mysql百万级数据limit查询慢问题
先建个简单表,造点数据
CREATE TABLE `mq_msg` (
`id` bigint NOT NULL,
`msg_id` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '业务消息id',
`title` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`content` varchar(1024) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '消息内容',
`create_time` timestamp NULL DEFAULT NULL COMMENT '创建时间',
`status` int NOT NULL DEFAULT '0' COMMENT '(0:未消费 1:已消费 2:异常未消费)',
`compensate_consume_time` timestamp NULL DEFAULT NULL COMMENT '消息补偿消费时间',
`hot` int DEFAULT '0' COMMENT '热度',
PRIMARY KEY (`id`),
KEY `hot` (`hot`),
KEY `create_time` (`create_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='mq消息表';
这里我造数据为了更快些,用多线程来造,使用30个线程生产数据放到redis里面,然后用50个线程去监听消费redis队列,insert到mysql
生产者代码:
@PostMapping("listLeftAdd")
public ResultData listLeftAdd(String value){
for (int j = 0; j < 30 ; j++) {
new Thread(new threadNum(j)).start();
}
return ResultData.success();
}
class threadNum implements Runnable{
private int num;
threadNum ( int num){
this.num = num;
}
@Override
public void run() {
for (int i = 0; i < 20000; i++) {
String msg = "第"+ num +"个线程的第"+i+"个值"+ LocalDateTime.now().toString();
lettucePoolSentinelOperateListService.listLeftAdd(RedisLettuceSentinelController.LIST_QUEUE,msg);
System.out.println(msg);
}
}
}
消费者代码(消费者用批量新增效率会更高,这里只用到了单条插入,赖得了,哈哈):
@Order(1)
@Component
public class ApplicationRunner implements CommandLineRunner {
@Autowired
private MqMsgMapper mqMsgMapper;
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Override
public void run(String... args) throws Exception {
//消费队列信息
for (int i = 1; i < 51; i++){
new Thread(new ConsumerThread(i)).start();
}
System.out.println("main thread end");
}
class ConsumerThread implements Runnable{
private int consumerNum;
ConsumerThread(int consumerNum){
this.consumerNum = consumerNum;
}
@Override
public void run() {
System.out.println("消费线程"+consumerNum+"开始监听list");
while (true){
try {
if(redisTemplate.opsForList().size(RedisLettuceSentinelController.LIST_QUEUE) > 0){
