周期性的Flush,但这个会给可靠性带来伤害.
-
每个线程持有一个Segment,多线程时相互不影响,相互独立,性能更好.
-
系统的写入流程对版本依赖较重,读取频率较高,因此采用了versionMap,减少热点数据的多次磁盘IO开销。
2.2.8 ES读取数据的过程
查询,GET某一条数据,写入了某个document,这个document会自动给你分配一个全局唯一的id,doc id,同时也是根据doc id进行hash路由到对应的primary shard上面去。也可以手动指定doc id,比如用订单id,用户id。
你可以通过doc id来查询,会根据doc id进行hash,判断出来当时把doc id分配到了哪个shard上面去,从那个shard去查询
-
客户端发送请求到任意一个node,成为coordinate node
-
coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
-
接收请求的node返回document给coordinate node
-
coordinate node返回document给客户端
2.3 ES数据更新
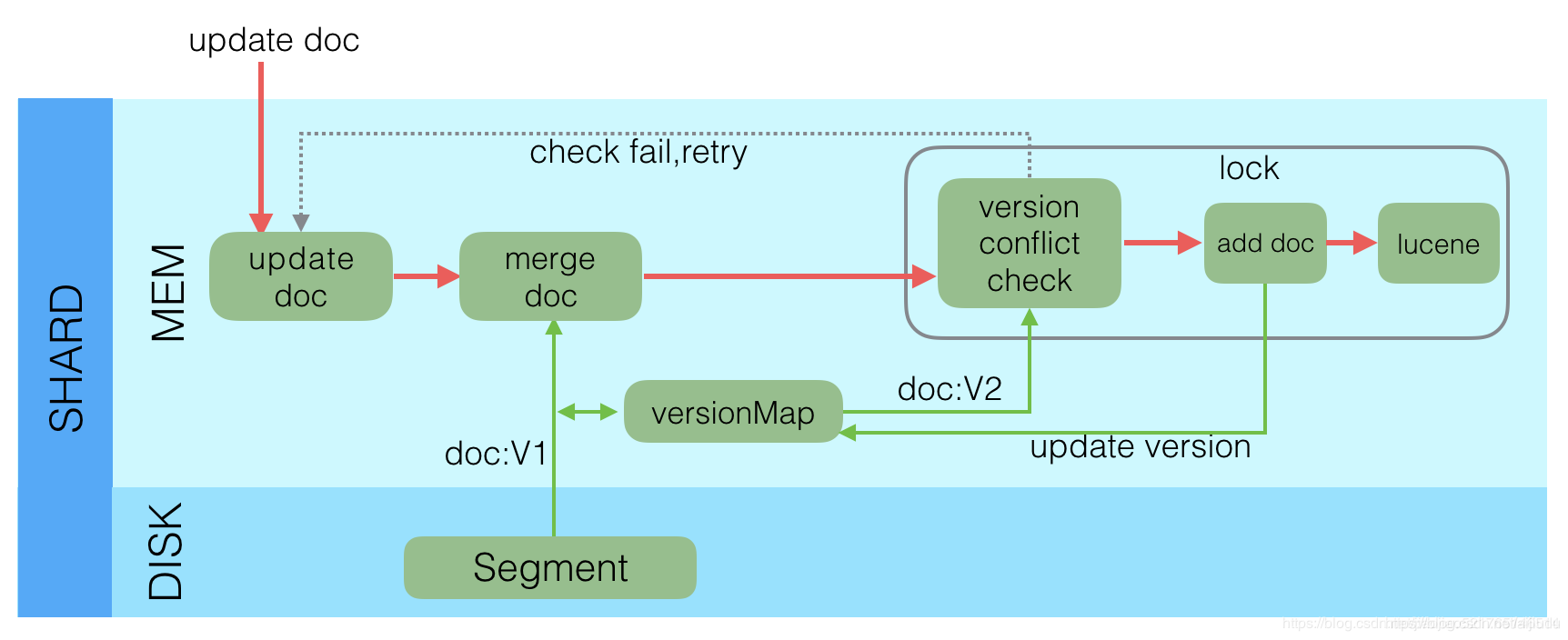
Lucene中不支持部分字段的Update,所以需要在Elasticsearch中实现该功能,具体流程如下:
-
收到Update请求后,从Segment或者TransLog中读取同id的完整Doc,记录版本号为V1。
-
将版本V1的全量Doc和请求中的部分字段Doc合并为一个完整的Doc,同时更新内存中的VersionMap。获取到完整Doc后,Update请求就变成了Index请求。
-
加锁。
-
再次从versionMap中读取该id的最大版本号V2,如果versionMap中没有,则从Segment或者TransLog中读取,这里基本都会从versionMap中获取到。
-
检查版本是否冲突(V1==V2),如果冲突,则回退到开始的“Update doc”阶段,重新执行。如果不冲突,则执行最新的Add请求。
-
在Index Doc阶段,首先将Version + 1得到V3,再将Doc加入到Lucene中去,Lucene中会先删同id下的已存在doc id,然后再增加新Doc。写入Lucene成功后,将当前V3更新到versionMap中。
-
释放锁,部分更新的流程就结束了。
2.4 Elasticsearch是如何做到快速索引的
2.4.1 什么是倒排索引?