Object m = redisTemplate.opsForList().rightPop(RedisLettuceSentinelController.LIST_QUEUE);
if(m != null){
String message = "消费线程"+consumerNum+"开始消费消息:"+ m;
System.out.println(message);
MqMsg mqMsg = new MqMsg();
mqMsg.setMsgId(UUID.randomUUID().toString());
mqMsg.setContent(message);
mqMsg.setTitle("消费redis队列:"+message);
mqMsg.setStatus(1);
mqMsg.setCreateTime(LocalDateTime.now());
mqMsg.setHot(new Random().nextInt(10000000));
mqMsgMapper.insert(mqMsg);
}
}
}catch (Exception e){
continue;
}
}
}
}
}
插入150多万也要半个多小时
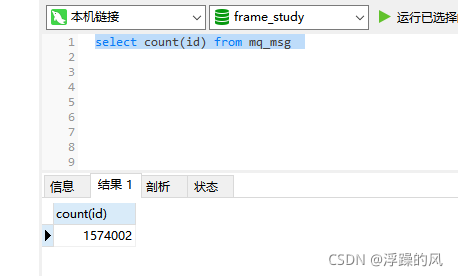
建表时在hot字段和create_time字段都建了索引,现在试查询排序后的第10000页的10条信息
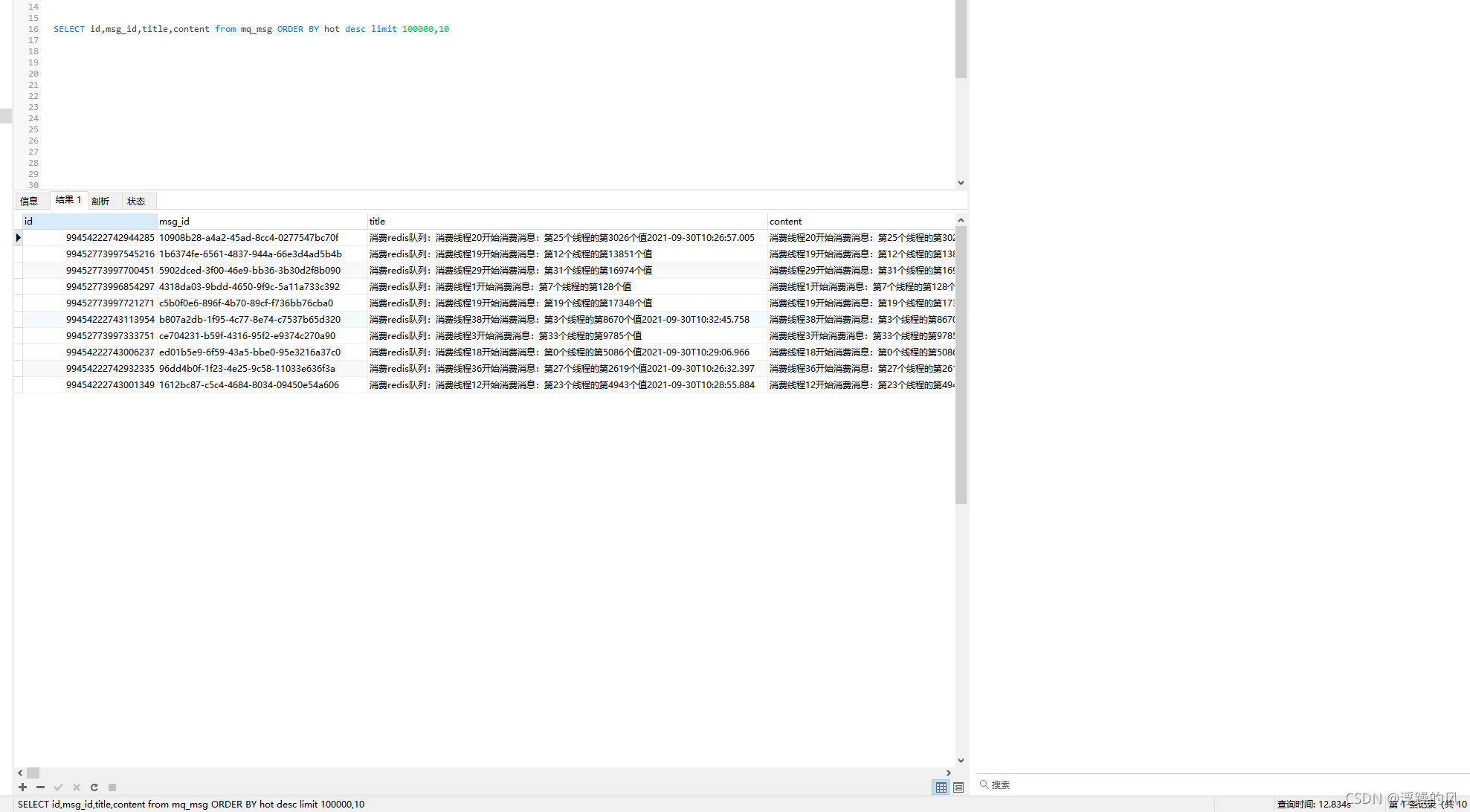
要12秒多,优化一下查询语句,因为mysql不支持子查询使用limit,所以再套一层
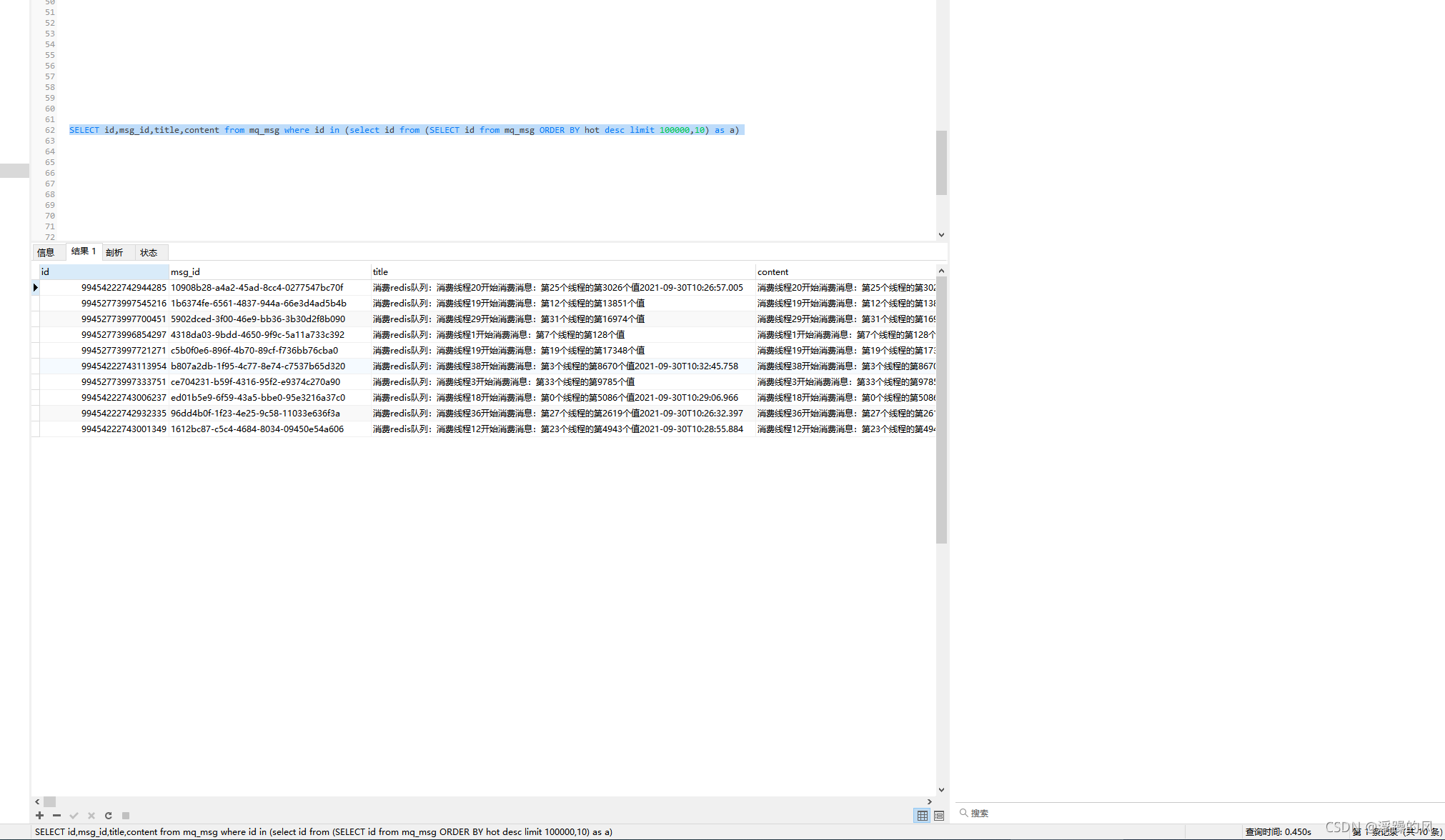
只需要0.4s左右,主要是用到了主键索引,主键索引是聚集索引,不用回表查询,索引效率很高,另外优化sql,要仔细分析explain执行计划,有时大数据量时,又不是索引覆盖时,全表扫描比走索引效率高的情况下,mysql就会放弃走索引直接全表扫描,因为走索引还要回表查询,这样效率不一定比全表扫描高
版权声明:本文为Ming13416908424原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
THE END