数据写入 ES 时,数据将会通过 分词 被切分为不同的 term,ES 将 term 与其对应的文档列表建立一种映射关系,这种结构就是 倒排索引
ES如何建立索引
| ID | Name | Age | Sex |
| -- |:------------:| -----:| -----:|
| 1 | Kate | 24 | Female
| 2 | John | 24 | Male
| 3 | Bill | 29 | MaleID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Posting List:Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
Name:
| Term | Posting List |
| -- |:----:|
| Kate | 1 |
| John | 2 |
| Bill | 3 |Age:
| Term | Posting List |
| -- |:----:|
| 24 | [1,2] |
| 29 | 3 |Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
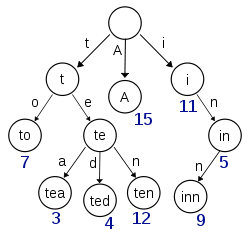
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
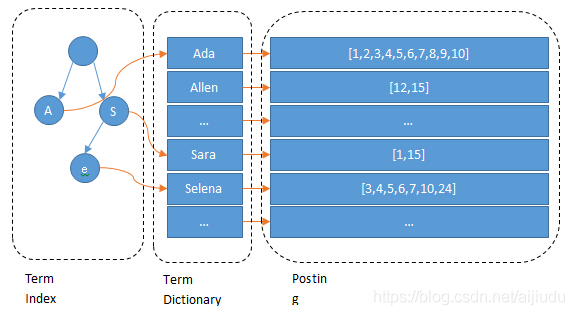
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
2.4.2 使用索引注意事项
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
对于使用Elasticsearch进行索引时需要注意:
-
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
-
同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
-
选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
三、Hive推ES实例
3.1 添加elasticsearch-hadoop-hive***.jar到Hive。Hive添加第三方包
3.2 在hive中建立Elasticsearch表:es_user
CREATE EXTERNAL TABLE es_user (
id String,
NAME String,
age INT,
create_date String
)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES(
'es.nodes' = '192.168.1.57:9200,192.168.1.57:9200',
'es.index.auto.create' = 'true',
'es.resource' = 'dim_use_year_index/dim_use_year_type',
'es.mapping.id' = 'use_year_code',
'es.mapping.names' = 'id:id,name:name, age:age',
'es.write.operation'='upsert'
);es.nodes表示es的节点,多个用“,”分开;
es.index.auto.create表示如果索引不存在自动创建;
es.resource表示指定的索引和类型;
es.mapping.id表示es的_id对应的字段;
es.mapping.names表示其他字段的对应(可以不写,插入时按顺序依次对应即可);
es.write.operation表示如果id重复就更新数据;
3.3 创建hive表:hive_user并且load数据在hive表
CREATE TABLE IF NOT EXISTS hive_user(
id String ,
name String ,
age int
) PARTITIONED BY (create_date String)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;3.4 将Hive表的数据插入到Elasticsearch
INSERT OVERWRITE TABLE es_user SELECT s.id,
s.name,
s.age,
s.create_date
FROM hive_user s
where s.create_date='2015-12-22'四、ES简单算子介绍
本节主要介绍一些简单的查询API,如果Query查询和filter查询存在相似的会放在一起比对介绍。
| 查询类型 |
说明 |
Query查询 |
备注 |
|---|---|---|---|
| Query查询 |
Match All Query 查询所有的数据,相当于不带条件查询。 |
{ { |
查询时,你会发现无论数据量有多大,每次最多只能查到10条数据。这是因为ES服务端默认对查询结果做了分页处理,每页默认的大小为10。如果想自己指定查询的数据,可使用from和size字段,并且按指定的字段排序。 注意:不要把from设得过大(超过10000),否则会导致ES服务端因频繁GC而无法正常提供服务。实际项目中也没有谁会翻那么多页,但是为了ES的可用性,务必要对分页查询的页码做一定的限制。 |
| Query查询 |
Ids Query id字段查询。 |
{ "query": { "ids": { "type": "portrait", "values": [ 11113751, 10409 ] } } } |
查询type是portrait 主键是11113751和10409的记录 |
| Query查询 |
Wildcard Query 通配符查询,是简化的正则表达式查询,包括下面两类通配符:
|
{ "query": { "wildcard": { "rider_name": "*云*" } } } |
查询骑手姓名中包含 云字的 |
| Query查询 |
term query 词语查询,如果是对未分词的字段进行查询,则表示精确查询。 |
{ "query": { "term": { "test_id": 10409 } } } |
查询test_id是10409的记录 |
| Filter查询 |
Term Filter 词语查询,如果是对未分词的字段进行查询,则表示精确查询。 filter查询方式都可以通过设置_cache为true来缓存数据。如果下一次恰好以相同的查询条件进行查询并且该缓存没有过期,就可以直接从缓存中读取数据,这样就大大加快的查询速度。 |
{ |
// 与query主要是这里的区别,可以设置数据 |
| Query查询 |
Bool Query Bool(布尔)查询是一种复合型查询,它可以结合多个其他的查询条件。主要有3类逻辑查询: must:查询结果必须符合该查询条件(列表)。 should:类似于in的查询条件。如果bool查询中不包含must查询,那么should默认表示必须符合查询列表中的一个或多个查询条件。 must_not:查询结果必须不符合查询条件(列表)。 |
{ "query": { "bool": { "must": [{ "term": { "city_id": 110100 } }, { "term": { "name": "李凌云10409" } }] } } } |
查询城市是110100且name是李凌云10409的记录 |
| Filter查询 | Bool Filter |
{ { |
查询城市是110100且name是李凌云10409的记录 |
| Query查询 |
Prefix Query 前缀查询。 |
{ "query": { "prefix": { "born_province": "江" } } } |
查询born_province字段前缀是“江”的记录 |
| Filter查询 |
Prefix Filter 前缀查询。 |
{ |
查询born_province字段前缀是“江”的记录 |
| Query查询 |
Range Query 范围查询,针对date和number类型的数据。 |
{ "query": { "range": { "age": { "gte": 10, "lte": 40, "boost": 2.0 } } } } |
实际上,对于date类型的数据,ES中以其时间戳(长整形)的形式存放的。 测试发现查询语句中写//注释 影响查询结果 gte: 大于或等于 gt: 大于 lte: 小于或等于 lt: 小于 boost: 设置查询的提升值,默认为1.0 |
| Filter查询 |
Range Filter 范围查询,针对date和number类型的数据。 |
{ "filter": { "range": { "age": { "gte": "18", "lte": "20" } } } } |
|
| Query查询 |
Terms Query 多词语查询,查找符合词语列表的数据。如果要查询的字段索引为not_analyzed类型,则terms查询非常类似于关系型数据库中的in查询。 |
{ "query": { "terms": { "test_id": [ 10409, 10086 ] } } } |
查询test_id 是 10409和10086的数据 |
| Filter查询 |
Terms Filter 多词语查询,查找符合词语列表的数据。如果要查询的字段索引为not_analyzed类型,则terms查询非常类似于关系型数据库中的in查询。 |
{ "filter": { "terms": { "test_id": [ 10409, 10086 ] } } } |
查询test_id 是 10409和10086的数据 |
| Query查询 |
Regexp Query 正则表达式查询,这是最灵活的字符串类型字段查询方式。 |
{ "query": { "regexp": { "name": ".*梅众.*" } } } |
查询name中间有梅众两个字的人 .号表示任意一个字符 |
| Filter查询 |
Regexp Filter 正则表达式查询,是最灵活的字符串类型字段查询方式。 |
{ "filter": { "regexp": { "org_name": ".*梅众.*" } } } |
查询name中间有梅众两个字的人 |
| Filter查询 |
And Filter And逻辑连接查询,连接1个或1个以上查询条件。它与bool查询中的must查询非常相似。实际上,and查询可以转化为对应的bool查询。 |
{ { |
|
| Filter查询 |
Or Filter Or连接查询,表示逻辑或。 |
{ "filter": { "or": [ { "term": { "classNo": "2" } }, { "term": { "isLeader": "true" } } ] } } |
查找2班或者是班干部的学生名单,查询结果为学号为1、2、5、8的学生。 |
| Filter查询 |
Exists Filter 存在查询,查询指定字段至少包含一个非null值的数据。如果字段索引为not_analyzed类型,则查询sql中的is not null查询方式。 |
{ "filter": { "exists": { "field": "address" } } } |
查询地址存在学生,查询结果为除了6之外的所有学生。 |
| Filter查询 |
Missing Filter 缺失值查询,与Exists查询正好相反。 |
{ "filter": { "missing": { "field": "address" } } } |
查询地址不存在的学生,查询结果为学号为6的学生。 |